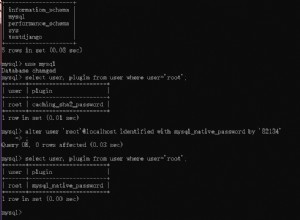
W przypadku PostgreSQL myślę, że chcesz lag funkcja okna
porównać wiersze; będzie to znacznie wydajniejsze niż samodzielne łączenie i filtrowanie. To nie zadziała z MySQL, ponieważ nadal nie obsługuje standardowych funkcji okna SQL:2003; patrz poniżej.
Aby znaleźć tylko dwa najniższe, możesz użyć dense_rank funkcja okna nad ticketid , a następnie przefiltruj wyniki, aby zwrócić tylko wiersze, w których dense_rank() = 2 , czyli wiersz z drugim od najniższego znacznika czasu, gdzie lag() wygeneruje wiersz z najniższym znacznikiem czasu.
Zobacz ten SQLFiddle który pokazuje przykładowe DDL i dane wyjściowe.
SELECT ticketid, extract(epoch from tdiff) FROM (
SELECT
ticketid,
ticketdate - lag(ticketdate) OVER (PARTITION BY ticketid ORDER BY ticketdate) AS tdiff,
dense_rank() OVER (PARTITION BY ticketid ORDER BY ticketdate) AS rank
FROM Table1
ORDER BY ticketid) x
WHERE rank = 2;
Użyłem ticketdate jako nazwę kolumny daty, ponieważ date to okropna nazwa kolumny (jest to nazwa typu danych) i nigdy nie powinna być używana; w wielu sytuacjach musi być cytowany podwójnie.
Podejście przenośne to prawdopodobnie samoprzyłączanie się, które opublikowali inni. Powyższe podejście do funkcji okna prawdopodobnie działa również w Oracle, ale wydaje się, że nie w MySQL. O ile wiem, nie obsługuje funkcji okna SQL:2003.
Definicja schematu będzie działać z MySQL, jeśli SET sql_mode = 'ANSI' i użyj timestamp zamiast timestamp with time zone . Wygląda na to, że funkcje okien nie działają; MySQL dławi się na OVER klauzula. Zobacz ten SQLFiddle
.