Klaster MySQL InnoDB składa się z 3 komponentów:
- Replikacja grupowa MySQL (grupa serwerów baz danych, które replikują się między sobą z tolerancją błędów).
- Router MySQL (router wysyłający zapytania do zdrowych węzłów bazy danych)
- MySQL Shell (pomocnik, klient, narzędzie konfiguracyjne)
W pierwszej części tego przewodnika zamierzamy wdrożyć klaster MySQL InnoDB. Istnieje wiele praktycznych samouczków dostępnych online, ale ten przewodnik obejmuje wszystkie niezbędne kroki/polecenia do zainstalowania i uruchomienia klastra w jednym miejscu. W drugiej części tego wpisu na blogu omówimy monitorowanie, zarządzanie i operacje skalowania, a także kilka problemów związanych z klastrem MySQL InnoDB.
Poniższy diagram ilustruje naszą architekturę powdrożeniową:
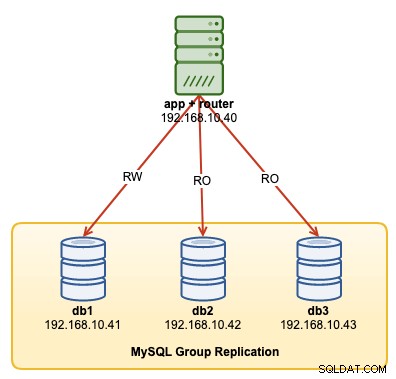
Zamierzamy wdrożyć łącznie 4 węzły; Trzywęzłowa replikacja grupowa MySQL i jeden węzeł routera MySQL zlokalizowane w obrębie serwera aplikacji. Wszystkie serwery działają na Ubuntu 18.04 Bionic.
Instalowanie MySQL
Poniższe kroki należy wykonać na wszystkich węzłach bazy danych db1, db2 i db3.
Po pierwsze, musimy wykonać mapowanie hostów. Jest to kluczowe, jeśli chcesz używać nazwy hosta jako identyfikatora hosta w klastrze InnoDB i jest to zalecany sposób. Mapuj wszystkie hosty w następujący sposób w /etc/hosts:
$ vi /etc/hosts
192.168.10.40 router apps
192.168.10.41 db1 db1.local
192.168.10.42 db2 db2.local
192.168.10.43 db3 db3.local
127.0.0.1 localhost localhost.localdomainZatrzymaj i wyłącz AppArmor:
$ service apparmor stop
$ service apparmor teardown
$ systemctl disable apparmorPobierz najnowsze repozytorium konfiguracji APT ze strony repozytorium MySQL Ubuntu pod adresem https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/ . W chwili pisania tego tekstu najnowsza jest datowana na 15 października 2019 r., czyli mysql-apt-config_0.8.14-1_all.deb:
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.debZainstaluj pakiet i skonfiguruj go dla "mysql-8.0":
$ dpkg -i mysql-apt-config_0.8.14-1_all.debZainstaluj klucz GPG:
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5Zaktualizuj ponowne polisowanie:
$ apt-get updateZainstaluj Pythona, a następnie serwer MySQL i powłokę MySQL:
$ apt-get -y install mysql-server mysql-shellZostaną wyświetlone następujące kreatory konfiguracji:
- Ustaw hasło roota — Określ silne hasło dla użytkownika root MySQL.
- Ustaw metodę uwierzytelniania — wybierz „Użyj starszej metody uwierzytelniania (zachowaj zgodność z MySQL 5.x)”
MySQL powinien zostać zainstalowany w tym momencie. Zweryfikuj za pomocą:
$ systemctl status mysqlUpewnij się, że masz stan „aktywny (działający)”.
Przygotowywanie serwera do klastra InnoDB
Poniższe kroki należy wykonać na wszystkich węzłach bazy danych db1, db2 i db3.
Skonfiguruj serwer MySQL do obsługi replikacji grupowej. Najłatwiejszym i zalecanym sposobem na to jest użycie nowej powłoki MySQL:
$ mysqlshUwierzytelnij się jako lokalny użytkownik root i postępuj zgodnie z instrukcjami kreatora konfiguracji, jak pokazano w poniższym przykładzie:
MySQL JS > dba.configureLocalInstance("example@sqldat.com:3306");Po uwierzytelnieniu powinieneś otrzymać kilka pytań, takich jak:
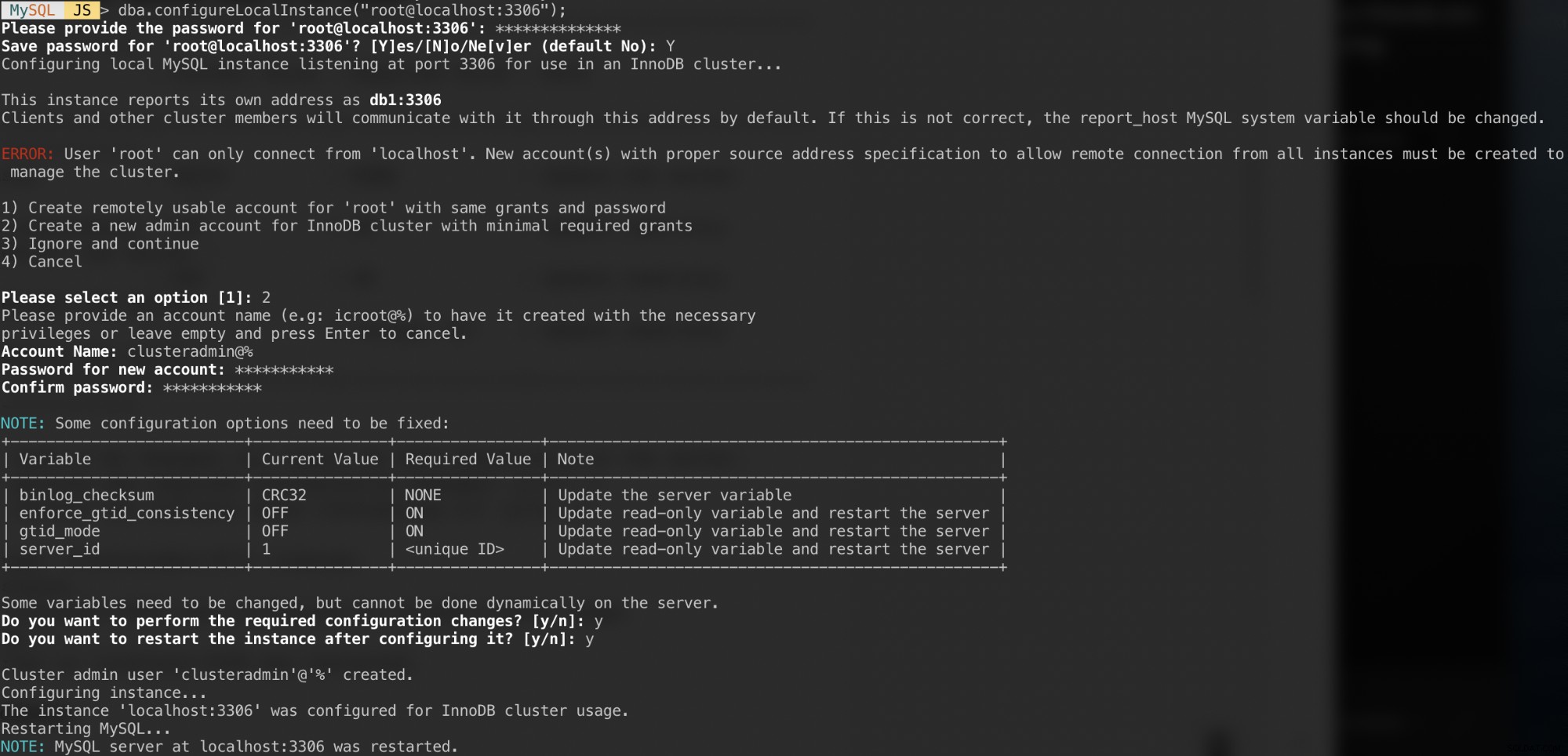
Odpowiedzi na te pytania z następującymi odpowiedziami:
- Wybierz 2 - Utwórz nowe konto administratora dla klastra InnoDB z minimalnymi wymaganymi grantami
- Nazwa konta:example@sqldat.com%
- Hasło:mys3cret&&
- Potwierdź hasło:mys3cret&&
- Czy chcesz dokonać wymaganych zmian w konfiguracji?:y
- Czy chcesz ponownie uruchomić instancję po jej skonfigurowaniu?:y
Nie zapomnij powtórzyć powyższego na wszystkich węzłach bazy danych. W tym momencie demon MySQL powinien nasłuchiwać wszystkich adresów IP, a replikacja grup jest włączona. Możemy teraz przystąpić do tworzenia klastra.
Tworzenie klastra
Teraz jesteśmy gotowi do stworzenia klastra. Na db1 połącz się jako administrator klastra z powłoki MySQL:
MySQL|JS> shell.connect('example@sqldat.com:3306');
Creating a session to 'example@sqldat.com:3306'
Please provide the password for 'example@sqldat.com:3306': ***********
Save password for 'example@sqldat.com:3306'? [Y]es/[N]o/Ne[v]er (default No): Y
Fetching schema names for autocompletion... Press ^C to stop.
Your MySQL connection id is 9
Server version: 8.0.18 MySQL Community Server - GPL
No default schema selected; type \use <schema> to set one.
<ClassicSession:example@sqldat.com:3306>Powinieneś być połączony jako example@sqldat.com (możesz to stwierdzić, patrząc na znak zachęty przed '>'). Możemy teraz utworzyć nowy klaster:
MySQL|db1:3306 ssl|JS> cluster = dba.createCluster('my_innodb_cluster');Sprawdź stan klastra:
MySQL|db1:3306 ssl|JS> cluster.status()
{
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}W tym momencie tylko db1 jest częścią klastra. Domyślnym trybem topologii jest Pojedyncza podstawowa, podobnie jak w przypadku koncepcji zestawu replik, w której tylko jeden węzeł jest jednocześnie zapisującym. Pozostałe węzły w klastrze będą czytnikami.
Zwróć uwagę na status klastra, który mówi OK_NO_TOLERANCE i dalsze wyjaśnienia pod kluczem statusText. W koncepcji zestawu replik jeden węzeł nie zapewnia odporności na uszkodzenia. Wymagane są co najmniej 3 węzły, aby zautomatyzować przełączanie awaryjne węzła podstawowego. Zajmiemy się tym później.
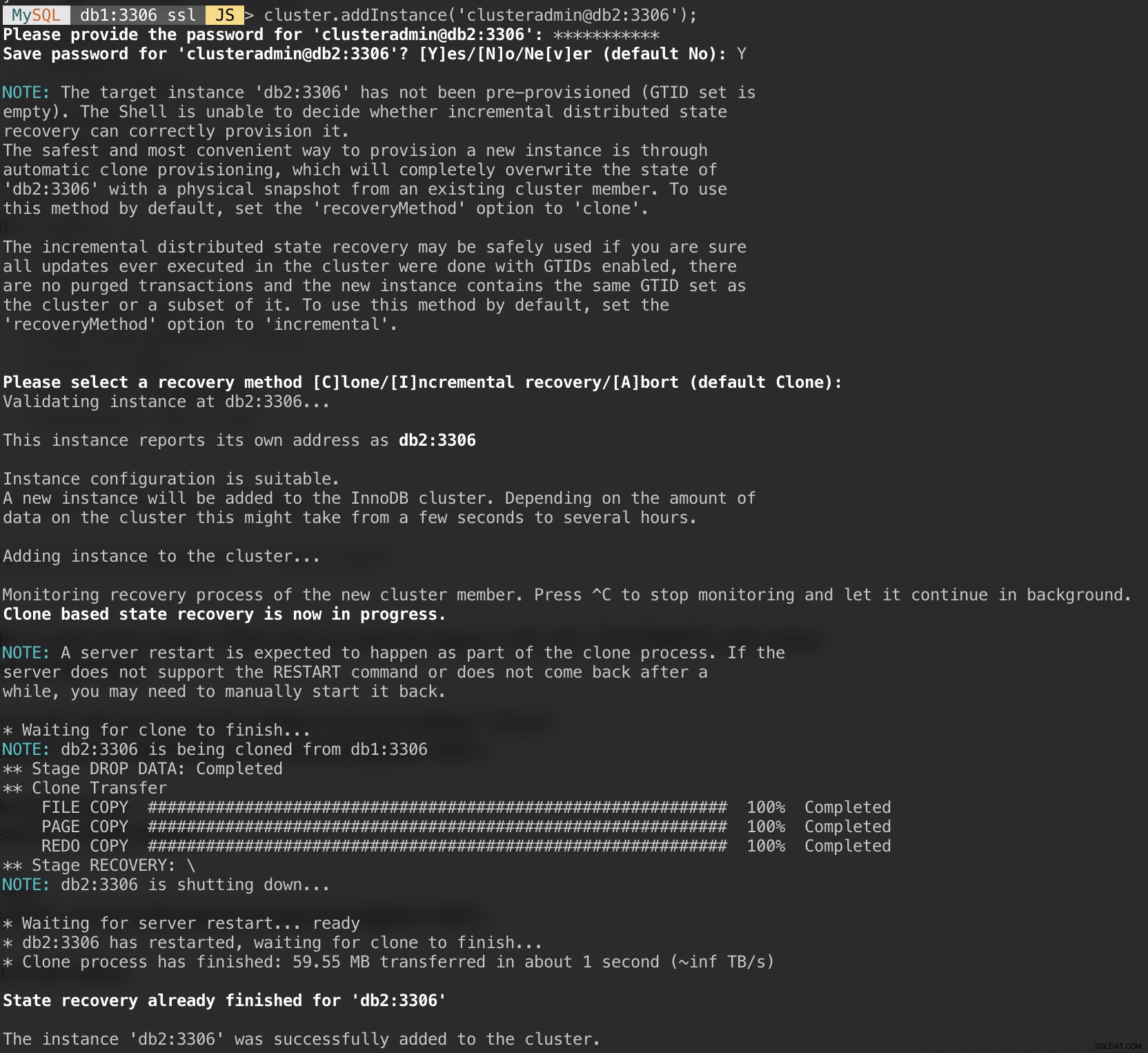
Teraz dodaj drugi węzeł db2 i zaakceptuj domyślną metodę odzyskiwania „Klon”:
MySQL|db1:3306 ssl|JS> cluster.addInstance('example@sqldat.com:3306');Poniższy zrzut ekranu przedstawia postęp inicjalizacji db2 po wykonaniu powyższego polecenia. Operacja synchronizacji jest wykonywana automatycznie przez MySQL:
Sprawdź klaster i stan db2:
MySQL|db1:3306 ssl|JS> cluster.status()
{
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}W tym momencie mamy dwa węzły w klastrze, db1 i db2. Status nadal pokazuje OK_NO_TOLERANCE z dalszym wyjaśnieniem pod wartością statusText. Jak wspomniano powyżej, replikacja grupowa MySQL wymaga co najmniej 3 węzłów w klastrze w celu zapewnienia odporności na błędy. Dlatego musimy dodać trzeci węzeł, jak pokazano dalej.
Dodaj ostatni węzeł, db3 i zaakceptuj domyślną metodę odzyskiwania „Klon”, podobną do db2:
MySQL|db1:3306 ssl|JS> cluster.addInstance('example@sqldat.com:3306');Poniższy zrzut ekranu pokazuje postęp inicjalizacji db3 po wykonaniu powyższego polecenia. Operacja synchronizacji jest wykonywana automatycznie przez MySQL:
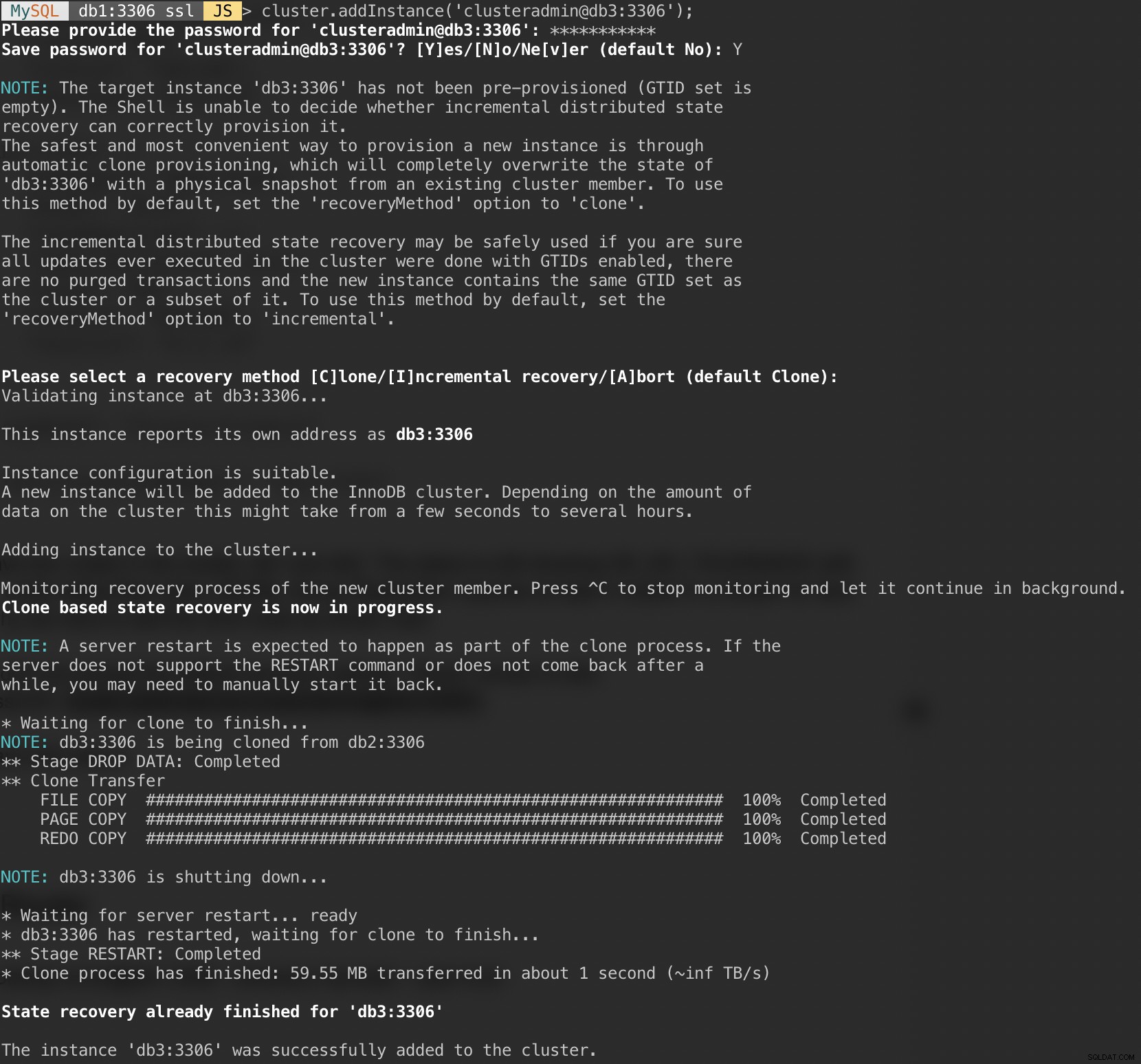
Sprawdź stan klastra i bazy danych:
MySQL|db1:3306 ssl|JS> cluster.status()
{
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Teraz klaster wygląda dobrze, gdy stan jest OK i klaster może tolerować jednocześnie do jednego węzła awarii. Podstawowym węzłem jest db1, gdzie wyświetla się „podstawowy”:„db1:3306” i „mode”:„R/W”, podczas gdy inne węzły są w stanie „R/O”. Jeśli zaznaczysz wartości read_only i super_read_only w węzłach RO, obie są wyświetlane jako prawda.
Nasze wdrożenie MySQL Group Replication zostało zakończone i zsynchronizowane.
Wdrażanie routera
Na serwerze aplikacji, na którym będziemy uruchamiać naszą aplikację, upewnij się, że mapowanie hosta jest poprawne:
$ vim /etc/hosts
192.168.10.40 router apps
192.168.10.41 db1 db1.local
192.168.10.42 db2 db2.local
192.168.10.43 db3 db3.local
127.0.0.1 localhost localhost.localdomainZatrzymaj i wyłącz AppArmor:
$ service apparmor stop
$ service apparmor teardown
$ systemctl disable apparmorNastępnie zainstaluj pakiet repozytorium MySQL, podobnie do tego, co zrobiliśmy podczas instalacji bazy danych:
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.debDodaj klucz GPG:
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5Zaktualizuj listę repozytoriów:
$ apt-get updateZainstaluj router i klienta MySQL:
$ apt-get -y install mysql-router mysql-clientMySQL Router jest teraz zainstalowany w /usr/bin/mysqlrouter. Router MySQL udostępnia flagę ładowania początkowego, aby automatycznie skonfigurować działanie routera z klastrem MySQL InnoDB. To, co musimy zrobić, to określić ciąg URI do jednego z węzłów bazy danych jako użytkownika administratora klastra InnoDB (clusteradmin).
Aby uprościć konfigurację, uruchomimy proces mysqlrouter jako użytkownik root:
$ mysqlrouter --bootstrap example@sqldat.com:3306 --directory myrouter --user=rootOto, co powinniśmy otrzymać po określeniu hasła dla użytkownika klastraadmin:
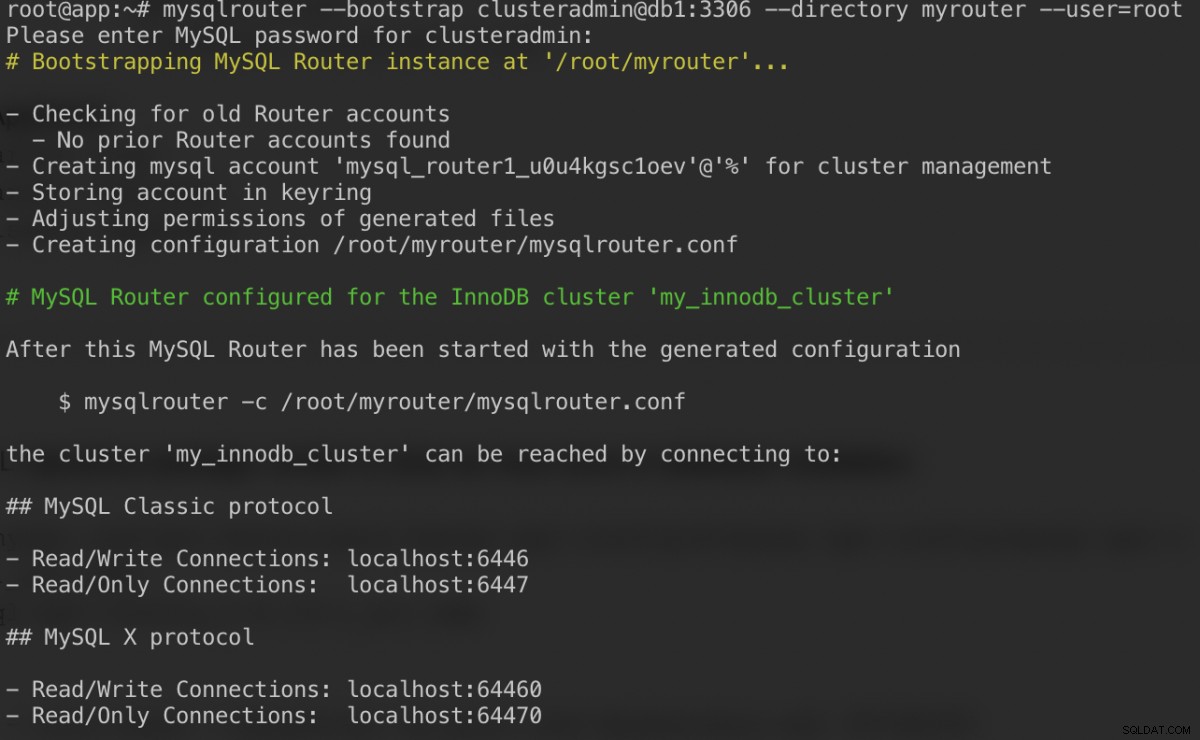
Polecenie bootstrap pomoże nam wygenerować plik konfiguracyjny routera w /root/myrouter/mysqlrouter.conf. Teraz możemy uruchomić demona mysqlrouter za pomocą następującego polecenia z bieżącego katalogu:
$ myrouter/start.shSprawdź, czy oczekiwane porty nasłuchują poprawnie:
$ netstat -tulpn | grep mysql
tcp 0 0 0.0.0.0:6446 0.0.0.0:* LISTEN 14726/mysqlrouter
tcp 0 0 0.0.0.0:6447 0.0.0.0:* LISTEN 14726/mysqlrouter
tcp 0 0 0.0.0.0:64470 0.0.0.0:* LISTEN 14726/mysqlrouter
tcp 0 0 0.0.0.0:64460 0.0.0.0:* LISTEN 14726/mysqlrouterTeraz nasza aplikacja może używać portu 6446 do odczytu/zapisu i 6447 do połączeń MySQL tylko do odczytu.
Łączenie z klastrem
Utwórzmy użytkownika bazy danych na węźle głównym. Na db1 połącz się z serwerem MySQL przez powłokę MySQL:
$ mysqlsh example@sqldat.com:3306Przełącz z trybu JavaScript na tryb SQL:
MySQL|localhost:3306 ssl|JS> \sql
Switching to SQL mode... Commands end with ;Utwórz bazę danych:
MySQL|localhost:3306 ssl|SQL> CREATE DATABASE sbtest;Utwórz użytkownika bazy danych:
MySQL|localhost:3306 ssl|SQL> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'password';Przyznaj użytkownika do bazy danych:
MySQL|localhost:3306 ssl|SQL> GRANT ALL PRIVILEGES ON sbtest.* TO example@sqldat.com'%';Teraz nasza baza danych i użytkownik są gotowe. Zainstalujmy sysbench, aby wygenerować dane testowe. Na serwerze aplikacji wykonaj:
$ apt -y install sysbench mysql-clientTeraz możemy przetestować na serwerze aplikacji, aby połączyć się z serwerem MySQL za pośrednictwem routera MySQL. Aby uzyskać połączenie do zapisu, połącz się z portem 6446 hosta routera:
$ mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select user(), @@hostname, @@read_only, @@super_read_only'
+---------------+------------+-------------+-------------------+
| user() | @@hostname | @@read_only | @@super_read_only |
+---------------+------------+-------------+-------------------+
| example@sqldat.com | db1 | 0 | 0 |
+---------------+------------+-------------+-------------------+W przypadku połączenia tylko do odczytu połącz się z portem 6447 hosta routera:
$ mysql -usbtest -p -h192.168.10.40 -P6447 -e 'select user(), @@hostname, @@read_only, @@super_read_only'
+---------------+------------+-------------+-------------------+
| user() | @@hostname | @@read_only | @@super_read_only |
+---------------+------------+-------------+-------------------+
| example@sqldat.com | db3 | 1 | 1 |
+---------------+------------+-------------+-------------------+Wygląda dobrze. Możemy teraz wygenerować niektóre dane testowe za pomocą sysbench. Na serwerze aplikacji wygeneruj 20 tabel z 100 000 wierszy na tabelę, łącząc się z portem 6446 serwera aplikacji:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--mysql-port=6446 \
--mysql-host=192.168.10.40 \
--tables=20 \
--table-size=100000 \
prepare
Aby wykonać prosty test odczytu i zapisu na porcie 6446 przez 300 sekund, uruchom:
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=8 \
--time=300 \
--db-driver=mysql \
--mysql-host=192.168.10.40 \
--mysql-port=6446 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runW przypadku obciążeń tylko do odczytu możemy wysłać połączenie MySQL na port 6447:
$ sysbench \
/usr/share/sysbench/oltp_read_only.lua \
--report-interval=2 \
--threads=1 \
--time=300 \
--db-driver=mysql \
--mysql-host=192.168.10.40 \
--mysql-port=6447 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runWniosek
To wszystko. Nasza konfiguracja klastra MySQL InnoDB jest już kompletna, a wszystkie jego komponenty są uruchomione i przetestowane. W drugiej części przyjrzymy się zarządzaniu, monitorowaniu i skalowaniu działania klastra, a także rozwiązywaniu wielu typowych problemów podczas pracy z klastrem MySQL InnoDB. Bądź na bieżąco!