UTF-8 to (ogólnie) „bezpieczne” kodowanie dla dowolnego zestawu znaków na świecie. (Nie zawsze jest to najbardziej wydajne i istnieją pewne argumenty, że Unicode niedostatecznie reprezentuje skrypty CJK ze swoim modelem „zunifikowanego han”, ale idziemy dalej…)
Jednak jest prawdopodobne, że program(y) interfejsu nie tłumaczą poprawnie na/z UTF-8. Na przykład ó => ó wygląda na to, że dane UTF-8 (gdzie jeden znak może być rozłożony na różną liczbę bajtów) są prezentowane przy użyciu jednobajtowego kodowania europejskiego, takiego jak ISO-8859-15 lub MS- CP-1451 lub podobny.
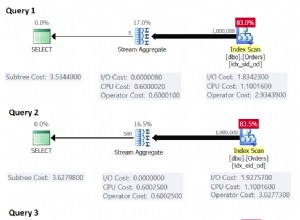
Jesteś prawdopodobnie prawidłowe przechowywanie danych, ale ładowanie to niepoprawnie. Jeśli używasz tylko mysql program terminalowy lub podobny, upewnij się, że twój terminal jest ustawiony na używanie UTF-8 (w systemie Unix/Linux, locale powinno być coś, co kończy się na .utf8 , np. mój ma LANG=en_US.utf8 )
Jeśli pobierasz dane za pomocą narzędzia GUI lub podobnego, sprawdź jego panel Ustawienia/Preferencje dla zestawu znaków.
Jeśli otrzymujesz błędnie przetłumaczone znaki z powrotem do aplikacji, którą napisałeś, spójrz na narzędzia swojego języka do ustawienia ustawień regionalnych. (Być może INSERT procedury mają rację, ale SELECT rutyny mają to źle?)
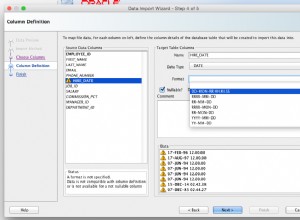
A jeśli jest wysyłany do sieci, upewnij się, że twoje pliki (XML|HTML|XHTML) mają charset=utf8 zadeklarowane w odpowiednim miejscu (miejscach), lub przetłumacz z powrotem z UTF-8 na zestaw znaków twojego dokumentu (jeśli to możliwe), używając czegoś takiego jak iconv podczas wstawiania tekstu z bazy danych. (Większość zestawów znaków innych niż Unicode może oczywiście reprezentować tylko podzbiór Unicode; np. zestaw ISO-8859-15 dobrze radzi sobie z obsługą języków europejskich, ale nie obsługuje systemów pisania cyrylicą, arabskim lub CJK, więc możliwe jest niepowodzenie przetłumaczenia znaku.) W Perlu możesz użyć argumentów przekazywania do open lub użyj binmode aby skonfigurować przezroczystą warstwę tłumaczenia zestawu znaków w strumieniu „uchwytu pliku”.