Wdrożenie wyszukiwania przyjaznego dla użytkownika może być trudne, ale może być również wykonane bardzo efektywnie. Skąd mam to wiedzieć? Nie tak dawno musiałem zaimplementować wyszukiwarkę w aplikacji mobilnej. Aplikacja została zbudowana na platformie Ionic i łączy się z backendem CakePHP 2. Pomysł polegał na wyświetlaniu wyników podczas pisania przez użytkownika. Było na to kilka opcji, ale nie wszystkie spełniały wymagania mojego projektu.
Aby zilustrować, na czym polega tego rodzaju zadanie, wyobraźmy sobie wyszukiwanie utworów i ich możliwych relacji (takich jak artyści, albumy itp.).
Rekordy musiałyby być posortowane według trafności, co zależałoby od tego, czy wyszukiwane słowo pasuje do pól z samego rekordu, czy z innych kolumn w powiązanych tabelach. Ponadto wyszukiwanie powinno uwzględniać przynajmniej kilka podstawowych rdzennych słów. (Pnia jest używany do uzyskania formy rdzenia słowa. „Pnie”, „pnia”, „pnia” i „pnia” mają ten sam rdzeń:„rdzeń”.)
Przedstawione tutaj podejście zostało przetestowane na kilkuset tysiącach rekordów i było w stanie uzyskać przydatne wyniki podczas pisania przez użytkownika.
Pełnotekstowe produkty wyszukiwania do rozważenia
Istnieje kilka sposobów na zaimplementowanie tego rodzaju wyszukiwania. Nasz projekt miał pewne ograniczenia w zakresie czasu i zasobów serwerowych, więc musieliśmy zachować jak najprostsze rozwiązanie. W końcu pojawiło się kilku pretendentów:
Elasticsearch
Elasticsearch zapewnia wyszukiwanie pełnotekstowe w usłudze zorientowanej na dokumenty. Został zaprojektowany do zarządzania ogromnymi ilościami obciążenia w sposób rozproszony:może klasyfikować wyniki według trafności, przeprowadzać agregacje i pracować z rdzennymi słowami i synonimy. To narzędzie jest przeznaczone do wyszukiwania w czasie rzeczywistym. Z ich strony internetowej:
Elasticsearch tworzy rozproszone możliwości na bazie Apache Lucene, aby zapewnić najpotężniejsze dostępne możliwości wyszukiwania pełnotekstowego. Potężny, przyjazny dla programistów interfejs API zapytań obsługuje wielojęzyczne wyszukiwanie, geolokalizację, kontekstowe sugestie, autouzupełnianie i fragmenty wyników.
Elasticsearch może działać jako usługa REST, odpowiadając na żądania http i można ją bardzo szybko skonfigurować. Jednak uruchomienie silnika jako usługi wymaga posiadania pewnych uprawnień dostępu do serwera. A jeśli twój dostawca hostingu nie obsługuje Elasticsearch od razu, będziesz musiał zainstalować kilka pakietów.
Najważniejsze jest to, że ten produkt jest świetną opcją, jeśli potrzebujesz solidnego rozwiązania wyszukiwania. (Uwaga:możesz potrzebować VPS lub serwera dedykowanego, ponieważ wymagania sprzętowe są dość wysokie).
Sfinks
Podobnie jak Elasticsearch, Sphinx zapewnia również bardzo solidny produkt wyszukiwania pełnotekstowego:Craigslist obsługuje ponad 300 000 000 zapytań dziennie. Sphinx nie zapewnia natywnego interfejsu RESTful. Jest zaimplementowany w C, z mniejszą ilością sprzętu niż Elasticsearch (który jest zaimplementowany w Javie i może działać na dowolnym systemie operacyjnym z jvm). Potrzebny będzie również dostęp root do serwera z dedykowaną pamięcią RAM/procesorem, aby poprawnie uruchomić Sphinxa.
Pełnotekstowe wyszukiwanie MySQL
W przeszłości wyszukiwanie pełnotekstowe było obsługiwane w silnikach MyISAM. Po wersji 5.6 MySQL obsługiwał również wyszukiwanie pełnotekstowe w silnikach pamięci masowej InnoDB. To świetna wiadomość, ponieważ umożliwia programistom czerpanie korzyści z integralności referencyjnej InnoDB, możliwości wykonywania transakcji i blokad na poziomie wiersza.
Istnieją zasadniczo dwa podejścia do wyszukiwania pełnotekstowego w MySQL:język naturalny i tryb logiczny. (Trzecia opcja rozszerza wyszukiwanie w języku naturalnym o drugie zapytanie rozszerzające).
Główna różnica między trybami naturalnymi i boolowskimi polega na tym, że wartość logiczna dopuszcza niektóre operatory jako część wyszukiwania. Na przykład operatory logiczne mogą być używane, jeśli słowo ma większe znaczenie niż inne w zapytaniu lub jeśli określone słowo powinno być obecne w wynikach itp. Warto zauważyć, że w obu przypadkach wyniki mogą być sortowane według trafności obliczonej przez MySQL podczas wyszukiwania.
Podejmowanie decyzji
Najlepszym rozwiązaniem dla naszego problemu było użycie wyszukiwania pełnotekstowego InnoDb w trybie logicznym. Czemu?
- Mieliśmy mało czasu na wdrożenie funkcji wyszukiwania.
- W tym momencie nie mieliśmy dużych zbiorów danych do zgniatania ani ogromnego obciążenia, które wymagałoby czegoś takiego jak Elasticsearch lub Sphinx.
- Użyliśmy hostingu współdzielonego, który nie obsługuje Elasticsearch ani Sphinx, a sprzęt był na tym etapie dość ograniczony.
- Chociaż chcieliśmy w naszej funkcji wyszukiwania odwoływać się do słów, nie była to przerwa:mogliśmy to zaimplementować (w ramach ograniczeń) za pomocą prostego kodowania PHP i denormalizacji danych
- Wyszukiwania pełnotekstowe w trybie boolowskim mogą wyszukiwać słowa za pomocą symboli wieloznacznych (dla rdzenia słów) i sortować wyniki na podstawie trafności.
Wyszukiwanie pełnotekstowe w trybie logicznym
Jak wspomniano wcześniej, wyszukiwanie w języku naturalnym jest najprostszym podejściem:wystarczy wyszukać frazę lub słowo w kolumnach, w których ustawiono indeks pełnotekstowy, a otrzymasz wyniki posortowane według trafności.
W znormalizowanym modelu Vertabelo
Zobaczmy, jak działa proste wyszukiwanie. Najpierw utworzymy przykładową tabelę:
-- Created by Vertabelo (https://vertabelo.com) -- Last modification date: 2016-04-25 15:01:22.153 -- tables -- Table: artists CREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id) ) ENGINE InnoDB; CREATE FULLTEXT INDEX artists_idx_1 ON artists (name); -- End of file.
W trybie języka naturalnego
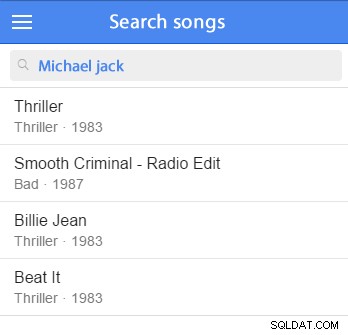
Możesz wstawić kilka przykładowych danych i rozpocząć testowanie. (Byłoby dobrze dodać go do przykładowego zbioru danych.) Na przykład spróbujemy wyszukać Michaela Jacksona:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN NATURAL LANGUAGE MODE)
To zapytanie znajdzie rekordy pasujące do wyszukiwanych haseł i posortuje pasujące rekordy według trafności; im lepsze dopasowanie, tym bardziej jest ono trafne i im wyższy wynik pojawi się na liście.
W trybie logicznym
Możemy przeprowadzić to samo wyszukiwanie w trybie boolowskim. Jeśli nie zastosujemy żadnych operatorów do naszego zapytania, jedyną różnicą będzie to, że wyniki nie są posortowane według trafności:
SELECT
*
FROM
artists
WHERE
MATCH (artists.name) AGAINST ('Michael Jackson' IN BOOLEAN MODE)
Operator wieloznaczny w trybie logicznym
Ponieważ chcemy wyszukiwać słowa rdzeniowe i częściowe, będziemy potrzebować operatora symboli wieloznacznych (*). Ten operator może być używany w wyszukiwaniu w trybie logicznym, dlatego wybraliśmy ten tryb.
Uwolnijmy więc moc wyszukiwania logicznego i spróbujmy wyszukać część nazwiska artysty. Użyjemy operatora symboli wieloznacznych, aby dopasować dowolnego artystę, którego nazwa zaczyna się od „Mich”:
SELECT
*
FROM
artists
WHERE
MATCH (name) AGAINST ('Mich*' IN BOOLEAN MODE)
Sortowanie według trafności w trybie logicznym
Zobaczmy teraz obliczoną trafność wyszukiwania. Pomoże nam to zrozumieć sortowanie, które będziemy robić później z Cake:
SELECT
*, MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE) AS rank
FROM
artists
WHERE
MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)
ORDER BY rank DESC
To zapytanie pobiera dopasowania wyszukiwania i wartość trafności, którą MySQL oblicza dla każdego rekordu. Optymalizator silnika wykryje, że wybieramy trafność, więc nie zawraca sobie głowy ponownym obliczaniem rangi.
Pochodzenie słów w wyszukiwaniu pełnotekstowym
Gdy w wyszukiwaniu umieścimy słowo rdzenne, wyszukiwanie staje się bardziej przyjazne dla użytkownika. Nawet jeśli wynik sam w sobie nie jest słowem, algorytmy próbują wygenerować ten sam rdzeń dla słów pochodnych. Na przykład rdzeń „argu” nie jest słowem angielskim, ale może być użyty jako rdzeń dla „argumentować”, „argumentować”, „argumentować”, „argumentować”, „Argus” i innych słów.
Stemming poprawia wyniki, ponieważ użytkownik może wprowadzić słowo, które nie ma dokładnego dopasowania, ale jego „rdzeń” ma. Chociaż stemmer PHP lub program Snowball w Pythonie może być opcją (jeśli masz rootowy dostęp SSH do swojego serwera), użyjemy klasy PorterStemmer.php.
Ta klasa implementuje algorytm zaproponowany przez Martina Portera do macierzystych słów w języku angielskim. Jak stwierdził autor na swojej stronie internetowej, można z niego korzystać w dowolnym celu. Po prostu upuść plik do swojego katalogu Vendors w CakePHP, dołącz bibliotekę do swojego modelu i wywołaj metodę statyczną, aby zakorzenić słowo:
//include the library (should be called PorterStemmer.php) within CakePHP’s Vendors folder
App::import('Vendor', 'PorterStemmer');
//stem a word (words must be stemmed one by one)
echo PorterStemmer::Stem(‘stemming’);
//output will be ‘stem’
Naszym celem jest przyspieszenie i wydajność wyszukiwania oraz umożliwienie sortowania wyników według ich trafności pełnotekstowej. Aby to zrobić, będziemy musieli użyć podstaw słów na dwa sposoby:
- Słowa wprowadzone przez użytkownika
- Dane związane z utworami (które będziemy przechowywać w kolumnach i sortować według trafności)
Pierwszy rodzaj rdzennych słów można wykonać w ten sposób:
App::import('Vendor', 'PorterStemmer');
$search = trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));//remove undesired characters
$words = explode(" ", trim($search));
$stemmedSearch = "";
$unstemmedSearch = "";
foreach ($words as $word) {
$stemmedSearch .= PorterStemmer::Stem($word) . "* ";//we add the wildcard after each word
$unstemmedSearch = $word . "* " ;//to search the artist column which is not stemmed
}
$stemmedSearch = trim($stemmedSearch);
$unstemmedSearch = trim($unstemmedSearch);
if ($stemmedSearch == "*" || $unstemmedSearch=="*") {
//otherwise mySql will complain, as you cannot use the wildcard alone
$stemmedSearch = "";
$unstemmedSearch = "";
}
Utworzyliśmy dwa ciągi:jeden do wyszukiwania nazwy wykonawcy (bez rdzenia), a drugi do wyszukiwania w pozostałych kolumnach z motywami. Pomoże nam to później zbudować nasze „przeciw” część zapytania pełnotekstowego. Zobaczmy teraz, jak możemy zatamować i posortować dane utworu.
Denormalizacja danych utworu
Nasze kryteria sortowania będą opierać się na pierwszym dopasowaniu wykonawcy utworu (bez stemmingu). Następnie pojawi się nazwa utworu, album i powiązane kategorie. Steming zostanie użyty we wszystkich drugorzędnych kryteriach wyszukiwania.
Aby to zilustrować, załóżmy, że szukam słowa „nirvana” i jest tam piosenka „Nirvana Games” autorstwa „XYZ” i inna piosenka „Polly” artysty „Nirvana”. Wyniki powinny zawierać najpierw „Polly”, ponieważ dopasowanie nazwy wykonawcy jest ważniejsze niż dopasowanie nazwy utworu (w oparciu o moje kryteria).
W tym celu dodałem 4 pola w songs tabela, po jednym dla każdego z kryteriów wyszukiwania/sortowania, które chcemy:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER`denorm_trackname`, ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Nasz kompletny model bazy danych wyglądałby tak:
Za każdym razem, gdy zapisujesz piosenkę za pomocą dodawania/edycji w CakePHP, wystarczy zapisać nazwę wykonawcy w kolumnie denorm_artist bez powstrzymywania. Następnie dodaj tytułową nazwę utworu w denorm_trackname pole (podobne do tego, co zrobiliśmy w wyszukiwanym tekście) i zapisz nazwę albumu z tematem w denorm_album kolumna. Na koniec zapisz ustawioną kategorię tematyczną dla utworu w denorm_categories pola, łącząc słowa i dodając jedną spację między każdą nazwą kategorii.
Pełnotekstowe wyszukiwanie i sortowanie według trafności w CakePHP
Kontynuując przykład wyszukiwania „Nirvana”, zobaczmy, co może osiągnąć podobne zapytanie:
SELECT
trackname,
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank1,
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank2,
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank3,
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank4
FROM songs
WHERE
MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR
MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE)
ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC
Otrzymalibyśmy następujący wynik:
| nazwa utworu | rank1 | rank2 | rank3 | rank4 |
| Polly | 0.0906190574169159 | 0 | 0 | 0 |
| gry nirwany | 0 | 0.0906190574169159 | 0 | 0 |
Aby to zrobić w CakePHP, znajdź metoda musi być wywołana przy użyciu kombinacji parametrów „pól”, „warunków” i „zamówień”. Kontynuując poprzedni przykładowy kod PHP:
//within Song.php model file
$fields = array(
"Song.trackname",
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) as `rank1`",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank2`",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank3`",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank4`"
);
$order = "`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";
$conditions = array(
"OR" => array(
"MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)",
"MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)"
)
);
$results = $this->find(‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order);
$wyniki będzie tablicą utworów posortowanych według kryteriów, które zdefiniowaliśmy wcześniej.
To rozwiązanie może być używane do generowania wyszukiwań, które są znaczące dla użytkownika – bez poświęcania zbyt wiele czasu programistom lub dodawania większej złożoności do kodu.
Sprawianie, że wyszukiwania CakePHP są jeszcze lepsze
Warto wspomnieć, że „doprawienie” zdenormalizowanych kolumn większą ilością danych może prowadzić do lepszych wyników.
Przez „przyprawianie” rozumiem, że możesz uwzględnić w zdenormalizowanych kolumnach więcej danych z dodatkowych kolumn, które uważasz za przydatne, aby wyniki były bardziej trafne, na przykład jeśli wiesz, że kraj artysty może znaleźć się w wyszukiwanych hasłach, może dodać kraj wraz z nazwą wykonawcy w denorm_artist kolumna. Poprawiłoby to jakość wyników wyszukiwania.
Z mojego doświadczenia (w zależności od rzeczywistych danych, których używasz i kolumn, które denormalizujesz) najwyższe wyniki wydają się być naprawdę dokładne. Jest to świetne rozwiązanie w przypadku aplikacji mobilnych, ponieważ przewijanie długiej listy może być frustrujące dla użytkownika.
Wreszcie, jeśli potrzebujesz uzyskać więcej danych z tabel, do których odnosi się utwór, zawsze możesz dołączyć i uzyskać wykonawcę, kategorie, albumy, komentarze do utworów itp. Jeśli używasz filtra zachowań z zawartością CakePHP, chciałbym zasugeruj dodanie wtyczki EagerLoader, aby skutecznie wykonać połączenia.
Jeśli masz własne podejście do implementacji wyszukiwania pełnotekstowego, podziel się nim w komentarzach poniżej. Wszyscy możemy uczyć się od siebie nawzajem.