W idealnym świecie nie miałoby znaczenia, jaką konkretną składnię T-SQL wybraliśmy do wyrażenia zapytania. Każda semantycznie identyczna konstrukcja prowadziłaby do dokładnie tego samego fizycznego planu wykonania, z dokładnie tymi samymi parametrami wydajności.
Aby to osiągnąć, optymalizator zapytań SQL Server musiałby znać każdą możliwą równoważność logiczną (zakładając, że kiedykolwiek moglibyśmy poznać je wszystkie) oraz mieć czas i zasoby na zbadanie wszystkich opcji. Biorąc pod uwagę ogromną liczbę możliwych sposobów wyrażenia tego samego wymagania w T-SQL i ogromną liczbę możliwych przekształceń, kombinacje szybko stają się niemożliwe do zarządzania we wszystkich, z wyjątkiem najprostszych przypadków.
„Doskonały świat” z całkowitą niezależnością od składni może nie wydawać się aż tak doskonały dla użytkowników, którzy muszą czekać dni, tygodnie, a nawet lata na skompilowanie umiarkowanie złożonego zapytania. Tak więc optymalizator zapytań idzie na kompromis:bada niektóre typowe równoważności i stara się nie spędzać więcej czasu na kompilacji i optymalizacji niż oszczędza na czasie wykonywania. Jego cel można podsumować jako próbę znalezienia rozsądnego planu wykonania w rozsądnym czasie, przy jednoczesnym zużyciu rozsądnych zasobów.
Jednym z rezultatów tego wszystkiego jest to, że plany wykonania są często wrażliwe na pisemną formę zapytania. Optymalizator ma pewną logikę, aby szybko przekształcić niektóre powszechnie używane równoważne konstrukcje w powszechną formę, ale te zdolności nie są ani dobrze udokumentowane, ani (w przybliżeniu) wszechstronne.
Z pewnością możemy zmaksymalizować nasze szanse na uzyskanie dobrego planu wykonania, pisząc prostsze zapytania, dostarczając przydatne indeksy, utrzymując dobre statystyki i ograniczając się do bardziej relacyjnych pojęć (np. unikając kursorów, jawnych pętli i funkcji innych niż wbudowane), ale jest to nie kompletne rozwiązanie. Nie można też powiedzieć, że jedna konstrukcja T-SQL będzie zawsze stworzyć lepszy plan wykonania niż semantycznie identyczna alternatywa.
Moja zwykła rada to zacząć od najprostszego relacyjnego formularza zapytania, który spełnia Twoje potrzeby, używając dowolnej składni T-SQL, którą uznasz za preferowaną. Jeśli zapytanie nie spełnia wymagań po fizycznej optymalizacji (np. indeksowaniu), warto spróbować wyrazić zapytanie w nieco inny sposób, zachowując oryginalną semantykę. To jest trudna część. Którą część zapytania powinieneś spróbować przepisać? Które przepisać powinieneś spróbować? Nie ma prostej, uniwersalnej odpowiedzi na te pytania. Część z nich sprowadza się do doświadczenia, chociaż wiedza na temat optymalizacji zapytań i wewnętrznych mechanizmów silnika wykonawczego może być również przydatnym przewodnikiem.
Przykład
W tym przykładzie użyto tabeli AdventureWorks TransactionHistory. Poniższy skrypt tworzy kopię tabeli i tworzy indeks klastrowy i nieklastrowy. W ogóle nie będziemy modyfikować danych; ten krok ma na celu wyjaśnienie indeksowania (i nadanie tabeli krótszej nazwy):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Zadanie polega na stworzeniu listy identyfikatorów produktów i historii dla sześciu poszczególnych produktów. Jednym ze sposobów wyrażenia zapytania jest:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
To zapytanie zwraca 764 wiersze przy użyciu następującego planu wykonania (pokazanego w SentryOne Plan Explorer):

To proste zapytanie kwalifikuje się do kompilacji planu TRIVIAL. Plan wykonania zawiera sześć oddzielnych operacji wyszukiwania indeksu w jednym:
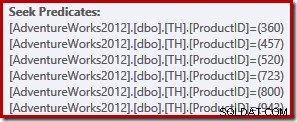
Czytelnicy o orlim wzroku zauważą, że sześć poszukiwań jest wymienionych w rosnąco kolejność identyfikatorów produktów, która nie jest w (dowolnej) kolejności określonej na liście IN oryginalnego zapytania. Rzeczywiście, jeśli sam uruchomisz zapytanie, prawdopodobnie zaobserwujesz zwracane wyniki w rosnącej kolejności identyfikatorów produktów. Zapytanie nie jest gwarantowane oczywiście zwracać wyniki w tej kolejności, ponieważ nie określiliśmy klauzuli ORDER BY najwyższego poziomu. Możemy jednak dodać taką klauzulę ORDER BY, bez zmiany planu wykonania tworzonego w tym przypadku:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Nie będę powtarzał grafiki planu wykonania, bo jest dokładnie taki sam:zapytanie nadal kwalifikuje się do trywialnego planu, operacje wyszukiwania są dokładnie takie same, a oba plany mają dokładnie taki sam szacunkowy koszt. Dodanie klauzuli ORDER BY nic nas nie kosztowało, ale dało nam gwarancję uporządkowania zestawu wyników.
Mamy teraz gwarancję, że wyniki zostaną zwrócone w kolejności według identyfikatora produktu, ale nasze zapytanie nie określa obecnie, w jaki sposób wiersze z takim samym identyfikator produktu zostanie zamówiony. Patrząc na wyniki, możesz zauważyć, że wiersze dla tego samego identyfikatora produktu wydają się być uporządkowane według identyfikatora transakcji, rosnąco.
Bez wyraźnego ORDER BY jest to tylko kolejna obserwacja (tzn. nie możemy polegać na tej kolejności), ale możemy zmodyfikować zapytanie, aby upewnić się, że wiersze są uporządkowane według identyfikatora transakcji w ramach każdego identyfikatora produktu:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Ponownie, plan wykonania dla tego zapytania jest dokładnie taki sam jak poprzednio; powstaje ten sam trywialny plan z tymi samymi szacunkowymi kosztami. Różnica polega na tym, że wyniki są teraz gwarantowane do zamówienia najpierw według identyfikatora produktu, a następnie według identyfikatora transakcji.
Niektórzy mogą pokusić się o stwierdzenie, że dwa poprzednie zapytania również zawsze zwracają wiersze w tej kolejności, ponieważ plany wykonania są takie same. Nie jest to bezpieczna implikacja, ponieważ nie wszystkie szczegóły silnika wykonawczego są ujawniane w planach wykonawczych (nawet w postaci XML). Bez wyraźnej klauzuli order by SQL Server może zwracać wiersze w dowolnej kolejności, nawet jeśli plan wygląda tak samo dla nas (może na przykład wykonać wyszukiwania w kolejności określonej w tekście zapytania). Chodzi o to, że optymalizator zapytań wie i może wymusić pewne zachowania w silniku, które nie są widoczne dla użytkowników.
Jeśli zastanawiasz się, w jaki sposób nasz nieunikalny nieklastrowany indeks w identyfikatorze produktu może zwracać wiersze w produktach i Kolejność identyfikatorów transakcji, odpowiedź brzmi, że klucz indeksu nieklastrowego zawiera identyfikator transakcji (unikalny klucz indeksu klastrowego). W rzeczywistości fizyczny struktura naszego indeksu nieklastrowego jest dokładnie tak samo, na wszystkich poziomach, tak jakbyśmy stworzyli indeks z następującą definicją:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Możemy nawet napisać zapytanie z wyraźnym DISTINCT lub GROUP BY i nadal uzyskać dokładnie ten sam plan wykonania:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Żeby było jasne, nie wymaga to w żaden sposób zmiany oryginalnego indeksu nieklastrowanego. Jako ostatni przykład zwróć uwagę, że możemy również zażądać wyników w kolejności malejącej:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Właściwości planu wykonania pokazują teraz, że indeks jest skanowany wstecz:

Poza tym plan jest taki sam – został wyprodukowany na etapie optymalizacji planu trywialnego i nadal ma ten sam szacunkowy koszt.
Przepisywanie zapytania
Nie ma nic złego w poprzednim zapytaniu lub planie wykonania, ale być może zdecydowaliśmy się na inne wyrażenie zapytania:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Oczywiście ta forma określa dokładnie te same wyniki, co oryginał, i rzeczywiście nowe zapytanie daje ten sam plan wykonania (plan trywialny, wielokrotne wyszukiwanie w jednym, ten sam szacunkowy koszt). Formularz OR może nieco bardziej wyjaśniać, że wynik jest kombinacją wyników dla sześciu indywidualnych identyfikatorów produktów, co może skłonić nas do wypróbowania innej odmiany, która jeszcze bardziej uwypukli ten pomysł:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Plan wykonania zapytania UNION ALL jest zupełnie inny:
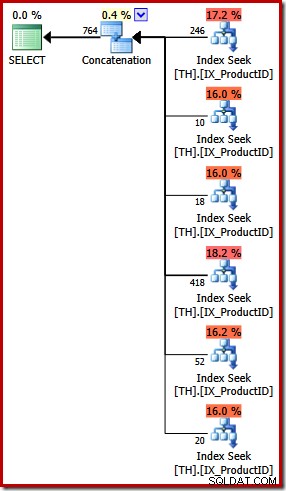
Poza oczywistymi różnicami wizualnymi, plan ten wymagał optymalizacji opartej na kosztach (FULL) (nie kwalifikował się do planu trywialnego), a szacowany koszt jest (relatywnie rzecz biorąc) nieco wyższy, około 0,02 jednostki w porównaniu z około 0,005 jednostki przed.
Wracamy do moich początkowych uwag:optymalizator zapytań nie wie o każdej logicznej równoważności i nie zawsze może rozpoznać alternatywne zapytania jako określające te same wyniki. Chodzi mi o to, że na tym etapie wyrażenie tego konkretnego zapytania za pomocą UNION ALL zamiast IN spowodowało mniej optymalny plan wykonania.
Drugi przykład
Ten przykład wybiera inny zestaw sześciu identyfikatorów produktów, a żądania skutkują kolejnością identyfikatorów transakcji:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Nasz indeks nieklastrowy nie może dostarczyć wierszy w żądanej kolejności, więc optymalizator zapytań ma wybór między wyszukiwaniem indeksu nieklastrowego a sortowaniem lub skanowaniem indeksu klastrowego (który jest oparty na samym identyfikatorze transakcji) i zastosowaniem predykatów identyfikatora produktu jako pozostałość. Wymienione identyfikatory produktów mają niższą selektywność niż poprzedni zestaw, więc optymalizator wybiera w tym przypadku skanowanie indeksu klastrowego:
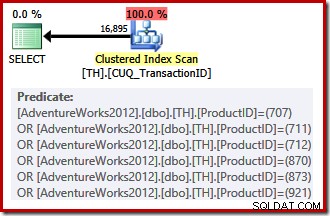
Ponieważ istnieje wybór oparty na kosztach, ten plan wykonania nie kwalifikował się do planu trywialnego. Szacowany koszt ostatecznego planu to około 0,714 jednostki. Skanowanie indeksu klastrowego wymaga 797 odczyty logiczne w czasie wykonywania.
Być może zdziwieni, że zapytanie nie używa indeksu produktu, możemy spróbować wymusić wyszukiwanie indeksu nieklastrowanego za pomocą wskazówki dotyczącej indeksu lub określając FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
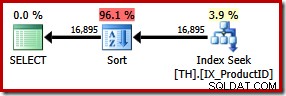
Powoduje to jawne sortowanie według identyfikatora transakcji. Szacuje się, że nowy rodzaj stanowi 96% 1,15 nowego planu Cena jednostkowa. Ten wyższy szacowany koszt wyjaśnia, dlaczego optymalizator wybrał pozornie tańsze skanowanie indeksu klastrowego, gdy pozostawiono go własnym urządzeniom. Koszt we/wy nowego zapytania jest jednak niższy:po wykonaniu wyszukiwanie indeksu zużywa tylko 49 odczyty logiczne (od 797).
Mogliśmy również zdecydować się na wyrażenie tego zapytania za pomocą (poprzednio nieudanego) pomysłu UNION ALL:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Daje następujący plan wykonania (kliknij na obrazek, aby powiększyć w nowym oknie):

Ten plan może wydawać się bardziej złożony, ale jego szacowany koszt to tylko 0,099 jednostek, co jest znacznie niższe niż w przypadku skanowania indeksu klastrowego (0,714 jednostek) lub szukaj plus sortuj (1,15 jednostek). Ponadto nowy plan zużywa tylko 49 odczyty logiczne w czasie wykonywania – to samo, co plan wyszukiwania + sortowania i znacznie niższe niż 797 potrzebne do skanowania indeksu klastrowego.
Tym razem wyrażenie zapytania za pomocą UNION ALL dało znacznie lepszy plan, zarówno pod względem szacowanego kosztu, jak i odczytów logicznych. Zestaw danych źródłowych jest trochę za mały, aby dokonać naprawdę sensownego porównania między czasami trwania zapytań lub wykorzystaniem procesora, ale skanowanie indeksu klastrowego trwa dwa razy dłużej (26 ms) niż pozostałe dwa w moim systemie.
Dodatkowe sortowanie w podpowiedzianym planie jest prawdopodobnie nieszkodliwe w tym prostym przykładzie, ponieważ jest mało prawdopodobne, aby rozlało się na dysk, ale wiele osób i tak woli plan UNION ALL, ponieważ nie blokuje, unika przyznawania pamięci i nie wymaga wskazówka zapytania.
Wniosek
Widzieliśmy, że składnia zapytania może wpływać na plan wykonania wybrany przez optymalizator, mimo że zapytania logicznie określają dokładnie ten sam zestaw wyników. To samo przepisanie (np. UNION ALL) czasami spowoduje poprawę, a czasami spowoduje wybór gorszego planu.
Przepisywanie zapytań i próbowanie alternatywnej składni to prawidłowa technika dostrajania, ale należy zachować ostrożność. Jednym z zagrożeń jest to, że przyszłe zmiany w produkcie mogą spowodować, że inny formularz zapytania nagle przestanie tworzyć lepszy plan, ale można argumentować, że zawsze jest to ryzyko i jest łagodzone przez testy przed uaktualnieniem lub korzystanie z przewodników po planach.
Istnieje również ryzyko, że ta technika da się ponieść emocjom:stosowanie „dziwnych” lub „nietypowych” konstrukcji zapytań w celu uzyskania lepszego planu jest często oznaką przekroczenia linii. Dokładnie tam, gdzie rozróżnienie między prawidłową alternatywną składnią a „niezwykłą/dziwną” jest prawdopodobnie dość subiektywne; moim osobistym przewodnikiem jest praca z równoważnymi relacyjnymi formularzami zapytań i zachowanie jak największej prostoty.