W pierwszej części tego bloga omówiliśmy instruktaż wdrażania MySQL InnoDB Cluster z przykładem, w jaki sposób aplikacje mogą łączyć się z klastrem za pośrednictwem dedykowanego portu do odczytu/zapisu.
W tym przewodniku po operacji pokażemy przykłady, jak monitorować, zarządzać i skalować klaster InnoDB w ramach bieżących operacji utrzymania klastra. Użyjemy tego samego klastra, który wdrożyliśmy w pierwszej części bloga. Poniższy diagram przedstawia naszą architekturę:
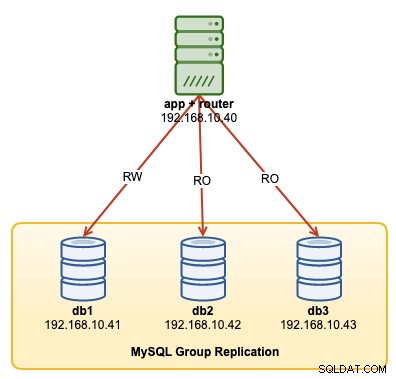
Mamy trzywęzłową replikację grup MySQL i jeden serwer aplikacji działający z Router MySQL. Wszystkie serwery działają na Ubuntu 18.04 Bionic.
Opcje poleceń klastra MySQL InnoDB
Zanim przejdziemy dalej z kilkoma przykładami i wyjaśnieniami, dobrze jest wiedzieć, że możesz uzyskać wyjaśnienie każdej funkcji w klastrze MySQL dla komponentu klastra za pomocą funkcji help(), jak pokazano poniżej:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()Poniższa lista przedstawia dostępne funkcje w MySQL Shell 8.0.18, dla MySQL Community Server 8.0.18:
- addInstance(instance[, options]) — dodaje instancję do klastra.
- checkInstanceState(instance) – weryfikuje stan identyfikatora gtid instancji w odniesieniu do klastra.
- describe()- Opisz strukturę klastra.
- disconnect()- Rozłącza wszystkie sesje wewnętrzne używane przez obiekt klastra.
- dissolve([opcje]) — dezaktywuje replikację i wyrejestrowuje zestawy replik z klastra.
- forceQuorumUsingPartitionOf(instance[, password]) — przywraca klaster po utracie kworum.
- getName() — pobiera nazwę klastra.
- pomoc([członek])- Zapewnia pomoc na temat tej klasy i jej członków
- opcje([opcje])- Wyświetla opcje konfiguracji klastra.
- rejoinInstance(instance[, options]) – ponownie dołącza instancję do klastra.
- removeInstance(instance[, options]) — usuwa instancję z klastra.
- ponowne skanowanie ([opcje]) – ponownie skanuje klaster.
- resetRecoveryAccountsPassword(opcje)- zresetuj hasło kont odzyskiwania klastra.
- setInstanceOption(instance, option, value) – zmienia wartość opcji konfiguracji w elemencie klastra.
- setOption(opcja, wartość)- Zmienia wartość opcji konfiguracji dla całego klastra.
- setPrimaryInstance(instance) — wybiera określony element klastra jako nowy podstawowy.
- status([opcje])- Opisz stan klastra.
- switchToMultiPrimaryMode() — Przełącza klaster w tryb wielu podstawowych.
- switchToSinglePrimaryMode([instance])- Przełącza klaster do trybu pojedynczego podstawowego.
Przyjrzymy się większości dostępnych funkcji, które pomogą nam monitorować, zarządzać i skalować klaster.
Monitorowanie operacji klastra MySQL InnoDB
Stan klastra
Aby sprawdzić stan klastra, najpierw użyj wiersza poleceń powłoki MySQL, a następnie połącz się jako example@sqldat.com{jeden-z-węzłów-db}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Następnie utwórz obiekt o nazwie „cluster” i zadeklaruj go jako obiekt globalny „dba”, który zapewnia dostęp do funkcji administracyjnych klastra InnoDB za pomocą AdminAPI (sprawdź dokumentację MySQL Shell API):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Następnie możemy użyć nazwy obiektu do wywołania funkcji API dla obiektu „dba”:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Wyniki są dość długie, ale możemy je odfiltrować za pomocą struktury mapy. Na przykład, jeśli chcielibyśmy wyświetlić opóźnienie replikacji tylko dla db3, moglibyśmy zrobić tak:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Należy zauważyć, że opóźnienie replikacji występuje w replikacji grupowej, w zależności od intensywności zapisu podstawowego elementu w zestawie replik i zmiennych group_replication_flow_control_*. Nie będziemy tutaj szczegółowo omawiać tego tematu. Sprawdź ten wpis na blogu, aby lepiej zrozumieć wydajność replikacji grup i kontrolę przepływu.
Inną podobną funkcją jest funkcja define(), ale ta jest nieco prostsza. Opisuje strukturę klastra, w tym wszystkie jego informacje, zestawy replik i instancje:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}Podobnie możemy filtrować dane wyjściowe JSON za pomocą struktury mapy:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryGdy główny węzeł został wyłączony (w tym przypadku jest to db1), dane wyjściowe zwróciły następujące dane:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Zwróć uwagę na stan OK_NO_TOLERANCE, gdzie klaster nadal działa, ale nie może tolerować dalszych awarii, gdy jeden z trzech węzłów nie jest dostępny. Podstawowa rola została przejęta przez db2 automatycznie, a połączenia z bazą danych z aplikacji będą przekierowywane do właściwego węzła, jeśli łączą się przez MySQL Router. Gdy db1 powróci do trybu online, powinniśmy zobaczyć następujący status:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Pokazuje, że baza danych db1 jest teraz dostępna, ale służyła jako pomocnicza z włączoną opcją tylko do odczytu. Podstawowa rola jest nadal przypisana do db2, dopóki coś nie pójdzie nie tak w węźle, gdzie zostanie automatycznie przeniesione do następnego dostępnego węzła.
Sprawdź stan instancji
Możemy sprawdzić stan węzła MySQL przed planowaniem dodania go do klastra za pomocą funkcji checkInstanceState(). Analizuje identyfikatory GTID wykonanej instancji z wykonanymi/wyczyszczonymi identyfikatorami GTID w klastrze, aby określić, czy instancja jest prawidłowa dla klastra.
Poniżej przedstawiono stan instancji db3, gdy był on w trybie autonomicznym, przed częścią klastra:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Jeśli węzeł jest już częścią klastra, powinieneś otrzymać następujące informacje:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Monitoruj dowolny stan, w którym można przeszukiwać dane
Dzięki MySQL Shell możemy teraz używać wbudowanych poleceń \show i \watch do monitorowania dowolnego zapytania administracyjnego w czasie rzeczywistym. Na przykład, możemy uzyskać w czasie rzeczywistym wartość połączonych wątków za pomocą:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Lub pobierz aktualną listę procesów MySQL:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTMożemy wtedy użyć polecenia \watch, aby uruchomić raport w taki sam sposób, jak polecenie \show, ale wyniki są odświeżane w regularnych odstępach czasu, dopóki nie anulujesz polecenia za pomocą Ctrl + C. Jak pokazano na następujące przykłady:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTDomyślny interwał odświeżania to 2 sekundy. Możesz zmienić wartość, używając flagi --interval i określając wartość od 0,1 do 86400.
Operacje zarządzania klastrami MySQL InnoDB
Przełączanie główne
Instancja podstawowa to węzeł, który można uznać za lidera w grupie replikacji, który ma możliwość wykonywania operacji odczytu i zapisu. Tylko jedna instancja podstawowa na klaster jest dozwolona w trybie topologii pojedynczej podstawowej. Ta topologia jest również znana jako zestaw replik i jest zalecanym trybem topologii dla replikacji grupowej z ochroną przed konfliktami blokowania.
Aby wykonać przełączanie instancji podstawowej, zaloguj się do jednego z węzłów bazy danych jako użytkownik klastraadmin i określ węzeł bazy danych, który chcesz promować za pomocą funkcji setPrimaryInstance():
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Właśnie promowaliśmy db1 jako nowy główny komponent, zastępując db2, podczas gdy db3 pozostaje węzłem drugorzędnym.
Zamykanie klastra
Najlepszym sposobem na bezpieczne zamknięcie klastra jest zatrzymanie najpierw usługi MySQL Router (jeśli jest uruchomiona) na serwerze aplikacji:
$ myrouter/stop.shPowyższy krok zapewnia ochronę klastra przed przypadkowymi zapisami przez aplikacje. Następnie zamknij jeden węzeł bazy danych na raz, używając standardowego polecenia zatrzymania MySQL lub wykonaj zamknięcie systemu, jak chcesz:
$ systemctl stop mysqlUruchamianie klastra po wyłączeniu
Jeśli w Twoim klastrze nastąpiła całkowita awaria lub chcesz uruchomić klaster po czystym zamknięciu, możesz upewnić się, że został poprawnie zrekonfigurowany za pomocą funkcji dba.rebootClusterFromCompleteOutage(). Po prostu przywraca klaster do trybu ONLINE, gdy wszyscy członkowie są w trybie OFFLINE. W przypadku, gdy klaster całkowicie się zatrzymał, instancje muszą zostać uruchomione i dopiero wtedy można uruchomić klaster.
Zatem upewnij się, że wszystkie serwery MySQL są uruchomione i działają. Na każdym węźle bazy danych sprawdź, czy proces mysqld jest uruchomiony:
$ ps -ef | grep -i mysqlNastępnie wybierz jeden serwer bazy danych jako główny węzeł i połącz się z nim przez powłokę MySQL:
MySQL|JS> shell.connect("example@sqldat.com:3306");Uruchom następujące polecenie z tego hosta, aby je uruchomić:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Zostaną wyświetlone następujące pytania:
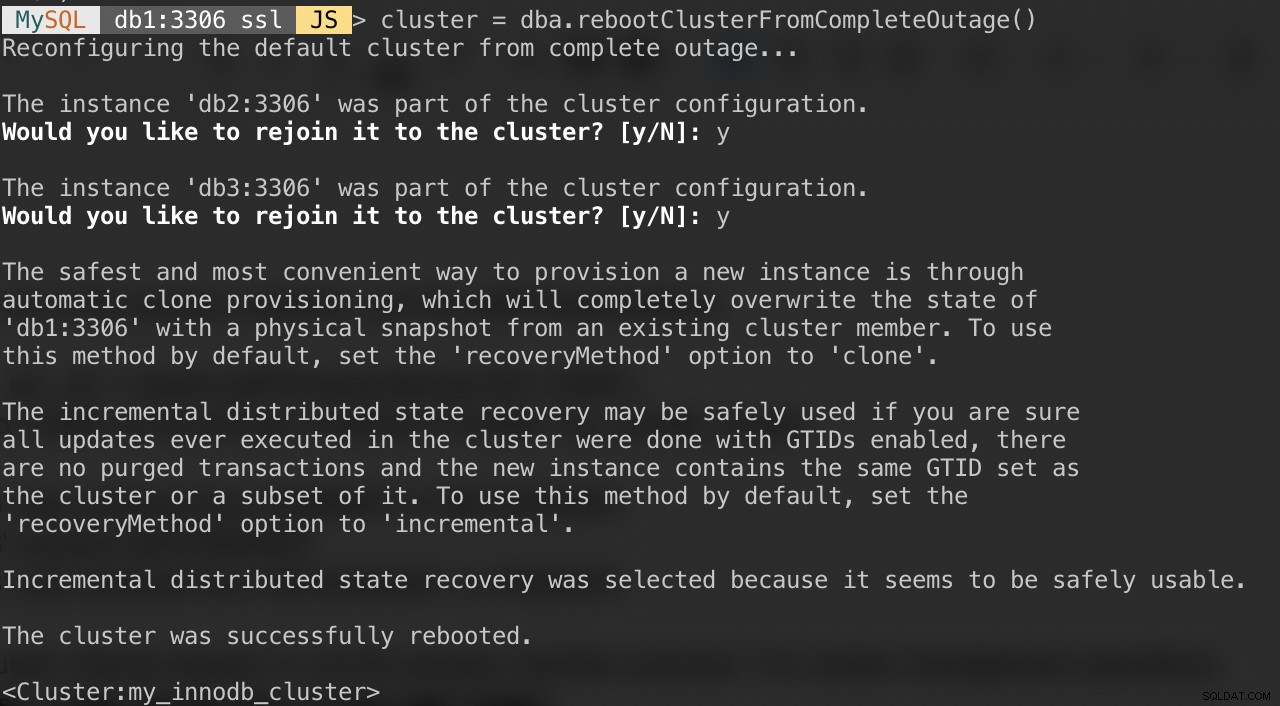
Po wykonaniu powyższych czynności możesz zweryfikować stan klastra:
MySQL|db1:3306 ssl|JS> cluster.status()W tym momencie db1 jest węzłem podstawowym i zapisującym. Reszta to członkowie drugorzędni. Jeśli chcesz uruchomić klaster z db2 lub db3 jako podstawowym, możesz użyć funkcji shell.connect(), aby połączyć się z odpowiednim węzłem i wykonać rebootClusterFromCompleteOutage() z tego konkretnego węzła.
Następnie możesz uruchomić usługę MySQL Router (jeśli nie jest uruchomiona) i pozwolić aplikacji ponownie połączyć się z klastrem.
Ustawianie opcji członka i klastra
Aby uzyskać opcje dla całego klastra, po prostu uruchom:
MySQL|db1:3306 ssl|JS> cluster.options()Powyżej wyszczególnione są globalne opcje dla zestawu replik, a także indywidualne opcje na członka w klastrze. Ta funkcja zmienia opcję konfiguracji klastra InnoDB we wszystkich elementach klastra. Obsługiwane opcje to:
- clusterName:wartość ciągu określająca nazwę klastra.
- exitStateAction:wartość ciągu wskazująca działanie stanu wyjścia replikacji grupy.
- memberWeight:wartość całkowita z procentową wagą dla automatycznych wyborów prawyborów w przypadku przełączania awaryjnego.
- failoverConsistency:wartość ciągu wskazująca spójność zapewnianą przez klaster.
- spójność: wartość ciągu wskazująca spójność zapewnianą przez klaster.
- expelTimeout:wartość całkowita określająca czas w sekundach, przez który członkowie klastra powinni czekać na nieodpowiadającego elementu przed wyrzuceniem go z klastra.
- autoRejoinTries:wartość całkowita określająca, ile razy instancja będzie próbowała ponownie dołączyć do klastra po usunięciu.
- disableClone:wartość logiczna używana do wyłączenia użycia klonu w klastrze.
Podobnie jak w przypadku innych funkcji, dane wyjściowe można filtrować w strukturze mapy. Następujące polecenie wyświetli tylko listę opcji dla db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Możesz również uzyskać powyższą listę za pomocą funkcji help():
MySQL|db1:3306 ssl|JS> cluster.help("setOption")Poniższe polecenie pokazuje przykład ustawienia opcji o nazwie MemberWeight na 60 (z 50) dla wszystkich członków:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Możemy również wykonać zarządzanie konfiguracją automatycznie przez MySQL Shell, używając funkcji setInstanceOption() i przekazując host bazy danych, odpowiednio nazwę i wartość opcji:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)Obsługiwane opcje to:
- exitStateAction: wartość ciągu wskazująca działanie stanu wyjścia replikacji grupy.
- memberWeight:wartość całkowita z procentową wagą dla automatycznych wyborów prawyborów w przypadku przełączania awaryjnego.
- autoRejoinTries:wartość całkowita określająca, ile razy instancja będzie próbowała ponownie dołączyć do klastra po usunięciu.
- oznacz identyfikator ciągu instancji.
Przełączanie na tryb Multi-Primary/Single-Primary
Domyślnie klaster InnoDB jest skonfigurowany z pojedynczym elementem podstawowym, tylko jeden element może wykonywać jednocześnie odczyty i zapisy. Jest to najbezpieczniejszy i zalecany sposób uruchamiania klastra, odpowiedni dla większości obciążeń.
Jeśli jednak logika aplikacji obsługuje rozproszone zapisy, prawdopodobnie dobrym pomysłem jest przełączenie się w tryb wielu podstawowych, w którym wszystkie elementy w klastrze mogą jednocześnie przetwarzać odczyty i zapisy. Aby przełączyć się z jednego trybu podstawowego na tryb wielu podstawowych, po prostu użyj funkcji switchToMultiPrimaryMode():
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Zweryfikuj za pomocą:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}W trybie wielu podstawowych wszystkie węzły są podstawowe i mogą przetwarzać odczyty i zapisy. Podczas wysyłania nowego połączenia przez MySQL Router na porcie pojedynczego zapisu (6446), połączenie zostanie wysłane tylko do jednego węzła, jak w tym przykładzie db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Jeśli aplikacja połączy się z portem multi-writer (6447), połączenie będzie równoważone przez algorytm round robin do wszystkich członków:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Jak widać z powyższych danych wyjściowych, wszystkie węzły mogą przetwarzać odczyty i zapisy przy read_only =OFF. Możesz dystrybuować bezpieczne zapisy do wszystkich członków, łącząc się z portem wielu zapisujących (6447), i wysyłając konflikty lub intensywne zapisy do portu pojedynczego zapisującego (6446).
Aby przełączyć się z powrotem do trybu pojedynczego podstawowego, użyj funkcji switchToSinglePrimaryMode() i określ jeden element członkowski jako węzeł podstawowy. W tym przykładzie wybraliśmy db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.W tym momencie db1 jest teraz węzłem podstawowym skonfigurowanym z wyłączoną opcją tylko do odczytu, a reszta zostanie skonfigurowana jako drugorzędna z włączoną opcją tylko do odczytu.
Operacje skalowania klastra MySQL InnoDB
Skalowanie w górę (dodawanie nowego węzła DB)
Podczas dodawania nowego wystąpienia węzeł musi być najpierw udostępniony, zanim będzie mógł uczestniczyć w grupie replikacji. Proces udostępniania będzie obsługiwany automatycznie przez MySQL. Ponadto możesz najpierw sprawdzić stan instancji, czy węzeł może dołączyć do klastra, używając funkcji checkInstanceState(), jak wyjaśniono wcześniej.
Aby dodać nowy węzeł bazy danych, użyj funkcji addInstances() i określ hosta:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Oto, co otrzymasz, dodając nową instancję:
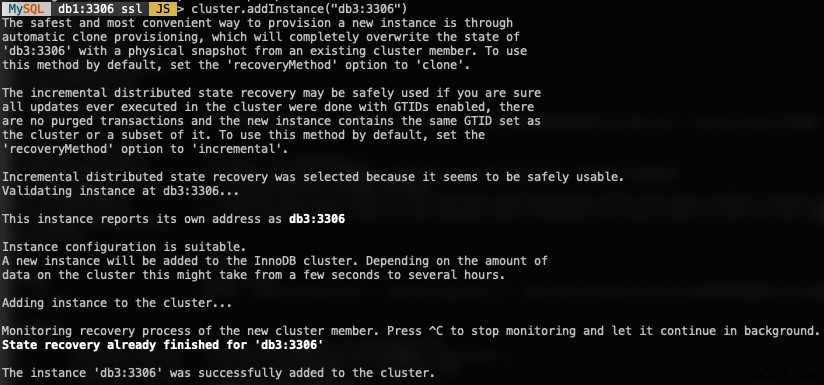
Sprawdź nowy rozmiar klastra za pomocą:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router automatycznie włączy dodany węzeł db3 do zestawu równoważenia obciążenia.
Skalowanie w dół (usuwanie węzła)
Aby usunąć węzeł, połącz się z dowolnym z węzłów bazy danych oprócz tego, który zamierzamy usunąć i użyj funkcji removeInstance() z nazwą instancji bazy danych:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Po usunięciu instancji otrzymasz następujące informacje:
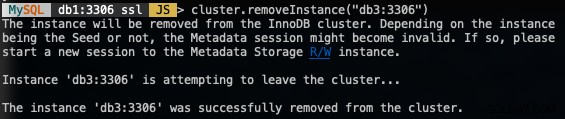
Sprawdź nowy rozmiar klastra za pomocą:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()Router MySQL automatycznie wykluczy usunięty węzeł db3 z zestawu równoważenia obciążenia.
Dodawanie nowego niewolnika replikacji
Możemy skalować klaster InnoDB za pomocą asynchronicznych replikacji podrzędnych replikacji z dowolnego węzła klastra. Urządzenie podrzędne jest luźno połączone z klastrem i będzie w stanie obsłużyć duże obciążenie bez wpływu na wydajność klastra. Urządzenie podrzędne może być również żywą kopią bazy danych do celów odzyskiwania po awarii. W trybie multi-primary można użyć urządzenia podrzędnego jako dedykowanego procesora MySQL tylko do odczytu do skalowania obciążenia odczytów, wykonywania operacji analitycznych lub jako dedykowanego serwera kopii zapasowych.
Na serwerze podrzędnym pobierz najnowszy pakiet konfiguracyjny APT, zainstaluj go (wybierz MySQL 8.0 w kreatorze konfiguracji), zainstaluj klucz APT, zaktualizuj repolist i zainstaluj serwer MySQL.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellZmodyfikuj plik konfiguracyjny MySQL, aby przygotować serwer do replikacji podrzędnej. Otwórz plik konfiguracyjny za pomocą edytora tekstu:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfI dołącz następujące wiersze:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Zrestartuj serwer MySQL na urządzeniu podrzędnym, aby zastosować zmiany:
$ systemctl restart mysqlNa jednym z serwerów klastra InnoDB (wybraliśmy db3) utwórz użytkownika podrzędnego replikacji, a następnie pełny zrzut MySQL:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlPrześlij plik zrzutu z db3 do urządzenia podrzędnego:
$ scp dump.sql example@sqldat.com:~I wykonaj przywracanie na urządzeniu podrzędnym:
$ mysql -uroot -p < dump.sqlPrzy master-data=1 nasz plik zrzutu MySQL automatycznie skonfiguruje wykonaną i wyczyszczoną wartość GTID. Możemy to zweryfikować następującym stwierdzeniem na serwerze podrzędnym po przywróceniu:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Wygląda dobrze. Następnie możemy skonfigurować łącze replikacji i uruchomić wątki replikacji na urządzeniu podrzędnym:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Zweryfikuj stan replikacji i upewnij się, że następujący stan zwraca „Tak”:
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...W tym momencie nasza architektura wygląda teraz tak:
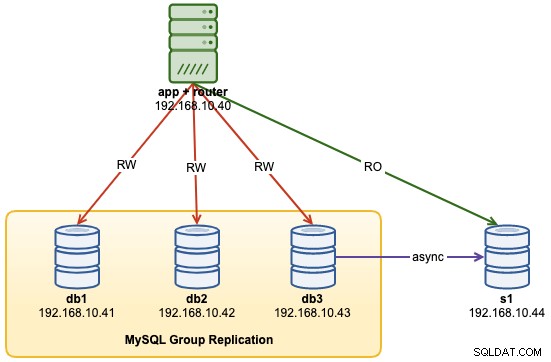
Typowe problemy z klastrami MySQL InnoDB
Wyczerpanie pamięci
Podczas korzystania z MySQL Shell z MySQL 8.0 stale otrzymywaliśmy następujący błąd, gdy instancje były skonfigurowane z 1 GB pamięci RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Uaktualnienie pamięci RAM każdego hosta do 2 GB pamięci RAM rozwiązało problem. Najwyraźniej komponenty MySQL 8.0 wymagają więcej pamięci RAM do wydajnego działania.
Utracono połączenie z serwerem MySQL
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Wnioski
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).