Kiedy SQL Server optymalizuje zapytanie, podczas fazy eksploracji tworzy plany kandydatów i wybiera spośród nich ten, który ma najniższy koszt. Wybrany plan ma mieć najkrótszy czas działania spośród eksplorowanych planów. Rzecz w tym, że optymalizator może wybierać tylko między strategiami, które zostały w nim zakodowane. Na przykład podczas optymalizacji grupowania i agregacji w dniu pisania tego tekstu optymalizator może wybierać tylko między strategiami Stream Aggregate i Hash Aggregate. Dostępne strategie omówiłem we wcześniejszych częściach tej serii. W części 1 omówiłem wcześniej zamówioną strategię Stream Aggregate, w części 2 strategię Sort + Stream Aggregate, w części 3 strategię Hash Aggregate, a w części 4 rozważania dotyczące paralelizmu.
To, czego obecnie nie obsługuje optymalizator SQL Server, to dostosowywanie i sztuczna inteligencja. Oznacza to, że jeśli potrafisz wymyślić strategię, która w pewnych warunkach jest bardziej optymalna niż te, które obsługuje optymalizator, nie możesz ulepszyć optymalizatora, aby go obsługiwał, a optymalizator nie może nauczyć się go używać. Możesz jednak przepisać zapytanie, używając alternatywnych elementów zapytania, które można zoptymalizować pod kątem strategii, którą masz na myśli. W tej piątej i ostatniej części serii demonstruję tę technikę dostrajania zapytań za pomocą wersji zapytań.
Wielkie podziękowania dla Paula White (@SQL_Kiwi) za pomoc w niektórych kalkulacjach kosztów przedstawionych w tym artykule!
Podobnie jak w poprzednich częściach serii, skorzystam z przykładowej bazy danych PerformanceV3. Użyj następującego kodu, aby usunąć niepotrzebne indeksy z tabeli Zamówienia:
DROP INDEX idx_nc_sid_od_cid NA dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid NA dbo.Orders;
Domyślna strategia optymalizacji
Rozważ następujące podstawowe zadania grupowania i agregacji:
Zwróć maksymalną datę zamówienia dla każdego nadawcy, pracownika i klienta.
Aby uzyskać optymalną wydajność, tworzysz następujące indeksy pomocnicze:
UTWÓRZ INDEKS idx_sid_od NA dbo.Zamówienia(shipperid, data zamoPoniżej znajdują się trzy zapytania, których można użyć do obsługi tych zadań, wraz z szacowanymi kosztami poddrzewa, a także statystykami we/wy, procesora i czasu, który upłynął:
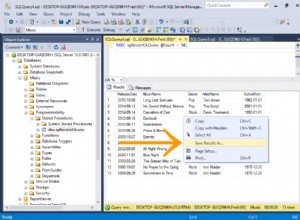
-- Zapytanie 1-- Szacowany koszt poddrzewa:3,5344-- odczyty logiczne:2484, czas procesora:281 ms, czas, który upłynął:279 ms SELECT shipperid, MAX(data zamówienia) AS maxodFROM dbo.OrdersGROUP BY shipperid; -- Zapytanie 2 -- Szacowany koszt poddrzewa:3.62798 -- odczyty logiczne:2610, czas procesora:250 ms, czas, który upłynął:283 ms SELECT empid, MAX(data zamówienia) AS maxodFROM dbo.OrdersGROUP BY empid; -- Zapytanie 3 -- Szacowany koszt poddrzewa:4.27624 -- odczyty logiczne:3479, czas procesora:406 ms, czas, który upłynął:506 ms SELECT custid, MAX(data zamówienia) AS maxodFROM dbo.OrdersGROUP BY custid;Rysunek 1 przedstawia plany dla tych zapytań:
Rysunek 1:Plany zapytania zgrupowane
Przypomnij sobie, że jeśli masz indeks pokrywający, z kolumnami zestawu grupującego jako wiodącymi kolumnami kluczowymi, po których następuje kolumna agregacji, SQL Server prawdopodobnie wybierze plan, który wykona uporządkowane skanowanie indeksu pokrywającego obsługującego strategię Stream Aggregate . Jak widać na planach przedstawionych na rysunku 1, operator skanowania indeksów jest odpowiedzialny za większość kosztów planu, aw jego ramach najbardziej widoczna jest część we/wy.
Zanim przedstawię alternatywną strategię i wyjaśnię okoliczności, w których jest ona bardziej optymalna niż strategia domyślna, oszacujmy koszt istniejącej strategii. Ponieważ część I/O jest najbardziej dominująca w określaniu kosztu planu tej domyślnej strategii, najpierw oszacujmy, ile logicznych odczytów stron będzie wymaganych. Później oszacujemy również koszt planu.
Aby oszacować liczbę logicznych odczytów wymaganych przez operatora skanowania indeksu, musisz wiedzieć, ile wierszy masz w tabeli i ile wierszy mieści się na stronie w oparciu o rozmiar wiersza. Gdy masz te dwa operandy, twoja formuła dla wymaganej liczby stron na poziomie liścia indeksu to CEILING(1e0 * @numrows / @rowsperpage). Jeśli wszystko, co masz, to tylko struktura tabeli i brak istniejących przykładowych danych do pracy, możesz użyć tego artykułu, aby oszacować liczbę stron, które miałbyś na poziomie liścia indeksu pomocniczego. Jeśli masz dobre reprezentatywne dane przykładowe, nawet jeśli nie w tej samej skali, co w środowisku produkcyjnym, możesz obliczyć średnią liczbę wierszy, które mieszczą się na stronie, wysyłając zapytania do katalogu i obiektów dynamicznego zarządzania, na przykład:
SELECT I.name, row_count, in_row_data_page_count, CAST (ROUND (1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage FROM sys.indexes AS I INNER JOIN sys.dm_db_partition_stats AS P ON I.object_id AND I.index_id =P.index_id GDZIE I.object_id =OBJECT_ID('dbo.Orders') AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od');To zapytanie generuje następujące dane wyjściowe w naszej przykładowej bazie danych:
name liczba_wierszów in_liczba_row_danych_strona_growsperpage ----------- ---------- ----------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289Teraz, gdy masz już liczbę wierszy, które mieszczą się na stronie liścia indeksu, możesz oszacować całkowitą liczbę stron liści w indeksie na podstawie oczekiwanej liczby wierszy w tabeli produkcyjnej. Będzie to również oczekiwana liczba odczytów logicznych do zastosowania przez operator skanowania indeksu. W praktyce liczba odczytów, które mogą mieć miejsce, to nie tylko liczba stron na poziomie liścia indeksu, na przykład dodatkowe odczyty generowane przez mechanizm odczytu z wyprzedzeniem, ale zignoruję je, aby nasza dyskusja była prosta .
Na przykład szacowana liczba odczytów logicznych dla Zapytania 1 w odniesieniu do oczekiwanej liczby wierszy wynosi CEILING(1e0 * @numorws / 404). Przy 1 000 000 wierszy oczekiwana liczba odczytów logicznych wynosi 2476. Różnicę między 2476 a podaną w wierszu liczbą stron wynoszącą 2473 można przypisać zaokrągleniu, które wykonałem podczas obliczania średniej liczby wierszy na stronę.
Jeśli chodzi o koszt planu, wyjaśniłem, jak odtworzyć koszt operatora Stream Aggregate w części 1 serii. W podobny sposób można przeprowadzić inżynierię wsteczną kosztów operatora skanowania indeksu. Koszt planu jest zatem sumą kosztów operatorów Index Scan i Stream Aggregate.
Aby obliczyć koszt operatora skanowania indeksowego, należy rozpocząć od inżynierii wstecznej niektórych ważnych stałych modelu kosztów:
@randomio =0,003125 -- Losowy koszt we/wy@seqio =0,000740740740740741 -- Koszt sekwencyjnego we/wy@cpubase =0,000157 -- Podstawowy koszt procesora@cpurow =0,0000011 -- Koszt procesora na wierszMając ustalone powyższe stałe modelu kosztów, możesz przejść do inżynierii wstecznej wzorów na koszt we/wy, koszt procesora i całkowity koszt operatora dla operatora skanowania indeksowego:
Koszt we/wy:@randomio + (@numpages - 1e0) * @seqio =0,003125 + (@numpages - 1e0) * 0.000740740740741Koszt procesora:@cpubase + @numrows * @cpurow =0.000157 + @numrows * 0.0000011Operator koszt:0,002541259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000011Na przykład koszt operatora skanowania indeksu dla zapytania 1, z 2473 stronami i 1 000 000 wierszami, wynosi:
0,002541259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000011 =2,93439Poniżej znajduje się formuła inżynierii odwrotnej dla kosztu operatora Stream Aggregate:
0.000008 + @numrows * 0,0000006 + @numgroups * 0,0000005Na przykład dla zapytania 1 mamy 1 000 000 wierszy i 5 grup, stąd szacowany koszt to 0,6000105.
Łącząc koszty dwóch operatorów, oto wzór na cały koszt planu:
0,002549259259259 + @numpages * 0,000740740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005W przypadku zapytania 1, z 2473 stronami, 1 000 000 wierszami i 5 grupami, otrzymujesz:
0,002549259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,0000005 =3,5344Jest to zgodne z tym, co pokazuje Rysunek 1 jako szacunkowy koszt dla Zapytania 1.
Jeśli oparłeś się na szacunkowej liczbie wierszy na stronie, Twoja formuła będzie wyglądać tak:
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740740741 + @numrows * 0,0000017 + @numgroups * 0,000005Na przykład dla zapytania 1, z 1 000 000 wierszy, 404 wierszami na stronę i 5 grupami, szacowany koszt to:
0,002549259259259 + SUFIT (1e0 * 1000000 / 404) * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,0000005 =3,5366W ramach ćwiczenia możesz zastosować liczby z Zapytania 2 (1 000 000 wierszy, 385 wierszy na stronę, 500 grup) i Zapytania 3 (1 000 000 wierszy, 289 wierszy na stronę, 20 000 grup) w naszej formule i sprawdzić, czy wyniki są zgodne z Rysunek 1 pokazuje.
Dostrajanie zapytań za pomocą przepisywania zapytań
Domyślna strategia Stream Aggregate zamówiona w przedsprzedaży do obliczania agregatu MIN/MAX na grupę opiera się na uporządkowanym skanowaniu pomocniczego indeksu pokrycia (lub innej wstępnej aktywności, która emituje uporządkowane wiersze). Alternatywną strategią, z obecnym pomocniczym indeksem pokrycia, byłoby przeprowadzenie wyszukiwania indeksu na grupę. Oto opis pseudo planu opartego na takiej strategii dla zapytania grupującego według grpcol i stosującego MAX(aggcol):
set @curgrpcol =grpcol z pierwszego wiersza uzyskanego przez skanowanie indeksu, uporządkowane w przód;podczas gdy koniec indeksu nieosiągniętybegin set @curagg =aggcol z wiersza uzyskanego przez wyszukiwanie do ostatniego punktu, w którym grpcol =@curgrpcol, uporządkowany do tyłu; emituj wiersz (@curgrpcol, @curagg); set @curgrpcol =grpcol od wiersza na prawo od ostatniego wiersza dla bieżącej grupy;koniec;Jeśli się nad tym zastanowić, domyślna strategia oparta na skanowaniu jest optymalna, gdy zestaw grupujący ma niską gęstość (duża liczba grup, przy średniej małej liczbie wierszy na grupę). Strategia oparta na wyszukiwaniach jest optymalna, gdy zestaw grupujący ma dużą gęstość (mała liczba grup, przy średniej dużej liczbie wierszy na grupę). Rysunek 2 ilustruje obie strategie pokazujące, kiedy każda z nich jest optymalna.
Rysunek 2:Optymalna strategia w oparciu o gęstość zestawu grupowania
Tak długo, jak piszesz rozwiązanie w formie grupowanego zapytania, obecnie SQL Server będzie brał pod uwagę tylko strategię skanowania. Będzie to działać dobrze, gdy zestaw grupujący ma niską gęstość. Gdy masz wysoką gęstość, aby uzyskać strategię wyszukiwania, będziesz musiał zastosować przepisanie zapytania. Jednym ze sposobów osiągnięcia tego jest wykonanie zapytania do tabeli zawierającej grupy i użycie podzapytania agregacji skalarnej względem tabeli głównej w celu uzyskania agregacji. Na przykład, aby obliczyć maksymalną datę zamówienia dla każdego nadawcy, należy użyć następującego kodu:
SELECT shipperid, ( SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC ) AS maxod FROM dbo.Shippers AS S;Wytyczne indeksowania dla głównej tabeli są takie same, jak te, które wspierają domyślną strategię. Mamy już te indeksy dla trzech wyżej wymienionych zadań. Prawdopodobnie będziesz potrzebować również indeksu pomocniczego w kolumnach zestawu grupującego w tabeli zawierającej grupy, aby zminimalizować koszt we/wy względem tej tabeli. Użyj następującego kodu, aby utworzyć takie indeksy pomocnicze dla naszych trzech zadań:
UTWÓRZ INDEKS idx_sid NA dbo.Shippers(shipperid);UTWÓRZ INDEKS idx_eid NA dbo.Employees(empid);UTWÓRZ INDEKS idx_cid NA dbo.Klienci(custid);Jeden mały problem polega jednak na tym, że rozwiązanie oparte na podzapytaniu nie jest dokładnym logicznym odpowiednikiem rozwiązania opartego na zapytaniu zgrupowanym. Jeśli masz grupę, której nie ma w tabeli głównej, ta pierwsza zwróci grupę z wartością NULL jako agregatem, podczas gdy ta druga w ogóle nie zwróci grupy. Prostym sposobem uzyskania prawdziwego logicznego odpowiednika zapytania zgrupowanego jest wywołanie podzapytania za pomocą operatora CROSS APPLY w klauzuli FROM zamiast używania podzapytania skalarnego w klauzuli SELECT. Pamiętaj, że CROSS APPLY nie zwróci lewego wiersza, jeśli zastosowane zapytanie zwróci pusty zestaw. Oto trzy zapytania o rozwiązania wdrażające tę strategię dla naszych trzech zadań, wraz z ich statystykami wydajności:
— Zapytanie 4 — Szacowany koszt poddrzewa:0,0072299 — odczyty logiczne:2 + 15, czas procesora:0 ms, czas, który upłynął:43 ms SELECT S.shipperid, A.orderdate AS maxod FROM dbo.Shippers AS S CROSS APPLY ( SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC ) AS A; -- Zapytanie 5 -- Szacowany koszt poddrzewa:0,089694 -- odczyty logiczne:2 + 1620, czas procesora:0 ms, czas, który upłynął:148 ms SELECT E.empid, A.orderdate AS maxod FROM dbo.Pracownicy AS E CROSS APPLY ( SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.empid =E.empid ORDER BY O.orderdate DESC ) AS A; -- Zapytanie 6 -- Szacowany koszt poddrzewa:3,5227 -- odczyty logiczne:45 + 63777, czas procesora:171 ms, czas, który upłynął:306 ms SELECT C.custid, A.orderdate AS maxod FROM dbo.Klienci AS C CROSS APPLY ( SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.custid =C.custid ORDER BY O.orderdate DESC ) AS A;Plany dla tych zapytań pokazano na rysunku 3.
Rysunek 3:Plany zapytania z przepisaniem
Jak widać, grupy uzyskuje się poprzez skanowanie indeksu w tabeli grup, a agregat uzyskuje się poprzez zastosowanie wyszukiwania w indeksie w tabeli głównej. Im wyższa gęstość zestawu grupującego, tym bardziej optymalny jest ten plan w porównaniu z domyślną strategią dla zgrupowanego zapytania.
Tak jak wcześniej zrobiliśmy dla domyślnej strategii skanowania, oszacujmy liczbę odczytów logicznych i zaplanujmy koszt strategii wyszukiwania. Szacowana liczba odczytów logicznych to liczba odczytów dla pojedynczego wykonania operatora Index Scan, który pobiera grupy, plus odczyty dla wszystkich wykonań operatora Index Seek.
Szacowana liczba odczytów logicznych dla operatora skanowania indeksu jest nieistotna w porównaniu z wyszukiwaniami; nadal jest to SUFIT (1e0 * @numgroups / @rowsperpage). Weźmy jako przykład zapytanie 4; powiedzmy, że indeks idx_sid mieści około 600 wierszy na stronę liścia (rzeczywista liczba zależy od rzeczywistych wartości dostawcy, ponieważ typem danych jest VARCHAR(5)). W przypadku 5 grup wszystkie wiersze mieszczą się na jednej kartce. Gdybyś miał 5000 grup, zmieściłyby się one na 9 stronach.
Szacowana liczba odczytów logicznych dla wszystkich wykonań operatora wyszukiwania indeksu wynosi @numgroups * @indexdepth. Głębokość indeksu można obliczyć jako:
SUFITOWY(DZIENNIK(POWIERZCHNIA(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1Używając Query 4 jako przykładu, powiedzmy, że możemy zmieścić około 404 wierszy na stronę liścia o indeksie idx_sid_od i około 352 wierszy na stronę bez liścia. Ponownie, rzeczywiste liczby będą zależeć od rzeczywistych wartości przechowywanych w kolumnie shipperid, ponieważ jej typ danych to VARCHAR(5)). W przypadku szacunków pamiętaj, że możesz skorzystać z opisanych tutaj obliczeń. Mając dostępne dobre reprezentatywne dane przykładowe, możesz użyć następującego zapytania, aby obliczyć liczbę wierszy, które mogą zmieścić się na stronach liścia i bez liści danego indeksu:
SELECT CASE P.index_level WHEN 0 THEN 'liść' WHEN 1 THEN 'nonleaf' END AS typ strony, FLOOR (8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage FROM (SELECT * FROM sys.indexes WHERE object_id =OBJECT_ID ('dbo.Orders') AND name ='idx_sid_od') JAK PRZEKROCZYĆ ZASTOSUJ sys.dm_db_index_physical_stats (DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P WHERE P.index_level <=1;Otrzymałem następujący wynik:
pagetype rowsperpage -------- ----------- liść 404 bez liści 352Przy tych liczbach głębokość indeksu w odniesieniu do liczby wierszy w tabeli wynosi:
SUFIT(DZIENNIK(SUFIT(1e0 * @numrows / 404), 352)) + 1Przy 1 000 000 wierszy w tabeli daje to głębokość indeksu wynoszącą 3. Przy około 50 milionach wierszy głębokość indeksu wzrasta do 4 poziomów, a przy około 17,62 miliarda wierszy wzrasta do 5 poziomów.
W każdym razie, biorąc pod uwagę liczbę grup i liczbę wierszy, przy założeniu powyższej liczby wierszy na stronę, poniższy wzór oblicza szacowaną liczbę odczytów logicznych dla Zapytania 4:
CEILING(1e0 * @numrows / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)Na przykład, z 5 grupami i 1 000 000 wierszami, otrzymujesz tylko 16 odczytów! Przypomnijmy, że domyślna strategia oparta na skanowaniu dla zapytania zgrupowanego obejmuje tyle odczytów logicznych, co CEILING(1e0 * @numrows / @rowsperpage). Używając zapytania 1 jako przykładu i zakładając około 404 wierszy na stronę liścia o indeksie idx_sid_od, przy tej samej liczbie wierszy wynoszącej 1 000 000, otrzymujesz około 2476 odczytów. Zwiększ liczbę wierszy w tabeli o współczynnik 1000 do 1 000 000 000, ale nie zmieniaj liczby grup. Liczba odczytów wymaganych w przypadku strategii wyszukiwania zmienia się bardzo nieznacznie do 21, podczas gdy liczba odczytów wymaganych w przypadku strategii skanowania wzrasta liniowo do 2 475 248.
Piękno strategii wyszukiwania polega na tym, że tak długo, jak liczba grup jest mała i stała, ma ona prawie stałe skalowanie w odniesieniu do liczby wierszy w tabeli. Dzieje się tak, ponieważ liczba wyszukiwań jest określana przez liczbę grup, a głębokość indeksu odnosi się do liczby wierszy w tabeli w sposób logarytmiczny, gdzie podstawą dziennika jest liczba wierszy, które mieszczą się na stronie nie będącej liściem. I odwrotnie, strategia oparta na skanowaniu ma skalowanie liniowe w odniesieniu do liczby zaangażowanych wierszy.
Rysunek 4 pokazuje liczbę odczytów oszacowaną dla dwóch strategii zastosowanych w Zapytaniu 1 i Zapytaniu 4, przy ustalonej liczbie grup 5 i różnej liczbie wierszy w tabeli głównej.
Rysunek 4:#odczyty dla strategii skanowania kontra poszukiwania (5 grup)
Rysunek 5 pokazuje liczbę odczytów oszacowaną dla dwóch strategii, biorąc pod uwagę stałą liczbę wierszy 1 000 000 w tabeli głównej i różną liczbę grup.
Rysunek 5:#odczyty dla strategii skanowania i wyszukiwania (1 mln wierszy)
Widać bardzo wyraźnie, że im większa gęstość zbioru grupującego (mniejsza liczba grup) i im większa tabela główna, tym bardziej preferowana jest strategia seeks pod względem liczby odczytów. Jeśli zastanawiasz się nad wzorcem I/O używanym przez każdą strategię; oczywiście, operacje wyszukiwania indeksu wykonują losowe operacje we/wy, podczas gdy operacja skanowania indeksu wykonuje sekwencyjne operacje we/wy. Mimo to jest całkiem jasne, która strategia jest bardziej optymalna w bardziej ekstremalnych przypadkach.
Jeśli chodzi o koszt planu zapytań, ponownie, używając jako przykładu planu dla zapytania 4 na rysunku 3, podzielmy go na poszczególne operatory w planie.
Odwrócona formuła kosztu operatora skanowania indeksu to:
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011W naszym przypadku, z 5 grupami, z których wszystkie mieszczą się na jednej stronie, koszt wynosi:
0,002541259259259 + 1 * 0,000740740740741 + 5 * 0,0000011 =0,0032875Koszt pokazany w planie jest taki sam.
Tak jak poprzednio, można oszacować liczbę stron na poziomie liścia indeksu na podstawie szacowanej liczby wierszy na stronę za pomocą formuły CEILING(1e0 * @numrows / @rowsperpage), która w naszym przypadku to CEILING(1e0 * @ numgroups / @groupsperpage). Powiedzmy, że indeks idx_sid mieści około 600 wierszy na stronie liścia, z 5 grupami, których potrzebujesz, aby przeczytać jedną stronę. W każdym razie formuła kosztowa dla operatora skanowania indeksu wygląda następująco:
0,002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740740741 + @numgroups * 0,0000011Formuła kosztów inżynierii odwrotnej dla operatora zagnieżdżonych pętli to:
@wykonania * 0.00000418W naszym przypadku oznacza to:
@numgroups * 0.00000418W przypadku zapytania 4, z 5 grupami, otrzymujesz:
5 * 0,0000418 =0,0000209Koszt pokazany w planie jest taki sam.
Formuła kosztów inżynierii odwrotnej dla operatora Top to:
@wykonania * @toprows * 0,00000001W naszym przypadku oznacza to:
@numgroups * 1 * 0,00000001W przypadku 5 grup otrzymujesz:
5 * 0,000001 =0,0000005Koszt pokazany w planie jest taki sam.
Jeśli chodzi o operator Index Seek, tutaj otrzymałem wielką pomoc od Paula White'a; dzięki, przyjacielu! Obliczenia są inne dla pierwszego wykonania i dla ponownych powiązań (niepierwszych wykonań, które nie wykorzystują ponownie wyniku poprzedniego wykonania). Podobnie jak w przypadku operatora Index Scan, zacznijmy od zidentyfikowania stałych modelu kosztów:
@randomio =0,003125 -- Losowy koszt we/wy @seqio =0.000740740740741 -- Koszt sekwencyjnego we/wy @cpubase =0.000157 -- Podstawowy koszt procesora @cpurow =0,0000011 -- Koszt procesora na wierszW przypadku jednego wykonania, bez zastosowania celu dotyczącego wiersza, koszty we/wy i procesora wynoszą:
Koszt we/wy:@randomio + (@numpages - 1e0) * @seqio =0,002384259259259 + @numpages * 0.000740740740741Koszt procesora:@cpubase + @numrows * @cpurow =0,000157 + @numrows * 0,0000011Ponieważ używamy TOP (1), mamy tylko jedną stronę i jeden wiersz, więc koszty wynoszą:
Koszt we/wy:0,002384259259259 + 1 * 0,000740740740740741 =0,003125 koszt procesora:0,000157 + 1 * 0,0000011 =0,0001581Zatem koszt pierwszego wykonania operatora Index Seek w naszym przypadku wynosi:
@pierwsze wykonanie =0,003125 + 0,0001581 =0,0032831Jeśli chodzi o koszt rebindów, jak zwykle składa się on z kosztów procesora i I/O. Nazwijmy je odpowiednio @rebindcpu i @rebindio. W zapytaniu 4, mającym 5 grup, mamy 4 rebindów (nazwijmy to @rebinds). Koszt @rebindcpu to łatwa część. Wzór to:
@rebindcpu =@rebinds * (@cpubase + @cpurow)W naszym przypadku oznacza to:
@rebindcpu =4 * (0,000157 + 0,0000011) =0,0006324Część @rebindio jest nieco bardziej złożona. Tutaj formuła kosztorysowa oblicza statystycznie oczekiwaną liczbę odrębnych stron, które mają zostać odczytane przez ponowne powiązanie przy użyciu próbkowania z zamianą. Nazwiemy ten element @pswr (dla odrębnych stron próbkowanych z zamianą). Chodzi o to, że mamy @indexdatapages liczbę stron w indeksie (w naszym przypadku 2473) i @rebinds liczbę ponownych wiązań (w naszym przypadku 4). Zakładając, że mamy takie samo prawdopodobieństwo przeczytania dowolnej strony przy każdym ponownym powiązaniu, ile różnych stron mamy w sumie przeczytać? Jest to podobne do posiadania woreczka z 2473 piłkami i czterokrotnego wyciągnięcia piłki na ślepo z torby, a następnie zwrócenia jej do torby. Statystycznie, ile w sumie różnych piłek masz narysować? Wzór na to, używając naszych operandów, jest następujący:
@pswr =@indexdatapages * (1e0 - MOC((@indexdatapages - 1e0) / @indexdatapages, @rebinds))Z naszymi numerami otrzymujesz:
@pswr =2473 * (1e0 - MOC((2473 - 1e0) / 2473, 4)) =3,99757445099277Następnie obliczasz średnią liczbę wierszy i stron na grupę:
@grouprows =@cardiinality * @density@grouppages =SUFIT(@indexdatapages * @density)W naszym pytaniu 4 liczność wynosi 1 000 000, a gęstość wynosi 1/5 =0,2. Otrzymujesz:
@grouprows =1000000 * 0,2 =200000@numpages =SUFIT(2473 * 0,2) =495Następnie obliczasz koszt I/O bez filtrowania (nazwij go @io) jako:
@io =@randomio + (@seqio * (@grouppages - 1e0))W naszym przypadku otrzymujesz:
@io =0,003125 + (0,000740740740741 * (495 - 1e0)) =0,369050925926054I na koniec, ponieważ seek wyodrębnia tylko jeden wiersz w każdym ponownym powiązaniu, obliczasz @rebindio za pomocą następującej formuły:
@rebindio =(1e0 / @grouprows) * ((@pswr - 1e0) * @io)W naszym przypadku otrzymujesz:
@rebindio =(1e0 / 200000) * ((3,99757445099277 - 1e0) * 0,369050925926054) =0,00005531288Wreszcie koszt operatora to:
Koszt operatora:@firstexecution + @rebindcpu + @rebindio =0,0032831 + 0,0006324 + 0,00005531288 =0,003921031288Jest to taki sam, jak koszt operatora wyszukiwania indeksu pokazany w planie dla zapytania 4.
Możesz teraz agregować koszty wszystkich operatorów, aby uzyskać pełny koszt planu zapytania. Otrzymujesz:
Koszt planu zapytań:0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011 + @numgroups * 0.00000418 + @numgroups * 0.00000001 + 0.0032831 + (@numgroups - 1e0) * 0.0001581 + (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage) * (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @ rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0.000740740740741 *) (CEILING((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))Po uproszczeniu otrzymujesz następującą pełną formułę kosztów dla naszej strategii Seeks:
0,005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740740741 + @numgroups * 0,0000011 + @numgroups * 0,00016229 + (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage) ) * (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0.000740740740741 * ( CEILING((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))Jako przykład, używając T-SQL, oto obliczenie kosztu planu zapytania za pomocą naszej strategii Seeks dla zapytania 4:
DECLARE @numrows AS FLOAT =1000000, @numgroups AS FLOAT =5, @rowsperpage AS FLOAT =404, @groupsperpage AS FLOAT =600; SELECT 0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011 + @numgroups * 0.00016229 + (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage) * (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0.000740740740741 * (CEILING() (@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0))) AS seeksplancost;To obliczenie oblicza koszt 0,0072295 dla zapytania 4. Szacowany koszt pokazany na rysunku 3 to 0,0072299. To całkiem blisko! W ramach ćwiczenia oblicz koszty dla Zapytania 5 i Zapytania 6 za pomocą tego wzoru i sprawdź, czy otrzymujesz liczby zbliżone do tych pokazanych na rysunku 3.
Przypomnij sobie, że formuła kosztowa dla domyślnej strategii opartej na skanowaniu to (nazwij się Skanuj strategia):
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740740741 + @numrows * 0,0000017 + @numgroups * 0,000005Używając zapytania 1 jako przykładu i zakładając 1 000 000 wierszy w tabeli, 404 wierszy na stronę i 5 grup, szacowany koszt planu zapytania dla strategii skanowania wynosi 3,5366.
Rysunek 6 pokazuje szacunkowe koszty planu zapytań dla dwóch strategii, zastosowanych w Zapytaniu 1 (skanowanie) i Zapytaniu 4 (wyszukiwania), przy ustalonej liczbie grup po 5 i różnej liczbie wierszy w tabeli głównej.
Rysunek 6:koszt strategie skanowania kontra poszukiwania (5 grup)
Rysunek 7 pokazuje szacunkowe koszty planu zapytań dla dwóch strategii, biorąc pod uwagę stałą liczbę wierszy w głównej tabeli wynoszącą 1 000 000 i różną liczbę grup.
Rysunek 7:koszt strategie skanowania a wyszukiwania (1 mln wierszy)
Jak wynika z tych ustaleń, im wyższa gęstość zestawu grupowania i im więcej wierszy w głównej tabeli, tym bardziej optymalna jest strategia wyszukiwania w porównaniu ze strategią skanowania. Dlatego w scenariuszach o dużej gęstości wypróbuj rozwiązanie oparte na ZASTOSUJ. W międzyczasie możemy mieć nadzieję, że Microsoft doda tę strategię jako wbudowaną opcję dla zapytań grupowych.
Wniosek
Ten artykuł kończy pięcioczęściową serię dotyczącą progów optymalizacji zapytań dla zapytań grupujących i agregujących dane. Jednym z celów serii było omówienie specyfiki różnych algorytmów, z których może korzystać optymalizator, warunków, w których każdy algorytm jest preferowany, oraz kiedy należy interweniować w przypadku przepisywania własnych zapytań. Kolejnym celem było wyjaśnienie procesu odkrywania różnych opcji i ich porównywania. Oczywiście ten sam proces analizy można zastosować do filtrowania, łączenia, okienkowania i wielu innych aspektów optymalizacji zapytań. Mamy nadzieję, że teraz czujesz się lepiej przygotowany do radzenia sobie z dostrajaniem zapytań niż wcześniej.