SQL Server istnieje od ponad 30 lat, a ja pracuję z SQL Server prawie tak samo długo. Kalen omawia skanowanie w części pierwszej SQL Server Internals:Problematic Operators.
Widziałem wiele zmian na przestrzeni lat (i dziesięcioleci!) i wersji tego niesamowitego produktu. W tych postach podzielę się z Wami tym, jak patrzę na niektóre funkcje lub aspekty SQL Server, czasami wraz z odrobiną perspektywy historycznej.
Dostrajanie zapytań programu SQL Server to jedna z najlepszych rzeczy, jakie można zrobić, aby uzyskać lepszą wydajność i zoptymalizować diagnostykę serwera SQL. Ale tuning to ogromny temat! Dokładna wiedza o tym, jak dostroić się w najlepszy możliwy sposób, wymaga nie tylko gruntownej znajomości danych i obciążenia, ale także wiedzy o tym, w jaki sposób SQL Server faktycznie dokonuje wyborów dotyczących wykonania planu. Co więc możesz zrobić, jeśli nie jesteś ekspertem w zakresie wewnętrznych elementów SQL Server? Jedyne, co możesz zrobić, to polegać na ludziach, którzy są ekspertami, a także na narzędziach napisanych przez ekspertów. Narzędzia takie jak Quest Spotlight Cloud Tuning Pack mogą dać Ci kilka świetnych sugestii, jak rozpocząć drogę do lepszej wydajności zapytań. Oczywiście żadne zewnętrzne narzędzie nie zna Twoich danych i wszystkich szczegółów wszystkich Twoich obciążeń, dlatego zawsze zalecane jest dokładne testowanie wszelkich sugestii, które zdecydujesz się wdrożyć.
W tych postach dotyczących problematycznych operatorów zakładam, że masz podstawową wiedzę na temat struktur indeksów SQL Server. Oto kilka przydatnych informacji:
- Tabela bez indeksu klastrowego nazywana jest stertą i nie ma kolejności. Nie ma pierwszego ani ostatniego wiersza. Sterta to tylko kilka rzędów w dowolnej kolejności.
- Poziomem liścia indeksu klastrowego jest sama tabela. (To nie jest kopia tabeli, to JEST tabela.) Wiersze indeksu są logicznie uporządkowane według dowolnej kolumny zdefiniowanej jako klucz indeksu klastrowego.
- Poziom liścia indeksu nieklastrowego zawiera wiersz indeksu dla każdego wiersza w tabeli. Wiersze zawierają nieklastrowane kolumny kluczy i są logicznie uporządkowane w kolejności, w jakiej są określone klucze. Oprócz kolumn kluczowych nieklastrowane wiersze indeksu zawierają „zakładkę”, która wskazuje na odwoływany wiersz w tabeli. Zakładka może mieć jedną z dwóch form:
- Jeśli tabela ma indeks klastrowy, zakładka jest kluczem indeksu klastrowego. (Jeśli klucz indeksu klastrowego jest częścią klucza indeksu nieklastrowego, nie zostanie zduplikowany).
- Jeśli tabela jest stertą, zakładka jest identyfikatorem wiersza lub identyfikatorem RID, który określa fizyczną lokalizację wiersza. Lokalizacja jest zwykle określana jako FileNum:PageNum:RowNum .
Własne narzędzia SQL Server zapewniają wiele sposobów przeglądania planu wykonania zapytania, który optymalizator zdecydował się użyć dla konkretnego zapytania. Po dodaniu pakietu Quest Spotlight Tuning Pack możesz uzyskać jeszcze więcej informacji o swoich planach.
Poniższy kod tworzy kopie dwóch tabel w AdventureWorks baza danych (używam AdventureWorks2016 , ale możesz użyć innej wersji).
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS SalesHeader;
GO
SELECT *
INTO SalesHeader
FROM Sales.SalesOrderHeader;
GO
DROP TABLE IF EXISTS SalesDetail;
GO
SELECT * INTO SalesDetail
FROM Sales.SalesOrderDetail;
GO
Teraz wykonaj zapytanie, które łączy dwie tabele razem, po włączeniu opcji „Uwzględnij rzeczywisty plan wykonania”
SELECT h.SalesOrderID, OrderDate, ProductID, UnitPrice, OrderQty
FROM SalesHeader h JOIN SalesDetail d
ON h.SalesOrderID = d.SalesOrderID
WHERE SalesOrderDetailID < 100;
GO
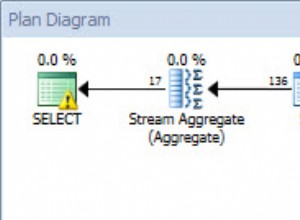
Quest Spotlight Tuning Pack zgłosi problem z zapytaniem, więc możesz kliknąć „Wyświetl analizę” i wybrać opcję „Plan wykonania”. Powinieneś zobaczyć następujące informacje:

Zrozumienie skanowania tabeli
Po pierwsze, chcę wyjść na kończynę i powiedzieć, że nie ma operatora planu, który zawsze jest zły! Dlaczego optymalizator miałby go dodać do planu zapytań, jeśli był zły? Może to wskazywać, że istnieje pole do poprawy w strukturze danych lub indeksów, ale samo w sobie nie jest złe.
W powyższym przykładzie pakiet Tuning Pack wydaje się zwracać uwagę na skany tabeli, wskazując, że mogą być problematyczne. Ale nie zawsze jest prawdą, że skanowanie tabel jest problematyczne. Znacznie gorszą sytuacją byłoby użycie indeksu nieklastrowego do wyszukiwania zapytania, które uzyskuje dostęp do każdego wiersza w tabeli. W przypadku tego konkretnego zapytania zgadzam się, że skanowanie może nie być dobrym rozwiązaniem, ponieważ interesuje nas tylko kilka wierszy w Szczegóły sprzedaży tabela (99 z 121 317 wierszy, czyli mniej niż jedna dziesiąta procenta).
Możemy więc przyjrzeć się sugestiom w okienku Analiza dotyczącym budowania indeksów. Sugestia Szczegóły sprzedaży tabela ma na celu zbudowanie indeksu nieklastrowego na SalesOrderID kolumna (kolumna w klauzuli JOIN) i INCLUDE każdą inną kolumnę w tabeli, która jest zwracana przez zapytanie. Sugestia dotycząca SalesHeader tabela jest indeksem nieklastrowym w SalesOrderDetailId kolumna, która jest kolumną w klauzuli WHERE, i ZAWIERA Data zamówienia kolumna, która jest jedyną inną kolumną zwróconą z tej tabeli.
Co by było, gdyby nasze zapytanie było nieco inne? Co by było, gdybym uruchomił to zapytanie za pomocą SELECT * zamiast określonej listy kolumn. Jeśli spróbujesz tego i spojrzysz na zalecenia, sugeruje użycie INCLUDE dla każdej kolumny w tabeli innej niż pojedyncza kolumna klucza. Chociaż taki indeks może sprawić, że to konkretne zapytanie będzie działać nieco szybciej, może to spowolnić inne zapytania, w szczególności zapytania UPDATE. Ten indeks w zasadzie jest tylko kopią tabeli, ponieważ poziom liścia indeksu będzie zawierał każdą pojedynczą kolumnę w tabeli. Jeśli widzisz takie rekomendacje, sugerujące indeks, który zawiera wszystkie kolumny w tabeli, zdecydowanie polecam cofnąć się nieco i nie tworzyć go na ślepo.
Dostrajanie zapytań do diagnostyki serwera SQL obejmuje nie tylko zarządzanie indeksami, ale także zarządzanie samymi zapytaniami. W przypadku tego konkretnego zapytania lepiej byłoby przepisać zapytanie tak, aby NIE używało SELECT * do zwracania każdego wiersza w tabeli. Zwrócenie tylko małego podzbioru kolumn może wystarczyć, a wtedy wystarczyłby znacznie węższy indeks, jak w pierwszym przykładzie.
Czy któryś z tych indeksów rzeczywiście byłby dobrym indeksem do stworzenia? Węższy indeks będzie ogólnie mniejszy i aktualizacje danych będą miały na niego mniejszy wpływ. Indeks we wszystkich kolumnach jest jak druga kopia tabeli, posortowana w innej kolejności niż sama tabela. Istnieją sytuacje, w których posiadanie „drugiej kopii” tabeli w innej kolejności może być przydatne, ale operacje modyfikacji danych będą wiązały się z dużym obciążeniem. Jedynym sposobem, aby mieć pewność, że to wypróbowanie zaleceń w systemie testowym z reprezentatywnym obciążeniem. Tylko Ty znasz swoje dane i zapytania, więc spróbuj i zobacz!
Zrozumienie skanowania indeksu
Jak wspomniałem powyżej, skanowanie tabel nie zawsze jest czymś złym. Ale co ze skanowaniem indeksów? Ponieważ poziomem liścia indeksu klastrowanego jest sama tabela, skanowanie indeksu klastrowego jest takie samo jak skanowanie tabeli! jeśli skanowanie tabeli jest złe, skanowanie indeksu klastrowego jest równie złe. Ale nie zawsze jest źle. Ponownie musisz przetestować go w swoim systemie.
Rekomendacje silnika SQL Server, które Quest Spotlight Tuning Pack pokazuje, nigdy nie sugerują indeksu klastrowego. może sugerować nieklastrowaną, która obejmuje każdą kolumnę w tabeli (jak wspomniano wcześniej), która jest tylko duplikatem tabeli. Ustalenie najlepszej kolumny lub kolumn dla indeksu klastrowego jest samo w sobie dużym tematem, więc nie będę się tym tutaj zajmować.
Czym jest poszukiwanie? Operacja wyszukiwania w planie oznacza, że SQL Server używa uporządkowanych danych w drzewie indeksu do znalezienia wiersza, zestawu wierszy lub punktu początkowego i/lub końcowego w zakresie wierszy. Ogólnie rzecz biorąc, użycie nieklastrowego wyszukiwania indeksu jest całkowicie rozsądną operacją, jeśli zwracasz tylko bardzo mały procent wierszy z tabeli. Wyszukiwanie nie jest jednak dobrym wyborem w przypadku zapytania, które zwraca DUŻO wierszy z tabeli. Ile to LOTÓW? Nie ma prostej odpowiedzi, ale jeśli zapytanie zwraca więcej niż kilka procent wierszy, należy dokładnie przetestować sugestie indeksu. Czasami skanowanie tabeli lub skanowanie indeksu klastrowego jest lepsze niż wyszukiwanie indeksu. (Jeden z takich przykładów można znaleźć w moim wpisie na blogu tutaj).
Narzędzia, takie jak Pakiet dostrajania Quest Spotlight może dać Ci świetne sugestie dotyczące rozpoczęcia procesu strojenia z diagnostyką serwera SQL, ale im więcej wiesz o tym, jak działają indeksy SQL Server i optymalizator SQL Server, tym lepiej będziesz w stanie ocenić te sugestie dla zapytań i dane, a być może nawet wymyślisz własne sugestie.
W kolejnych postach z tej serii opowiem Ci o innych problematycznych operatorach, które mogą pojawić się w Twoich planach zapytań, więc sprawdź ponownie wkrótce!