Bazy danych muszą działać optymalnie, ale to nie jest takie proste zadanie. Baza danych INFORMATION SCHEMA może być Twoją tajną bronią w wojnie o optymalizację baz danych.
Jesteśmy przyzwyczajeni do tworzenia baz danych za pomocą interfejsu graficznego lub serii poleceń SQL. To całkowicie w porządku, ale dobrze jest też trochę zrozumieć, co dzieje się w tle. Jest to ważne przy tworzeniu, utrzymywaniu i optymalizacji bazy danych, a także jest dobrym sposobem na śledzenie zmian zachodzących „za kulisami”.
W tym artykule przyjrzymy się kilku zapytaniom SQL, które mogą pomóc Ci zajrzeć do działania bazy danych MySQL.
Baza danych INFORMATION_SCHEMA
Omówiliśmy już INFORMATION_SCHEMA w tym artykule. Jeśli jeszcze tego nie przeczytałeś, zdecydowanie sugeruję, abyś to zrobił przed kontynuowaniem.
Jeśli potrzebujesz odświeżenia na INFORMATION_SCHEMA baza danych – lub jeśli zdecydujesz się nie czytać pierwszego artykułu – oto kilka podstawowych faktów, które musisz wiedzieć:
INFORMATION_SCHEMAbaza danych jest częścią standardu ANSI. Będziemy pracować z MySQL, ale inne RDBMS mają swoje warianty. Możesz znaleźć wersje dla H2 Database, HSQLDB, MariaDB, Microsoft SQL Server i PostgreSQL.- To jest baza danych, która śledzi wszystkie inne bazy danych na serwerze; tutaj znajdziemy opisy wszystkich obiektów.
- Jak każda inna baza danych,
INFORMATION_SCHEMAbaza danych zawiera szereg powiązanych tabel i informacji o różnych obiektach. - Możesz wysłać zapytanie do tej bazy danych za pomocą SQL i użyć wyników do:
- Monitoruj stan i wydajność bazy danych oraz
- Automatycznie generuj kod na podstawie wyników zapytania.
Przejdźmy teraz do odpytywania bazy danych INFORMATION_SCHEMA. Zaczniemy od przyjrzenia się modelowi danych, którego będziemy używać.
Model danych
Model, którego użyjemy w tym artykule, pokazano poniżej.
Jest to uproszczony model, który pozwala nam przechowywać informacje o zajęciach, instruktorach, uczniach i inne powiązane szczegóły. Przyjrzyjmy się pokrótce tabelom.
Przechowamy listę instruktorów u lecturer stół. Dla każdego wykładowcy zarejestrujemy first_name i last_name .
class tabela zawiera listę wszystkich klas jakie mamy w naszej szkole. Dla każdego rekordu w tej tabeli będziemy przechowywać class_name , identyfikator wykładowcy, planowana start_date i end_date i wszelkie dodatkowe class_details . Dla uproszczenia zakładam, że mamy tylko jednego wykładowcę na zajęcia.
Zajęcia są zwykle organizowane w formie serii wykładów. Zwykle wymagają jednego lub więcej egzaminów. Będziemy przechowywać listy powiązanych wykładów i egzaminów w lecture i exam tabele. Oba będą miały identyfikator powiązanej klasy i oczekiwany start_time i end_time .
Teraz potrzebujemy studentów na nasze zajęcia. Lista wszystkich uczniów jest przechowywana w student stół. Po raz kolejny będziemy przechowywać tylko first_name i last_name każdego ucznia.
Ostatnią rzeczą, którą musimy zrobić, to śledzić działania uczniów. Przechowamy listę wszystkich zajęć, na które zapisał się uczeń, listę obecności uczniów i wyniki ich egzaminów. Każda z pozostałych trzech tabel – on_class , on_lecture i on_exam – będzie miał odniesienie do ucznia i odniesienie do odpowiedniej tabeli. Tylko on_exam tabela będzie miała dodatkową wartość:ocena.
Tak, ten model jest bardzo prosty. Moglibyśmy dodać wiele innych szczegółów dotyczących studentów, wykładowców i zajęć. Możemy przechowywać wartości historyczne, gdy rekordy są aktualizowane lub usuwane. Mimo to ten model wystarczy do celów tego artykułu.
Tworzenie bazy danych
Jesteśmy gotowi do stworzenia bazy danych na naszym lokalnym serwerze i zbadania, co się w niej dzieje. Wyeksportujemy model (w Vertabelo) za pomocą „Generate SQL script " przycisk.
Następnie utworzymy bazę danych na instancji MySQL Server. Nazwałem swoją bazę danych „classes_and_students ”.
Następną rzeczą, którą musimy zrobić, jest uruchomienie wcześniej wygenerowanego skryptu SQL.
Teraz mamy bazę danych ze wszystkimi jej obiektami (tabele, klucze główne i obce, klucze alternatywne).
Rozmiar bazy danych
Po uruchomieniu skryptu dane o „classes and students ” baza danych jest przechowywana w INFORMATION_SCHEMA Baza danych. Te dane znajdują się w wielu różnych tabelach. Nie będę ich tutaj wymieniać ponownie; zrobiliśmy to w poprzednim artykule.
Zobaczmy, jak możemy użyć standardowego SQL na tej bazie danych. Zacznę od jednego bardzo ważnego zapytania:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Pytamy tylko o INFORMATION_SCHEMA.TABLES tabela tutaj. Ta tabela powinna dać nam więcej niż wystarczająco dużo szczegółów na temat wszystkich tabel na serwerze. Pamiętaj, że odfiltrowałem tylko tabele z „classes_and_students " bazy danych przy użyciu SET zmienna w pierwszym wierszu, a później używając tej wartości w zapytaniu. Większość tabel zawiera kolumny TABLE_NAME i TABLE_SCHEMA , które oznaczają tabelę i schemat/bazę danych, do której należą te dane.
To zapytanie zwróci aktualny rozmiar naszej bazy danych i wolne miejsce zarezerwowane dla naszej bazy danych. Oto rzeczywisty wynik:

Zgodnie z oczekiwaniami rozmiar naszej pustej bazy danych jest mniejszy niż 1 MB, a zarezerwowane wolne miejsce jest znacznie większe.
Rozmiary i właściwości tabel
Następną interesującą rzeczą do zrobienia byłoby przyjrzenie się rozmiarom tabel w naszej bazie danych. W tym celu użyjemy następującego zapytania:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
Zapytanie jest prawie identyczne jak poprzednie, z jednym wyjątkiem:wynik jest pogrupowany na poziomie tabeli.
Oto obraz wyniku zwróconego przez to zapytanie:
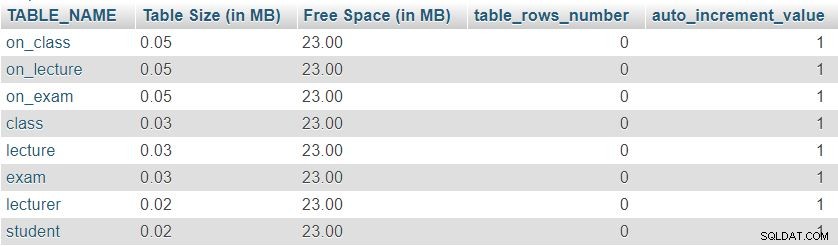
Po pierwsze, możemy zauważyć, że wszystkie osiem stołów ma minimalny „Rozmiar stołu” zarezerwowane dla definicji tabeli, która obejmuje kolumny, klucz podstawowy i indeks. „Wolna przestrzeń” jest równomiernie rozłożony na wszystkie stoły.
Możemy również zobaczyć liczbę wierszy aktualnie w każdej tabeli i bieżącą wartość auto_increment właściwość dla każdej tabeli. Ponieważ wszystkie tabele są całkowicie puste, nie mamy danych i auto_increment jest ustawiona na 1 (wartość, która zostanie przypisana do następnego wstawionego wiersza).
Klucze główne
Każda tabela powinna mieć zdefiniowaną wartość klucza podstawowego, więc dobrze jest sprawdzić, czy jest to prawdą dla naszej bazy danych. Jednym ze sposobów, aby to zrobić, jest połączenie listy wszystkich tabel z listą ograniczeń. To powinno dać nam potrzebne informacje.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
Użyliśmy również INFORMATION_SCHEMA.COLUMNS tabela w tym zapytaniu. Podczas gdy pierwsza część zapytania po prostu zwróci wszystkie tabele w bazie danych, druga część (po LEFT JOIN ) policzy liczbę PRI w tych tabelach. Użyliśmy LEFT JOIN ponieważ chcemy sprawdzić, czy tabela ma 0 PRI w COLUMNS tabela.
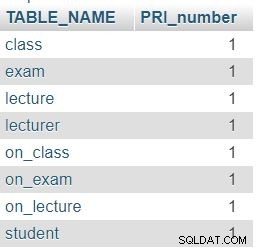
Zgodnie z oczekiwaniami, każda tabela w naszej bazie danych zawiera dokładnie jedną kolumnę klucza podstawowego (PRI).
„Wyspy”?
„Wyspy” to stoły całkowicie oddzielone od reszty modelu. Zdarzają się, gdy tabela nie zawiera kluczy obcych i nie ma do niej odniesień w żadnej innej tabeli. To naprawdę nie powinno mieć miejsca, chyba że istnieje naprawdę dobry powód, np. gdy tabele zawierają parametry lub przechowują wyniki lub raporty wewnątrz modelu.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Jaka jest idea tego zapytania? Cóż, używamy INFORMATION_SCHEMA.KEY_COLUMN_USAGE tabela, aby sprawdzić, czy jakakolwiek kolumna w tabeli jest odniesieniem do innej tabeli lub czy jakakolwiek kolumna jest używana jako odwołanie w dowolnej innej tabeli. Pierwsza część zapytania wybiera wszystkie tabele. Po pierwszym LEFT JOIN zliczamy, ile razy dowolna kolumna z tej tabeli została użyta jako odwołanie. Po drugim LEFT JOIN liczymy, ile razy dowolna kolumna z tej tabeli odwoływała się do dowolnej innej tabeli.
Zwrócony wynik to:
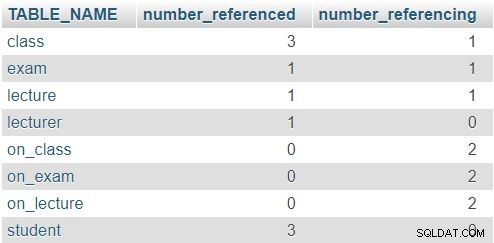
W wierszu dla class tabeli, liczby 3 i 1 wskazują, że do tej tabeli odwołano się trzykrotnie (w lecture , exam i on_class tabel) i zawiera jeden atrybut odwołujący się do innej tabeli (lecturer_id ). Pozostałe tabele mają podobny wzór, chociaż rzeczywiste liczby będą oczywiście inne. Zasada jest taka, że żaden wiersz nie powinien mieć 0 w obu kolumnach.
Dodawanie wierszy
Jak dotąd wszystko poszło zgodnie z oczekiwaniami. Pomyślnie zaimportowaliśmy nasz model danych z Vertabelo do lokalnego serwera MySQL. Wszystkie tabele zawierają klucze, tak jak tego chcemy, a wszystkie tabele są ze sobą powiązane – w naszym modelu nie ma „wysp”.
Teraz wstawimy kilka wierszy do naszych tabel i użyjemy wcześniej zademonstrowanych zapytań do śledzenia zmian w naszej bazie danych.
Po dodaniu 1000 wierszy w tabeli wykładowcy ponownie uruchomimy zapytanie z „Table Sizes and Properties " Sekcja. Zwróci następujący wynik:
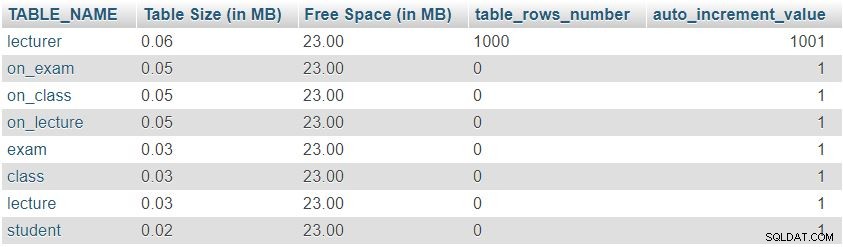
Możemy łatwo zauważyć, że liczba wierszy i wartości auto_increment zmieniły się zgodnie z oczekiwaniami, ale nie nastąpiła znacząca zmiana w rozmiarze tabeli.
To był tylko przykład testowy; w rzeczywistych sytuacjach zauważylibyśmy znaczące zmiany. Liczba wierszy zmieni się drastycznie w tabelach wypełnianych przez użytkowników lub zautomatyzowane procesy (tj. tabele, które nie są słownikami). Sprawdzanie rozmiaru i wartości w takich tabelach to bardzo dobry sposób na szybkie znalezienie i poprawienie niepożądanego zachowania.
Chcesz udostępnić?
Praca z bazami danych to ciągłe dążenie do optymalnej wydajności. Aby odnieść większy sukces w tym dążeniu, powinieneś użyć dowolnego dostępnego narzędzia. Dziś widzieliśmy kilka zapytań, które przydają się w naszej walce o lepszą wydajność. Czy znalazłeś coś jeszcze przydatnego? Czy grałeś z INFORMATION_SCHEMA? baza danych przed? Podziel się swoim doświadczeniem w komentarzach poniżej.