Brak procedur składowanych, tabel tymczasowych, tylko jedno zapytanie i wydajny plan wykonania z indeksem w kolumnie daty:
select
subdate(
'2012-12-31',
floor(dateDiff('2012-12-31', dateStampColumn) / 30) * 30 + 30 - 1
) as "period starting",
subdate(
'2012-12-31',
floor(dateDiff('2012-12-31', dateStampColumn) / 30) * 30
) as "period ending",
count(*)
from
YOURTABLE
group by floor(dateDiff('2012-12-31', dateStampColumn) / 30);
Powinno być całkiem oczywiste, co się tutaj dzieje, z wyjątkiem tej inkantacji:
floor(dateDiff('2012-12-31', dateStampColumn) / 30)
To wyrażenie pojawia się kilka razy i jest obliczane na podstawie liczby okresów 30-dniowych sprzed dateStampColumn jest. dateDiff zwraca różnicę w dniach, dzieli ją przez 30, aby uzyskać ją w okresach 30-dniowych, i podaje wszystko do floor() zaokrąglić do liczby całkowitej. Gdy już mamy ten numer, możemy GROUP BY to, a następnie wykonujemy trochę matematyki, aby przetłumaczyć tę liczbę z powrotem na datę początkową i końcową okresu.
Zastąp '2012-12-31' z now() Jeśli wolisz. Oto kilka przykładowych danych:
CREATE TABLE YOURTABLE
(`Id` int, `dateStampColumn` datetime);
INSERT INTO YOURTABLE
(`Id`, `dateStampColumn`)
VALUES
(1, '2012-10-15 02:00:00'),
(1, '2012-10-17 02:00:00'),
(1, '2012-10-30 02:00:00'),
(1, '2012-10-31 02:00:00'),
(1, '2012-11-01 02:00:00'),
(1, '2012-11-02 02:00:00'),
(1, '2012-11-18 02:00:00'),
(1, '2012-11-19 02:00:00'),
(1, '2012-11-21 02:00:00'),
(1, '2012-11-25 02:00:00'),
(1, '2012-11-25 02:00:00'),
(1, '2012-11-26 02:00:00'),
(1, '2012-11-26 02:00:00'),
(1, '2012-11-24 02:00:00'),
(1, '2012-11-23 02:00:00'),
(1, '2012-11-28 02:00:00'),
(1, '2012-11-29 02:00:00'),
(1, '2012-11-30 02:00:00'),
(1, '2012-12-01 02:00:00'),
(1, '2012-12-02 02:00:00'),
(1, '2012-12-15 02:00:00'),
(1, '2012-12-17 02:00:00'),
(1, '2012-12-18 02:00:00'),
(1, '2012-12-19 02:00:00'),
(1, '2012-12-21 02:00:00'),
(1, '2012-12-25 02:00:00'),
(1, '2012-12-25 02:00:00'),
(1, '2012-12-26 02:00:00'),
(1, '2012-12-26 02:00:00'),
(1, '2012-12-24 02:00:00'),
(1, '2012-12-23 02:00:00'),
(1, '2012-12-31 02:00:00'),
(1, '2012-12-30 02:00:00'),
(1, '2012-12-28 02:00:00'),
(1, '2012-12-28 02:00:00'),
(1, '2012-12-30 02:00:00');
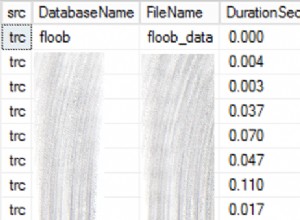
A wynik:
period starting period ending count(*)
2012-12-02 2012-12-31 17
2012-11-02 2012-12-01 14
2012-10-03 2012-11-01 5
punkty końcowe okresu są włącznie.
Pobaw się tym w SQL Fiddle .
Istnieje trochę potencjalnej głupoty w tym, że dowolny 30-dniowy okres bez pasujących wierszy nie zostanie uwzględniony w wyniku. Gdybyś mógł dołączyć do tego z tabelą okresów, można by to wyeliminować. Jednak MySQL nie ma czegoś takiego jak generate_series() , więc musisz sobie z tym poradzić w swojej aplikacji lub spróbuj ten sprytny hack .