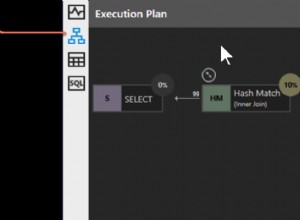
Istnieje kilka alternatyw ułatwiających pracę z informacjami hierarchicznymi w SQL:
-
Typowe wyrażenia tabelowe (zgodnie ze standardem SQL-2003) obsługuje rekurencyjne zapytania SQL względem typu identyfikatora nadrzędnego używanych danych. Jak dotąd MySQL nie obsługuje tej funkcji. PostgreSQL 8.4, Microsoft SQL Server i IBM DB2 to przykłady marek RDBMS, które obsługują składnię CTE. Oracle ma również własne rozszerzenie składni SQL, które obsługuje zapytania rekurencyjne.
-
Zestawy zagnieżdżone (rozwiązanie lewe/prawe, o którym wspomina @phantombrain) jest rozwiązaniem szczegółowo opisanym w książce Joe Celko „Trees and Hierarchies in SQL for Smarties”, a także w licznych artykułach i wpisach na blogach w Internecie.
-
Wyliczanie ścieżek (aka Materialized Path) przechowuje ciąg w każdym wierszu w hierarchii, aby zanotować ścieżkę przodków tego wiersza. Połącz to z
LIKEzapytania, aby porównać ciąg ścieżki ze ścieżkami przodków i potomków. -
Tabela zamknięcia (aka Transitive Closure Relation) używa drugiej tabeli do przechowywania wszystkich relacji przodek-potomek, a nie tylko bezpośredniego rodzica, jak w projekcie, którego używasz. Wiele typów zapytań staje się prostszych, gdy masz zapisane wszystkie ścieżki.
-
Rozwiązania hybrydowe również istnieją. Na przykład przechowuj identyfikator bezpośredniego rodzica, jak robisz, ale także korzeń drzewa. Teraz możesz pobrać wszystkie inne wiersze w tej samej hierarchii, pobrać je do kodu aplikacji i uporządkować drzewo za pomocą konwencjonalnych struktur danych.