W dzisiejszych czasach dość powszechne jest replikowanie bazy danych na innym serwerze/centrum danych, a w niektórych przypadkach jest to również konieczne. Istnieją różne powody, dla których warto replikować bazy danych w całkowicie oddzielnym środowisku.
- Przeprowadź migrację do innego centrum danych.
- Wymagania dotyczące aktualizacji (sprzętu/oprogramowania).
- Utrzymuj w pełni zsynchronizowany system operacyjny w witrynie odzyskiwania po awarii (DR), która może przejąć kontrolę w dowolnym momencie
- Utrzymuj bazę danych podrzędnych jako część tańszego planu DR.
- Wymagania dotyczące geolokalizacji (dane muszą znajdować się lokalnie w określonym kraju).
- Miej środowisko testowe.
- Cel rozwiązywania problemów.
- Baza danych raportów.
Istnieją różne sposoby wykonania tego zadania replikacji:
- Kopia zapasowa/przywracanie :Tworzenie kopii zapasowej produkcyjnej bazy danych i przywracanie jej na nowym serwerze/środowisku to klasyczny sposób na zrobienie tego, ale jest to również staromodny sposób, ponieważ nie będziesz aktualizować swoich danych i musisz poczekać dla każdego procesu przywracania, jeśli potrzebujesz ostatnich danych. Jeśli masz klaster (master-slave, multi-master) i chcesz go odtworzyć, powinieneś przywrócić początkową kopię zapasową, a następnie odtworzyć pozostałe węzły, co może być czasochłonnym zadaniem.
- Klonuj klaster :Jest podobny do poprzedniego, ale proces tworzenia kopii zapasowych i przywracania dotyczy całego klastra, a nie tylko jednego konkretnego serwera bazy danych. W ten sposób możesz sklonować cały klaster w tym samym zadaniu i nie musisz ręcznie odtwarzać pozostałych węzłów. Ta metoda nadal ma problem z aktualizacją danych między klonami.
- Replikacja :W ten sposób dostępna jest opcja tworzenia kopii zapasowej/przywracania, ale po początkowym przywróceniu proces replikacji zachowa synchronizację danych z węzłem głównym. W ten sposób, jeśli masz klaster bazy danych, musisz przywrócić kopię zapasową do jednego węzła i ręcznie odtworzyć wszystkie węzły.
W tym blogu zobaczymy nową funkcję ClusterControl 1.7.4, która pozwala na użycie kombinacji wspomnianych wcześniej metod w celu usprawnienia tego zadania.
Co to jest replikacja z klastra do klastra?
Replikacja między dwoma klastrami to nie to samo, co rozszerzenie klastra na dwa centra danych. Konfigurując replikację między dwoma klastrami, w rzeczywistości mamy 2 oddzielne systemy, które mogą działać autonomicznie. Replikacja służy do ich synchronizacji, dzięki czemu system podrzędny ma zaktualizowany stan i może przejąć kontrolę.
W ClusterControl 1.7.4 możliwe jest utworzenie nowego klastra przez bezpośrednie klonowanie działającego klastra źródłowego lub przy użyciu ostatniej kopii zapasowej klastra źródłowego.
Po sklonowaniu klastra będziesz miał klaster podrzędny (SC) odbierający dane, a klaster główny (MC) wysyłający zmiany do klastra podrzędnego.
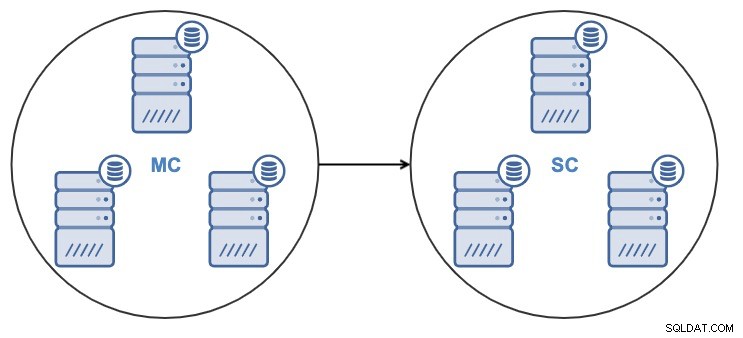
ClusterControl obsługuje replikację klastrów do klastrów dla następujących typów klastrów:
- Klaster Percona XtraDB w wersji 5.6.x i nowszych.
- MariaDB Galera Cluster w wersji 10.x i nowszych.
- PostgreSQL 9.6 i nowsze.
Replikacja między klastrami dla klastra Percona XtraDB / MariaDB Galera
W przypadku silników opartych na MySQL do korzystania z tej funkcji wymagany jest identyfikator GTID i zostanie zastosowana replikacja asynchroniczna między klastrem Master i Slave.
W celu przygotowania bieżącego klastra do tego zadania należy wykonać kilka czynności. Po pierwsze, co najmniej jeden węzeł w bieżącym klastrze musi mieć włączone dzienniki binarne. Następnie należy dodać użytkownika kopii zapasowej skonfigurowanego w węźle bazy danych w pliku konfiguracyjnym ClusterControl, który będzie używany do zadań zarządzania. Wszystkie te czynności można wykonać za pomocą interfejsu użytkownika ClusterControl lub interfejsu ClusterControl CLI.
Teraz jesteś gotowy do tworzenia replikacji z klastra do klastra Percona XtraDB/MariaDB Galera. Po zakończeniu pracy będziesz miał:
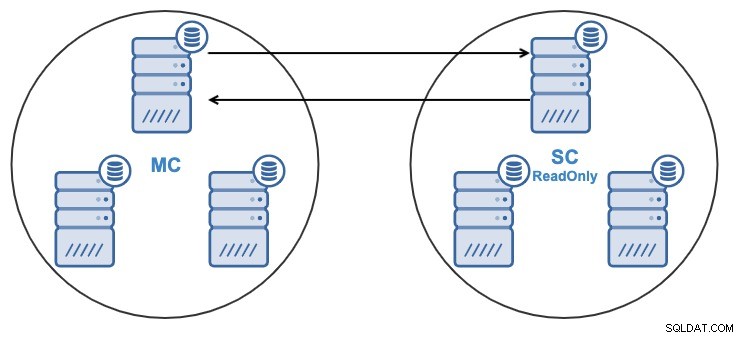
- Jeden węzeł w klastrze podrzędnym będzie replikował się z jednego węzła w klastrze głównym.
- Replikacja będzie dwukierunkowa między klastrami.
- Wszystkie węzły w Klastrze Slave będą domyślnie tylko do odczytu. Możliwe jest wyłączenie flagi tylko do odczytu na węzłach jeden po drugim.
- Klastrowanie w trybie Active-Active jest zalecane tylko wtedy, gdy aplikacje dotykają tylko rozłącznych zestawów danych na jednym z klastrów, ponieważ silnik nie oferuje wykrywania ani rozwiązywania konfliktów.
Za pomocą interfejsu użytkownika ClusterControl lub interfejsu ClusterControl będziesz mógł:
- Utwórz ten klaster replikacji.
- Włącz konfigurację aktywny-aktywny.
- Zmień topologię klastra.
- Odbuduj klaster replikacji.
- Zatrzymaj/uruchom serwer replikacji.
- Zresetuj urządzenie podrzędne replikacji (zaimplementowane tylko przy użyciu ClusterControl CLI atm).
Rozważania
- Użytkownik kopii zapasowej musi zostać dodany ręcznie w pliku konfiguracyjnym ClusterControl.
- Poświadczenia użytkownika kopii zapasowej muszą być takie same w bieżącym i nowym klastrze.
- Hasło roota MySQL określone podczas tworzenia klastra podrzędnego musi być takie samo jak hasło roota używane w klastrze głównym.
Znane ograniczenia
- Automatyczne przełączanie awaryjne nie jest jeszcze obsługiwane. Jeśli master ulegnie awarii, administrator jest odpowiedzialny za przełączenie awaryjne na inny master.
- Możliwe jest tylko „zresetowanie” urządzenia podrzędnego replikacji z interfejsu ClusterControl CLI, ponieważ nie zostało ono jeszcze zaimplementowane w interfejsie użytkownika ClusterControl.
- Odbudowa klastra jest możliwa tylko w trybie tylko do odczytu. Wszystkie węzły w klastrze muszą być tylko do odczytu, aby były liczone jako klaster tylko do odczytu.
Replikacja między klastrami dla PostgreSQL
ClusterControl Cluster-to-Cluster Replication jest obsługiwana w PostgreSQL przy użyciu replikacji strumieniowej.
Wymaganiem musi być serwer PostgreSQL z rolą ClusterControl „master”, a kiedy konfigurujesz klaster Slave, poświadczenia administratora muszą być takie same jak w przypadku klastra głównego.
Teraz jesteś gotowy do tworzenia replikacji PostgreSQL Cluster-to-Cluster. Po zakończeniu pracy będziesz miał:
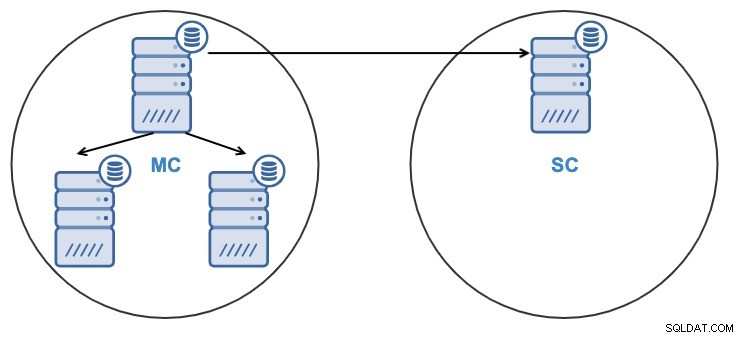
- Jeden węzeł w klastrze podrzędnym będzie replikował się z jednego węzła w klastrze głównym.
- Replikacja będzie jednokierunkowa między klastrami.
- Węzeł w klastrze podrzędnym będzie tylko do odczytu.
Za pomocą interfejsu ClusterControl UI lub ClusterControl CLI będziesz mógł:
- Utwórz ten klaster replikacji.
- Odbuduj klaster replikacji.
- Zatrzymaj/uruchom serwer replikacji.
Rozważanie
- Poświadczenia administratora muszą być identyczne w klastrze nadrzędnym i podrzędnym.
Znane ograniczenia
- Maksymalny rozmiar klastra podrzędnego to jeden węzeł.
- Klaster Slave nie może być udostępniony z kopii zapasowej.
- Zmiany topologii nie są obsługiwane.
- Obsługiwana jest tylko replikacja jednokierunkowa.
Wnioski
Korzystając z tej nowej funkcji ClusterControl, nie musisz wykonywać każdego kroku, aby utworzyć replikację klastra oddzielnie lub ręcznie, a dzięki temu zaoszczędzisz czas i wysiłek. Spróbuj!