W poprzednim poście wyjaśniłem, jak wykonać logiczną kopię zapasową za pomocą narzędzi powłoki mysql. W tym poście porównamy szybkość procesu tworzenia kopii zapasowej i przywracania.
Test szybkości powłoki MySQL
Zamierzamy dokonać porównania szybkości tworzenia i odzyskiwania kopii zapasowych narzędzi mysqldump i powłoki MySQL.
Poniższe narzędzia służą do porównywania prędkości:
- mysqldump
- util.dumpInstance
- util.loadDump
Konfiguracja sprzętu
Dwa samodzielne serwery o identycznych konfiguracjach.
Serwer 1
* IP:192.168.33.14
* Procesor:2 rdzenie
* RAM:4 GB
* DYSK:200 GB SSD
Serwer 2
* IP:192.168.33.15
* Procesor:2 rdzenie
* RAM:4 GB
* DYSK:200 GB SSD
Przygotowanie zadań
Na serwerze 1 (192.168.33.14) załadowaliśmy około 10 GB danych.
Teraz chcemy przywrócić dane z serwera 1 (192.168.33.14) na serwer 2 (192.168.33.15).
Konfiguracja MySQL
Wersja MySQL:8.0.22
Rozmiar puli buforów InnoDB:1 GB
Rozmiar pliku dziennika InnoDB:16 MB
Logowanie binarne:włączone
Załadowaliśmy 50 mln rekordów za pomocą sysbench.
[example@sqldat.com sysbench]# sysbench oltp_insert.lua --table-size=5000000 --num-threads=8 --rand-type=uniform --db-driver=mysql --mysql-db=sbtest --tables=10 --mysql-user=root --mysql-password=****** prepare
WARNING: --num-threads is deprecated, use --threads instead
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Initializing worker threads...
Creating table 'sbtest3'...
Creating table 'sbtest4'...
Creating table 'sbtest7'...
Creating table 'sbtest1'...
Creating table 'sbtest2'...
Creating table 'sbtest8'...
Creating table 'sbtest5'...
Creating table 'sbtest6'...
Inserting 5000000 records into 'sbtest1'
Inserting 5000000 records into 'sbtest3'
Inserting 5000000 records into 'sbtest7
.
.
.
Creating a secondary index on 'sbtest9'...
Creating a secondary index on 'sbtest10'...Przypadek testowy pierwszy
W tym przypadku zrobimy logiczną kopię zapasową za pomocą polecenia mysqldump.
Przykład
[example@sqldat.com vagrant]# time /usr/bin/mysqldump --defaults-file=/etc/my.cnf --flush-privileges --hex-blob --opt --master-data=2 --single-transaction --triggers --routines --events --set-gtid-purged=OFF --all-databases |gzip -6 -c > /home/vagrant/test/mysqldump_schemaanddata.sql.gzstart_time =2020-11-09 17:40:02
end_time =09.11.2020 37:19:08
Wykonanie zrzutu wszystkich baz danych o łącznym rozmiarze około 10 GB zajęło prawie 20 minut i 19 sekund.
Przypadek testowy drugi
Teraz spróbujmy z narzędziem powłoki MySQL. Użyjemy dumpInstance, aby wykonać pełną kopię zapasową.
Przykład
MySQL localhost:33060+ ssl JS > util.dumpInstance("/home/vagrant/production_backup", {threads: 2, ocimds: true,compatibility: ["strip_restricted_grants"]})
Acquiring global read lock
Global read lock acquired
All transactions have been started
Locking instance for backup
Global read lock has been released
Checking for compatibility with MySQL Database Service 8.0.22
NOTE: Progress information uses estimated values and may not be accurate.
Data dump for table `sbtest`.`sbtest1` will be written to 38 files
Data dump for table `sbtest`.`sbtest10` will be written to 38 files
Data dump for table `sbtest`.`sbtest3` will be written to 38 files
Data dump for table `sbtest`.`sbtest2` will be written to 38 files
Data dump for table `sbtest`.`sbtest4` will be written to 38 files
Data dump for table `sbtest`.`sbtest5` will be written to 38 files
Data dump for table `sbtest`.`sbtest6` will be written to 38 files
Data dump for table `sbtest`.`sbtest7` will be written to 38 files
Data dump for table `sbtest`.`sbtest8` will be written to 38 files
Data dump for table `sbtest`.`sbtest9` will be written to 38 files
2 thds dumping - 36% (17.74M rows / ~48.14M rows), 570.93K rows/s, 111.78 MB/s uncompressed, 50.32 MB/s compressed
1 thds dumping - 100% (50.00M rows / ~48.14M rows), 587.61K rows/s, 115.04 MB/s uncompressed, 51.79 MB/s compressed
Duration: 00:01:27s
Schemas dumped: 3
Tables dumped: 10
Uncompressed data size: 9.78 GB
Compressed data size: 4.41 GB
Compression ratio: 2.2
Rows written: 50000000
Bytes written: 4.41 GB
Average uncompressed throughput: 111.86 MB/s
Average compressed throughput: 50.44 MB/s Wykonanie zrzutu całej bazy danych zajęło łącznie 1 minutę i 27 sekund (te same dane, które zostały użyte w mysqldump), a także pokazuje postęp, co będzie bardzo pomocne, aby wiedzieć, jaka część kopii zapasowej została ukończona. Daje czas potrzebny na wykonanie kopii zapasowej.
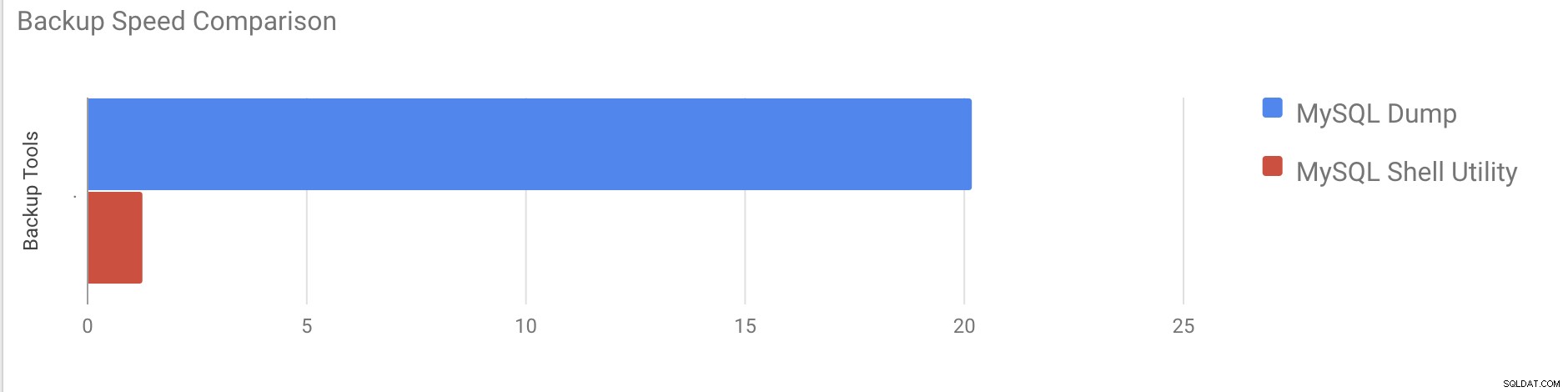
Równoległość zależy od liczby rdzeni na serwerze. Zgrubne zwiększenie wartości nie pomoże w moim przypadku. (Moja maszyna ma 2 rdzenie).
Test szybkości przywracania
W części przywracania zamierzamy przywrócić kopię zapasową mysqldump na innym samodzielnym serwerze. Plik kopii zapasowej został już przeniesiony na serwer docelowy za pomocą rsync.
Przypadek testowy 1
Przykład
[example@sqldat.com vagrant]#time gunzip < /mnt/mysqldump_schemaanddata.sql.gz | mysql -u root -pPrzywrócenie 10 GB danych zajęło około 16 minut i 26 sekund.
Przypadek testowy 2
W tym przypadku używamy narzędzia powłoki mysql do załadowania pliku kopii zapasowej na inny samodzielny host. Przenieśliśmy już plik kopii zapasowej na serwer docelowy. Zacznijmy proces przywracania.
Przykład
MySQL localhost:33060+ ssl JS > util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
Executing DDL script for schema `cluster_control`
Executing DDL script for schema `proxydemo`
Executing DDL script for schema `sbtest`
.
.
.
2 thds loading \ 1% (150.66 MB / 9.78 GB), 6.74 MB/s, 4 / 10 tables done
2 thds loading / 100% (9.79 GB / 9.79 GB), 1.29 MB/s, 10 / 10 tables done
[Worker001] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
[Worker002] example@sqldat.com@@37.tsv.zst: Records: 131614 Deleted: 0 Skipped: 0 Warnings: 0
Executing common postamble SQL
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 2 schemas were loaded in 40 min 6 sec (avg throughput 4.06 MB/s)Przywrócenie 10 GB danych zajęło około 40 minut i 6 sekund.
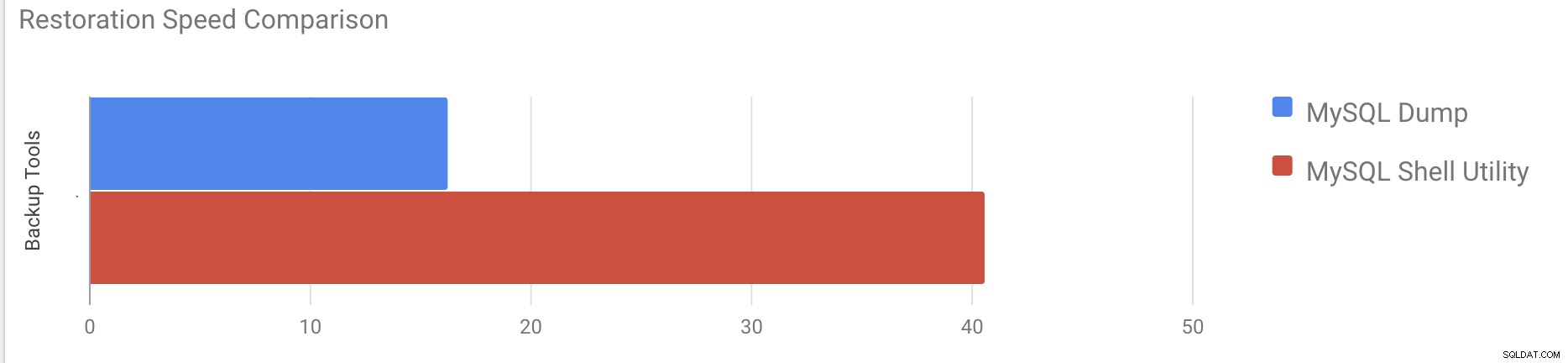
Teraz spróbujmy wyłączyć dziennik przeróbek i rozpocząć importowanie danych za pomocą mysql narzędzie powłoki.
mysql> alter instance disable innodb redo_log;
Query OK, 0 rows affected (0.00 sec)
MySQL localhost:33060+ ssl JS >util.loadDump("/home/vagrant/production_backup", {progressFile :"/home/vagrant/production_backup/log.json",threads :2})
Opening dump...
Target is MySQL 8.0.22. Dump was produced from MySQL 8.0.22
Checking for pre-existing objects...
Executing common preamble SQL
.
.
.
380 chunks (50.00M rows, 9.79 GB) for 10 tables in 3 schemas were loaded in 19 min 56 sec (avg throughput 8.19 MB/s)
0 warnings were reported during the load.Po wyłączeniu dziennika ponawiania średnia przepustowość została zwiększona do 2x.
Uwaga:Nie wyłączaj ponownego logowania w systemie produkcyjnym. Umożliwia zamknięcie i ponowne uruchomienie serwera, gdy ponowne rejestrowanie jest wyłączone, ale nieoczekiwane zatrzymanie serwera, gdy ponowne rejestrowanie jest wyłączone, może spowodować utratę danych i uszkodzenie instancji.
Fizyczne kopie zapasowe
Jak mogłeś zauważyć, logiczne metody tworzenia kopii zapasowych, nawet jeśli są wielowątkowe, są dość czasochłonne nawet w przypadku małego zestawu danych, z którym je przetestowaliśmy. Jest to jeden z powodów, dla których ClusterControl zapewnia fizyczną metodę tworzenia kopii zapasowych opartą na kopiowaniu plików — w takim przypadku nie ogranicza nas warstwa SQL przetwarzająca logiczną kopię zapasową, ale raczej sprzęt — szybkość odczytu plików przez dysk i jak szybko sieć może przesyłać dane między węzłem bazy danych a serwerem zapasowym.
ClusterControl oferuje różne sposoby implementacji fizycznych kopii zapasowych, a dostępna metoda będzie zależeć od typu klastra, a czasem nawet od dostawcy. Rzućmy okiem na Xtrabackup wykonany przez ClusterControl, który utworzy pełną kopię zapasową danych w naszym środowisku testowym.
Tym razem zamierzamy utworzyć kopię zapasową ad-hoc, ale ClusterControl pozwala tworzysz również pełny harmonogram tworzenia kopii zapasowych.
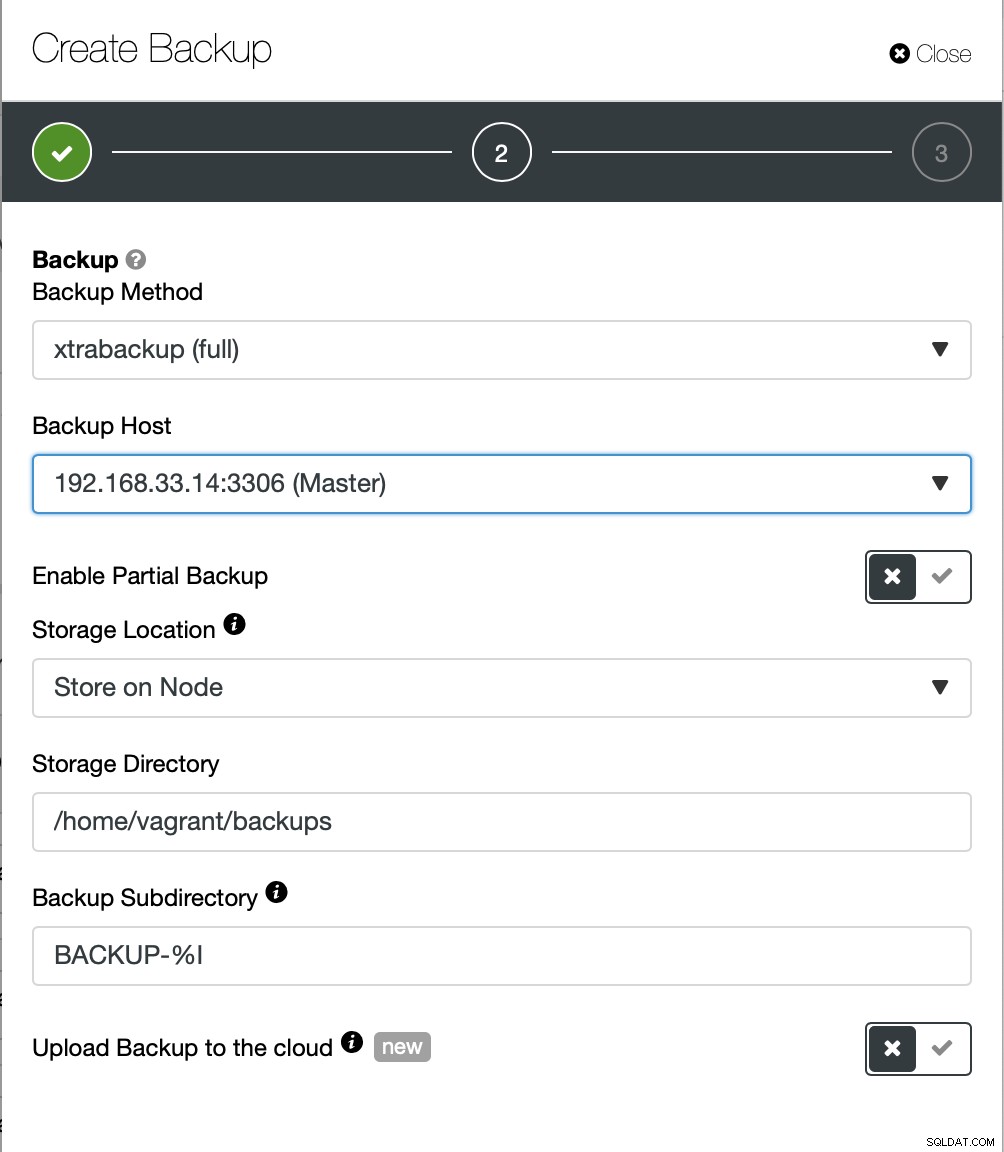
Tutaj wybieramy metodę tworzenia kopii zapasowej (xtrabackup) oraz hosta będą pobierać kopię zapasową. Możemy również przechowywać go lokalnie w węźle lub przesyłać strumieniowo do instancji ClusterControl. Dodatkowo możesz przesłać kopię zapasową do chmury (obsługiwane są AWS, Google Cloud i Azure).
Tworzenie kopii zapasowej zajęło około 10 minut. Tutaj logi z pliku cmon_backup.metadata.
[example@sqldat.com BACKUP-9]# cat cmon_backup.metadata
{
"class_name": "CmonBackupRecord",
"backup_host": "192.168.33.14",
"backup_tool_version": "2.4.21",
"compressed": true,
"created": "2020-11-17T23:37:15.000Z",
"created_by": "",
"db_vendor": "oracle",
"description": "",
"encrypted": false,
"encryption_md5": "",
"finished": "2020-11-17T23:47:47.681Z"
}Teraz spróbujmy przywrócić przy użyciu ClusterControl. ClusterControl> Kopia zapasowa> Przywróć kopię zapasową
Tu wybieramy opcję przywracania kopii zapasowej, która będzie obsługiwała czas i log również odzyskiwanie.
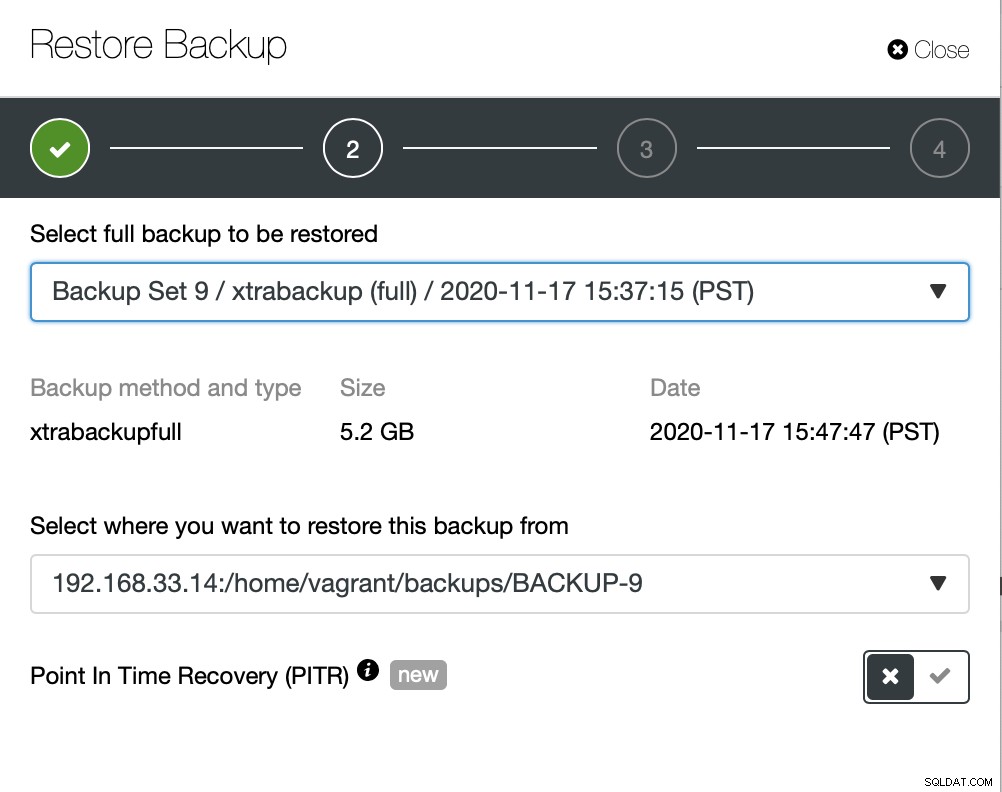
Tutaj wybieramy ścieżkę źródłową pliku kopii zapasowej, a następnie serwer docelowy. Musisz również upewnić się, że ten host jest dostępny z węzła ClusterControl za pomocą SSH.
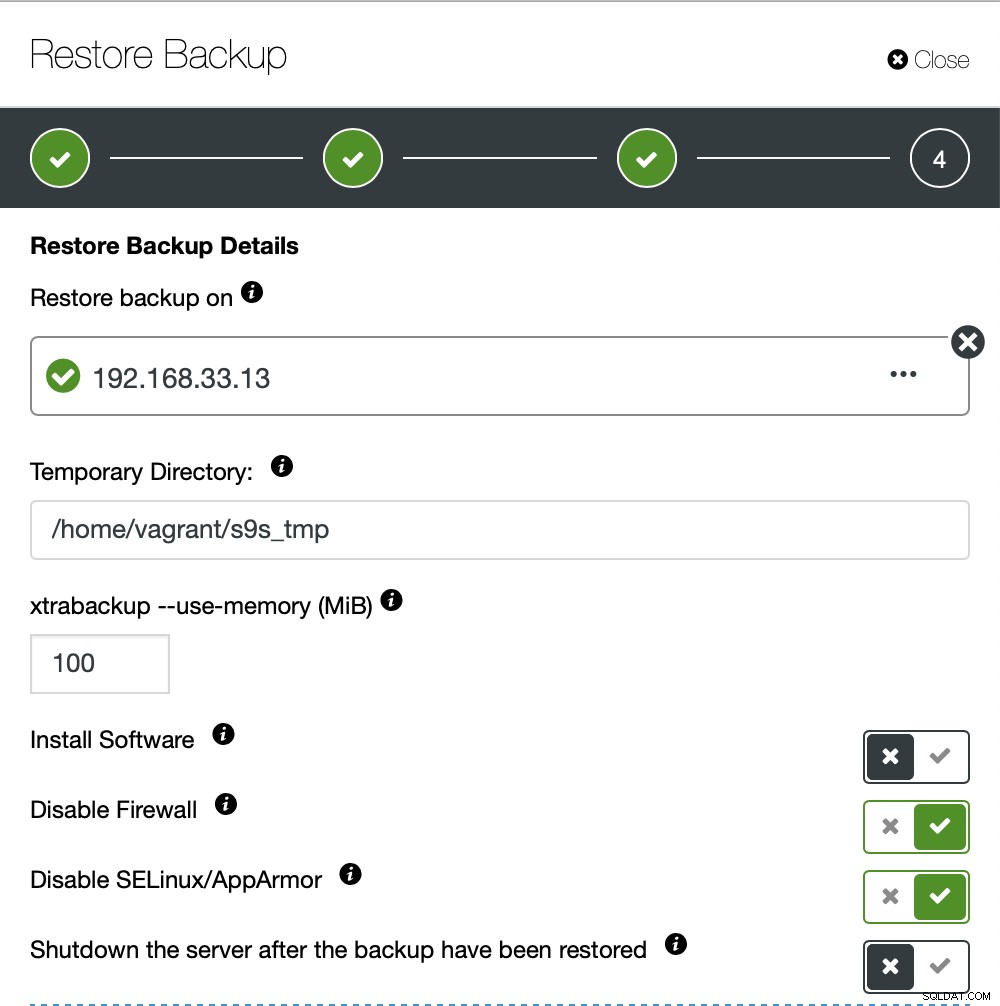
Nie chcemy, aby ClusterControl konfigurował oprogramowanie, więc wyłączyliśmy tę opcję. Po przywróceniu serwer będzie działał.
Przywrócenie 10 GB danych zajęło około 4 minut i 18 sekund. Xtrabackup nie blokuje bazy danych podczas procesu tworzenia kopii zapasowej. W przypadku dużych baz danych (100+ GB) zapewnia znacznie lepszy czas przywracania w porównaniu do narzędzia mysqldump/shell. Również lusterControl obsługuje częściową kopię zapasową i przywracanie, jak wyjaśnił jeden z moich kolegów na swoim blogu:Częściowa kopia zapasowa i przywracanie.
Wniosek
Każda metoda ma swoje zalety i wady. Jak widzieliśmy, nie ma jednej metody, która najlepiej sprawdza się we wszystkim, co musisz zrobić. Musimy wybrać nasze narzędzie w oparciu o nasze środowisko produkcyjne i docelowy czas odzyskiwania.