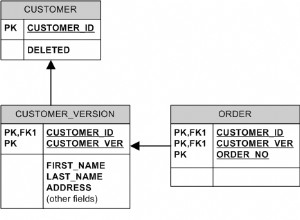
2 miliony baz danych? Zakładam, że miałeś na myśli „rzędy”.
W każdym razie, jeśli chodzi o ograniczenia:jedną z najważniejszych rzeczy, o których należy pamiętać, jest to, że klaster NDB/MySQL nie jest bazą danych ogólnego przeznaczenia. Przede wszystkim operacje łączenia, ale także podzapytania i operacje zakresu (zapytania takie jak:zamówienia utworzone między teraz a tydzień temu) mogą być znacznie wolniejsze niż można by się spodziewać. Wynika to częściowo z faktu, że dane są rozłożone na wiele węzłów. Chociaż wprowadzono pewne ulepszenia, wydajność łączenia może nadal być bardzo rozczarowująca.
Z drugiej strony, jeśli musisz poradzić sobie z wieloma (najlepiej małymi) jednoczesnymi transakcjami (zwykle aktualizacje/wstawienia/usuwanie wyszukiwań pojedynczych wierszy według klucza podstawowego) i udaje Ci się zachować wszystkie swoje dane w pamięci, może to być bardzo skalowalne i wydajne rozwiązanie.
Powinieneś zadać sobie pytanie, dlaczego chcesz klastra. Jeśli po prostu chcesz mieć zwykłą bazę danych, którą masz teraz, z wyjątkiem dodanej 99,999% dostępności, możesz być rozczarowany. Z pewnością klaster MySQL może zapewnić Ci doskonałą dostępność i czas pracy, ale obciążenie Twojej aplikacji może nie być zbyt dobrze dostosowane do tego, do czego klaster jest odpowiedni. Dodatkowo możesz użyć innego rozwiązania o wysokiej dostępności, aby zwiększyć czas pracy swojej tradycyjnej bazy danych.
BTW - oto lista ograniczeń zgodnie z dokumentacją:https://dev.mysql.com/doc/refman/5.1/en/mysql-cluster-limitations.html
Ale cokolwiek robisz, wypróbuj klaster, zobacz, czy to dla ciebie dobre. Klaster MySQL to nie „MySQL + 5 dziewiątek”. Dowiesz się, kiedy spróbujesz.