Bazy danych są projektowane na różne sposoby. W większości przypadków możemy używać „przykładów szkolnych”:znormalizuj bazę danych i wszystko będzie działać dobrze. Ale są sytuacje, które będą wymagały innego podejścia. Możemy usunąć odniesienia, aby uzyskać większą elastyczność. Ale co, jeśli musimy poprawić wydajność, gdy wszystko zostało zrobione zgodnie z książką? W takim przypadku denormalizacja jest techniką, którą powinniśmy rozważyć. W tym artykule omówimy zalety i wady denormalizacji oraz jakie sytuacje mogą ją uzasadniać.
Co to jest denormalizacja?
Denormalizacja to strategia stosowana na wcześniej znormalizowanej bazie danych w celu zwiększenia wydajności. Ideą, która się za tym kryje, jest dodanie zbędnych danych tam, gdzie naszym zdaniem pomoże nam to najbardziej. Możemy użyć dodatkowych atrybutów w istniejącej tabeli, dodać nowe tabele, a nawet stworzyć instancje istniejących tabel. Zwykłym celem jest skrócenie czasu wykonywania zapytań wybierających poprzez zwiększenie dostępności danych dla zapytań lub generowanie podsumowanych raportów w osobnych tabelach. Ten proces może spowodować nowe problemy, które omówimy później.
Znormalizowana baza danych jest punktem wyjścia dla procesu denormalizacji. Ważne jest, aby odróżnić bazę danych, która nie została znormalizowana, od bazy danych, która została najpierw znormalizowana, a później zdenormalizowana. Drugi jest w porządku; pierwszy jest często wynikiem złego projektu bazy danych lub braku wiedzy.
Przykład:znormalizowany model bardzo prostego CRM
Poniższy model posłuży jako nasz przykład:
Rzućmy okiem na tabele:
user_accounttabela przechowuje dane o użytkownikach, którzy logują się do naszej aplikacji (uproszczenie modelu, role i prawa użytkowników są z niej wyłączone).clienttabela zawiera podstawowe dane o naszych klientach.producttabela zawiera listę produktów oferowanych naszym klientom.tasktabela zawiera wszystkie utworzone przez nas zadania. Możesz myśleć o każdym zadaniu jako zestawie powiązanych działań wobec klientów. Każde zadanie ma powiązane rozmowy telefoniczne, spotkania oraz listy oferowanych i sprzedawanych produktów.callimeetingtabele przechowują dane o wszystkich połączeniach i spotkaniach oraz wiążą je z zadaniami i użytkownikami.- Słowniki
task_outcome,meeting_outcomeicall_outcomezawierać wszystkie możliwe opcje końcowego stanu zadania, spotkania lub rozmowy. product_offeredprzechowuje listę wszystkich produktów, które były oferowane klientom w określonych zadaniach, podczas gdyproduct_soldzawiera listę wszystkich produktów, które klient faktycznie kupił.supply_ordertabela przechowuje dane o wszystkich złożonych przez nas zamówieniach orazproducts_on_ordertabela zawiera listę produktów i ich ilości dla określonych zamówień.writeofftabela to lista produktów, które zostały skreślone z powodu wypadków lub podobnych (np. zepsutych lusterek).
Baza danych jest uproszczona, ale doskonale znormalizowana. Nie znajdziesz żadnych zwolnień i to powinno wystarczyć. W żadnym wypadku nie powinniśmy mieć problemów z wydajnością, o ile pracujemy ze stosunkowo niewielką ilością danych.
Kiedy i dlaczego stosować denormalizację
Jak prawie wszystko, musisz być pewien, dlaczego chcesz zastosować denormalizację. Musisz mieć również pewność, że zysk z jego używania przewyższa wszelkie szkody. Jest kilka sytuacji, w których zdecydowanie powinieneś pomyśleć o denormalizacji:
- Utrzymywanie historii: Dane mogą się zmieniać w czasie i musimy przechowywać wartości, które były ważne w momencie tworzenia rekordu. Jakie zmiany mamy na myśli? Cóż, imię i nazwisko osoby może się zmienić; Klient może również zmienić nazwę swojej firmy lub dowolne inne dane. Szczegóły zadania powinny zawierać wartości, które były aktualne w momencie generowania zadania. Nie bylibyśmy w stanie poprawnie odtworzyć danych z przeszłości, gdyby tak się nie stało. Moglibyśmy rozwiązać ten problem, dodając tabelę zawierającą historię tych zmian. W takim przypadku zapytanie wybierające zwracające zadanie i prawidłową nazwę klienta stałoby się bardziej skomplikowane. Może dodatkowy stół nie jest najlepszym rozwiązaniem.
- Poprawa wydajności zapytań: Niektóre zapytania mogą korzystać z wielu tabel w celu uzyskania dostępu do często potrzebnych nam danych. Pomyśl o sytuacji, w której musielibyśmy dołączyć do 10 stołów, aby zwrócić nazwę klienta i produkty, które zostały mu sprzedane. Niektóre tabele na ścieżce mogą również zawierać duże ilości danych. W takim przypadku może rozsądnie byłoby dodać
client_idatrybut bezpośrednio doproducts_soldstół. - Przyspieszenie raportowania: Bardzo często potrzebujemy pewnych statystyk. Tworzenie ich z danych na żywo jest dość czasochłonne i może wpłynąć na ogólną wydajność systemu. Załóżmy, że chcemy śledzić sprzedaż klientów w określonych latach dla niektórych lub wszystkich klientów. Generowanie takich raportów z danych na żywo „przekopałoby” prawie całą bazę danych i bardzo ją spowolniło. A co się stanie, jeśli często będziemy korzystać z tych statystyk?
- Obliczanie często potrzebnych wartości z góry: Chcemy mieć gotowe obliczone wartości, więc nie musimy ich generować w czasie rzeczywistym.
Ważne jest, aby podkreślić, że nie musisz używać denormalizacji, jeśli nie ma problemów z wydajnością w aplikacji. Ale jeśli zauważysz, że system zwalnia – lub masz świadomość, że może się to zdarzyć – powinieneś pomyśleć o zastosowaniu tej techniki. Zanim jednak z tym przejdziesz, rozważ inne opcje, takie jak optymalizacja zapytań i prawidłowe indeksowanie. Możesz również użyć denormalizacji, jeśli jesteś już w fazie produkcyjnej, ale lepiej jest rozwiązywać problemy w fazie rozwoju.
Jakie są wady denormalizacji?
Oczywiście największą zaletą procesu denormalizacji jest zwiększona wydajność. Ale musimy za to zapłacić cenę, a ta cena może składać się z:
- Miejsce na dysku: Jest to oczekiwane, ponieważ będziemy mieć zduplikowane dane.
- Anomalie danych: Musimy być bardzo świadomi tego, że dane teraz można zmieniać w więcej niż jednym miejscu. Musimy odpowiednio dostosować każdy element zduplikowanych danych. Dotyczy to również wartości obliczanych i raportów. Możemy to osiągnąć, używając wyzwalaczy, transakcji i/lub procedur dla wszystkich operacji, które muszą być wykonane razem.
- Dokumentacja: Musimy właściwie udokumentować każdą zastosowaną przez nas regułę denormalizacji. Jeśli później zmodyfikujemy projekt bazy danych, będziemy musieli przyjrzeć się wszystkim wyjątkom i jeszcze raz wziąć je pod uwagę. Może już ich nie potrzebujemy, bo rozwiązaliśmy problem. A może musimy dodać do istniejących reguł denormalizacji. (Na przykład:dodaliśmy nowy atrybut do tabeli klienta i chcemy przechowywać jego wartość historyczną razem ze wszystkim, co już przechowujemy. Aby to osiągnąć, będziemy musieli zmienić istniejące reguły denormalizacji).
- Zwalnianie innych operacji: Możemy się spodziewać, że spowolnimy operacje wstawiania, modyfikowania i usuwania danych. Jeśli takie operacje zdarzają się stosunkowo rzadko, może to być korzystne. Zasadniczo podzielilibyśmy jeden powolny wybór na większą liczbę wolniejszych zapytań wstawiania/aktualizowania/usuwania. Chociaż bardzo złożone pod względem technicznym zapytanie wybierające może zauważalnie spowolnić cały system, spowolnienie wielu „mniejszych” operacji nie powinno negatywnie wpłynąć na użyteczność naszej aplikacji.
- Więcej kodowania: Reguły 2 i 3 będą wymagały dodatkowego kodowania, ale jednocześnie znacznie uprościją niektóre zapytania wybierające. Jeśli denormalizujemy istniejącą bazę danych, będziemy musieli zmodyfikować te zapytania wybierające, aby uzyskać korzyści z naszej pracy. Będziemy również musieli zaktualizować wartości w nowo dodanych atrybutach dla istniejących rekordów. To też będzie wymagało nieco więcej kodowania.
Przykładowy model, zdenormalizowany
W poniższym modelu zastosowałem niektóre z wyżej wymienionych reguł denormalizacji. Różowe stoły zostały zmodyfikowane, a jasnoniebieski jest zupełnie nowy.
Jakie zmiany zostały zastosowane i dlaczego?

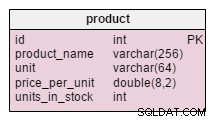
Jedyna zmiana w product tabela jest dodatkiem units_in_stock atrybut. W znormalizowanym modelu moglibyśmy obliczyć te dane jako jednostki zamówione – sprzedane – (oferowane) – jednostki umorzone . Wyliczenie powtarzaliśmy za każdym razem, gdy klient prosi o ten produkt, co byłoby niezwykle czasochłonne. Zamiast tego obliczymy wartość z góry; gdy klient nas poprosi, przygotujemy. Oczywiście znacznie upraszcza to zapytanie wybierające. Z drugiej strony units_in_stock atrybut musi być dostosowywany po każdym wstawieniu, aktualizacji lub usunięciu w products_on_order , writeoff , product_offered i product_sold tabele.
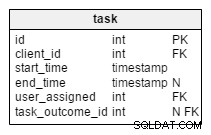
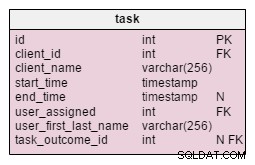
W zmodyfikowanym task tabeli, znajdujemy dwa nowe atrybuty:client_name i user_first_last_name . Oba przechowują wartości w momencie tworzenia zadania. Powodem jest to, że obie te wartości mogą się zmieniać w czasie. Będziemy również przechowywać klucz obcy, który łączy je z pierwotnym identyfikatorem klienta i użytkownika. Chcielibyśmy przechowywać więcej wartości, takich jak adres klienta, identyfikator VAT itp.




Zdenormalizowany product_offered tabela ma dwa nowe atrybuty, price_per_unit i price . price_per_unit atrybut jest przechowywany, ponieważ musimy przechowywać rzeczywistą cenę kiedy produkt był oferowany . Znormalizowany model pokazywałby tylko swój aktualny stan, więc gdy cena produktu zmieni się, zmienią się również nasze „historyczne” ceny. Nasza zmiana nie tylko sprawia, że baza danych działa szybciej, ale także działa lepiej. price atrybut to obliczona wartość units_sold * price_per_unit . Dodałem to tutaj, aby uniknąć dokonywania tych obliczeń za każdym razem, gdy chcemy spojrzeć na listę oferowanych produktów. To niewielki koszt, ale poprawia wydajność.
Zmiany wprowadzone w product_sold tabele są bardzo podobne. Struktura tabeli jest taka sama, ale przechowuje listę sprzedanych przedmiotów.
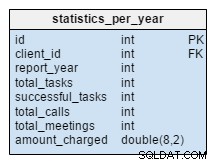
statistics_per_year stół jest zupełnie nowy w naszym modelu. Powinniśmy patrzeć na nią jak na zdenormalizowaną tabelę, ponieważ wszystkie jej dane można obliczyć z innych tabel. Ideą tej tabeli jest przechowywanie liczby zadań, udanych zadań, spotkań i rozmów telefonicznych związanych z danym klientem. Obsługuje również sumę naliczaną w każdym roku. Po wstawieniu, zaktualizowaniu lub usunięciu czegokolwiek w task , meeting , call i product_sold tabele, powinniśmy przeliczyć dane tej tabeli dla tego klienta i odpowiedniego roku. Możemy się spodziewać, że w większości będziemy mieli zmiany tylko na bieżący rok. Raporty za poprzednie lata nie powinny wymagać zmian.
Wartości w tej tabeli są obliczane z góry, więc poświęcimy mniej czasu i zasobów w momencie, gdy potrzebujemy wyniku obliczeń. Pomyśl o wartościach, których będziesz często potrzebować. Być może nie będziesz ich regularnie potrzebować i możesz zaryzykować obliczanie niektórych z nich na żywo.
Denormalizacja to bardzo interesująca i potężna koncepcja. Chociaż nie jest to pierwsze, o którym powinieneś pamiętać, aby poprawić wydajność, w niektórych sytuacjach może to być najlepsze lub nawet jedyne rozwiązanie.
Zanim zdecydujesz się na denormalizację, upewnij się, że tego chcesz. Przeprowadź analizę i śledź wyniki. Prawdopodobnie zdecydujesz się na denormalizację po tym, jak już będziesz na żywo. Nie bój się go używać, ale śledź zmiany i nie powinieneś doświadczać żadnych problemów (tj. przerażających anomalii danych).



