W październiku zeszłego roku rzuciliśmy wyzwanie naszym PyBites, aby stworzyli aplikację internetową, która lepiej nawiguje po kanale Daily Python Tip. W tym artykule podzielę się tym, co zbudowałem i czego nauczyłem się po drodze.
Z tego artykułu dowiesz się:
- Jak sklonować repozytorium projektu i skonfigurować aplikację.
- Jak korzystać z API Twittera za pośrednictwem modułu Tweepy do ładowania tweetów.
- Jak używać SQLAlchemy do przechowywania i zarządzania danymi (wskazówki i hashtagi).
- Jak zbudować prostą aplikację internetową za pomocą Bottle, mikrostruktury internetowej podobnej do Flask.
- Jak używać frameworka pytest do dodawania testów.
- Jak wskazówki Better Code Hub doprowadziły do bardziej łatwego w utrzymaniu kodu.
Jeśli chcesz kontynuować, szczegółowo przeczytać kod (i być może przyczynić się do tego), sugeruję rozwidlenie repozytorium. Zaczynajmy.
Konfiguracja projektu
Po pierwsze, Przestrzenie nazw to jeden świetny pomysł więc zróbmy naszą pracę w środowisku wirtualnym. Używając Anacondy, tworzę to tak:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Utwórz produkcyjną i testową bazę danych w Postgresie:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
Będziemy potrzebować poświadczeń, aby połączyć się z bazą danych i interfejsem Twitter API (najpierw utwórz nową aplikację). Zgodnie z najlepszymi praktykami konfiguracja powinna być przechowywana w środowisku, a nie w kodzie. Umieść następujące zmienne env na końcu ~/virtualenvs/pytip/bin/activate , skrypt, który obsługuje aktywację/dezaktywację środowiska wirtualnego, upewniając się, że aktualizujesz zmienne dla środowiska:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
W funkcji dezaktywacji tego samego skryptu wyłączam je, aby zachować rzeczy poza zasięgiem powłoki podczas dezaktywacji (opuszczania) środowiska wirtualnego:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Teraz jest dobry moment na aktywację środowiska wirtualnego:
$ source ~/virtualenvs/pytip/bin/activate
Sklonuj repozytorium i, przy włączonym środowisku wirtualnym, zainstaluj wymagania:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Następnie importujemy kolekcję tweetów za pomocą:
$ python tasks/import_tweets.py
Następnie sprawdź, czy tabele zostały utworzone, a tweety dodane:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Teraz przeprowadźmy testy:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
I na koniec uruchom aplikację Butelka za pomocą:
$ python app.py
Przejdź do https://localhost:8080 i voilà:powinieneś zobaczyć wskazówki posortowane według popularności. Klikając link hashtag po lewej stronie lub korzystając z pola wyszukiwania, możesz je łatwo filtrować. Tutaj widzimy pandy wskazówki na przykład:
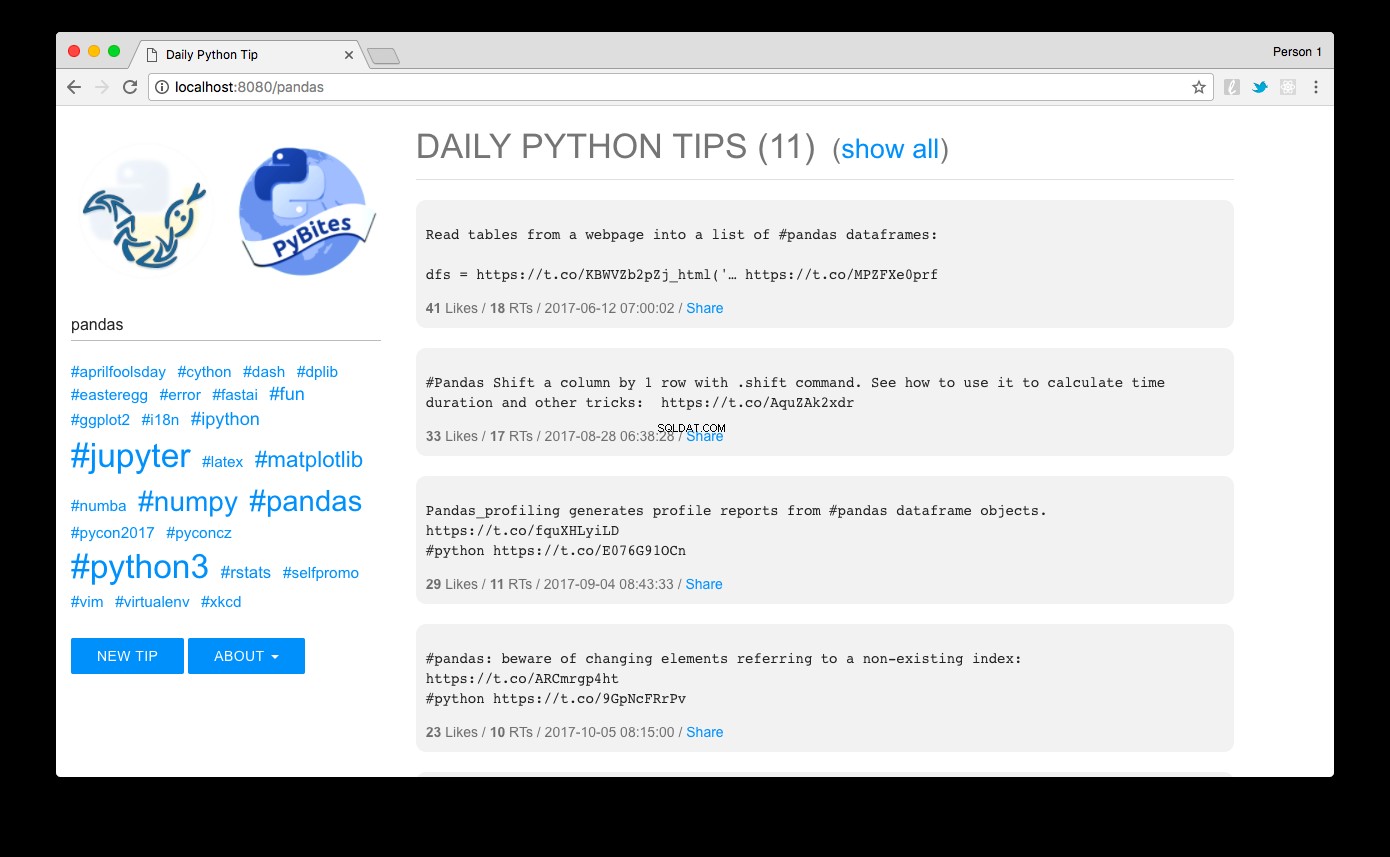
Projekt, który wykonałem za pomocą MUI – lekkiej struktury CSS zgodnej z wytycznymi Google Material Design.
Szczegóły implementacji
DB i SQLAlchemia
Użyłem SQLAlchemy do połączenia z bazą danych, aby uniknąć konieczności pisania dużej ilości (nadmiarowego) kodu SQL.
Na tips/models.py , definiujemy nasze modele - Hashtag i Tip - że SQLAlchemy zmapuje się do tabel DB:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
W tips/db.py , importujemy te modele i teraz łatwo jest pracować z bazą danych, na przykład łączyć się z Hashtag model:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
Oraz:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Zapytaj API Twittera
Musimy pobrać dane z Twittera. W tym celu utworzyłem tasks/import_tweets.py . Spakowałem to w zadaniach ponieważ powinien być uruchamiany w codziennym cronjob, aby szukać nowych wskazówek i aktualizować statystyki (liczba polubień i retweetów) na istniejących tweetach. Dla uproszczenia codziennie odtwarzam stoły. Jeśli zaczniemy polegać na relacjach FK z innymi tabelami, zdecydowanie powinniśmy wybrać instrukcje aktualizacji zamiast usuwania+dodawania.
Użyliśmy tego skryptu w konfiguracji projektu. Zobaczmy, co robi bardziej szczegółowo.
Najpierw tworzymy obiekt sesji API, który przekazujemy do tweepy.Cursor. Ta funkcja API jest naprawdę fajna:zajmuje się paginacją, iteracją na osi czasu. Jak na ilość napiwków – 222 w momencie, kiedy to piszę – to naprawdę szybko. exclude_replies=True i include_rts=False argumenty są wygodne, ponieważ chcemy tylko własnych tweetów Daily Python Tip (nie ponownego tweetów).
Wyodrębnianie hashtagów z podpowiedzi wymaga bardzo mało kodu.
Najpierw zdefiniowałem wyrażenie regularne dla tagu:
TAG = re.compile(r'#([a-z0-9]{3,})')
Następnie użyłem findall aby uzyskać wszystkie tagi.
Przekazałem je do collections.Counter, które zwraca obiekt podobny do dyktatu z tagami jako kluczami i liczy jako wartości, ułożone w kolejności malejącej według wartości (najczęściej). Wykluczyłem zbyt powszechny tag Pythona, który zniekształcałby wyniki.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Wreszcie, import_* funkcje w tasks/import_tweets.py wykonaj rzeczywisty import tweetów i hashtagów, wywołując add_* Metody bazy danych wskazówek katalog/pakiet.
Stwórz prostą aplikację internetową za pomocą Butelki
Po wykonaniu tej wstępnej pracy tworzenie aplikacji internetowej jest zaskakująco łatwe (lub nie takie zaskakujące, jeśli wcześniej korzystałeś z Flask).
Przede wszystkim poznaj Butelkę:
Bottle to szybka, prosta i lekka mikro platforma internetowa WSGI dla Pythona. Jest rozpowszechniany jako pojedynczy moduł plików i nie ma żadnych zależności innych niż standardowa biblioteka Pythona.
Ładny. Powstała aplikacja internetowa składa się z <30 LOC i można ją znaleźć w app.py.
W przypadku tej prostej aplikacji wystarczy jedna metoda z opcjonalnym argumentem tag. Podobnie jak w Flask, routing jest obsługiwany przez dekoratory. Jeśli zostanie wywołany z tagiem, filtruje wskazówki na tagu, w przeciwnym razie pokazuje je wszystkie. Dekorator widoku definiuje szablon do użycia. Podobnie jak Flask (i Django) zwracamy dict do użycia w szablonie.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
Zgodnie z dokumentacją, aby pracować z plikami statycznymi, należy dodać ten fragment kodu na górze, po imporcie:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Na koniec chcemy się upewnić, że działamy tylko w trybie debugowania na hoście lokalnym, stąd APP_LOCATION zmienna env zdefiniowana w ustawieniach projektu:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Szablony butelek
Bottle jest wyposażony w szybki, wydajny i łatwy do nauczenia wbudowany silnik szablonów o nazwie SimpleTemplate.
W podkatalogu views zdefiniowałem header.tpl , index.tpl i footer.tpl . W przypadku chmury tagów użyłem prostego wbudowanego CSS zwiększającego rozmiar tagu według liczby, zobacz header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
W index.tpl zapętlamy wskazówki:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Jeśli znasz Flask i Jinja2, powinno to wyglądać bardzo znajomo. Osadzanie Pythona jest jeszcze łatwiejsze, z mniejszą ilością pisania — (% ... vs {% ... %} ).
Wszystkie CSS, obrazy (i JS, gdybyśmy ich używali) trafiają do podfolderu statycznego.
I to wszystko, aby stworzyć podstawową aplikację internetową za pomocą Bottle. Po prawidłowym zdefiniowaniu warstwy danych jest to całkiem proste.
Dodaj testy za pomocą pytest
Teraz zróbmy trochę bardziej solidny projekt, dodając kilka testów. Testowanie bazy danych wymagało nieco więcej zagłębienia się w framework pytest, ale ostatecznie użyłem dekoratora pytest.fixture, aby skonfigurować i zniszczyć bazę danych za pomocą kilku tweetów testowych.
Zamiast wywoływać Twitter API, użyłem statycznych danych podanych w tweets.json .I zamiast używać żywej bazy danych, w tips/db.py , sprawdzam, czy pytest jest wywołującym (sys.argv[0] ). Jeśli tak, używam testowego DB. Prawdopodobnie zmienię to, ponieważ Bottle obsługuje pracę z plikami konfiguracyjnymi.
Część hashtaga była łatwiejsza do przetestowania (test_get_hashtag_counter ), ponieważ mógłbym po prostu dodać kilka hashtagów do ciągu wielowierszowego. Nie potrzeba żadnych urządzeń.
Jakość kodu ma znaczenie – Better Code Hub
Better Code Hub poprowadzi Cię w pisaniu, cóż, lepszego kodu. Przed napisaniem testów projekt uzyskał 7 punktów:
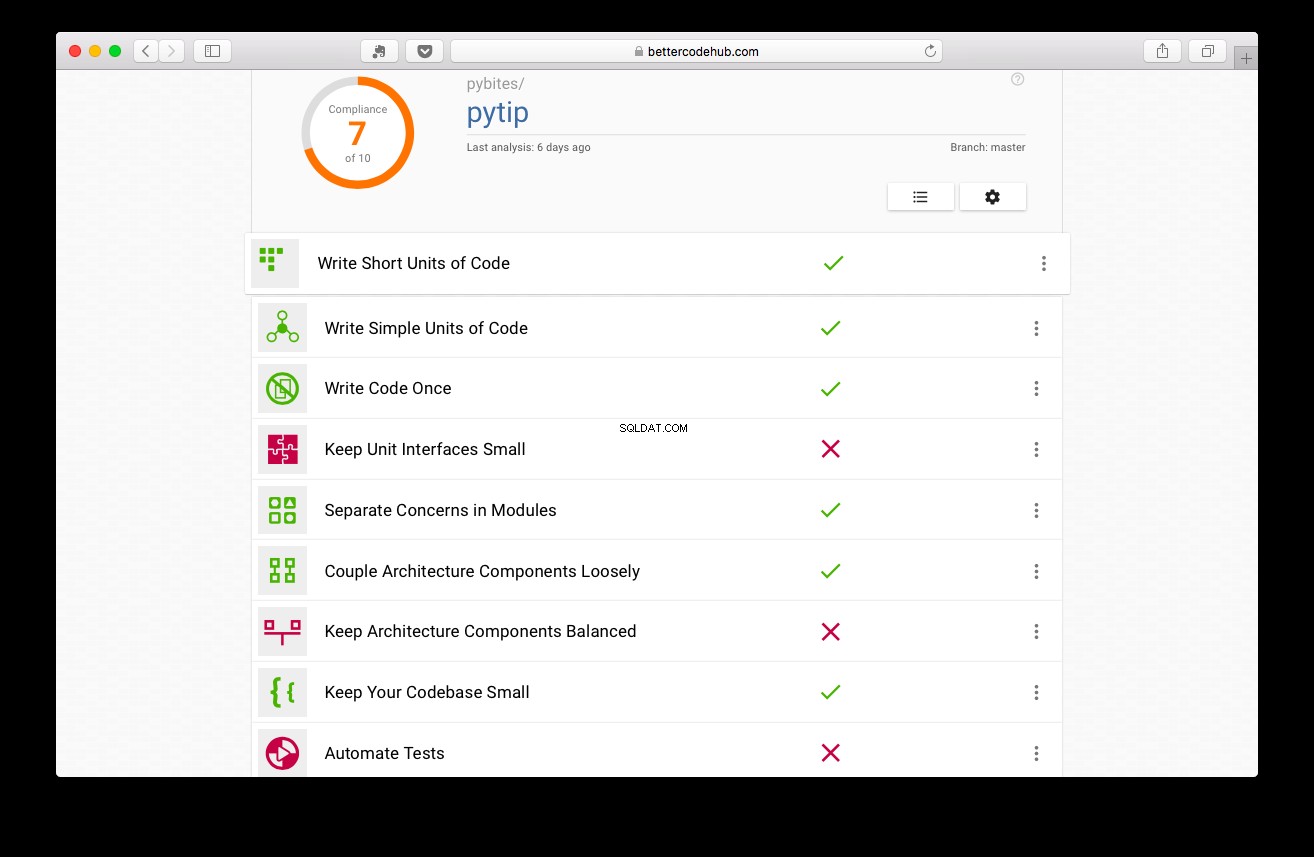
Nieźle, ale możemy zrobić lepiej:
-
Uderzyłem go do 9, czyniąc kod bardziej modułowym, usuwając logikę DB z app.py (aplikacja internetowa), umieszczając ją w folderze/pakietu tips (refaktoryzacje 1 i 2)
-
Następnie, po przeprowadzeniu testów, projekt uzyskał 10 punktów:
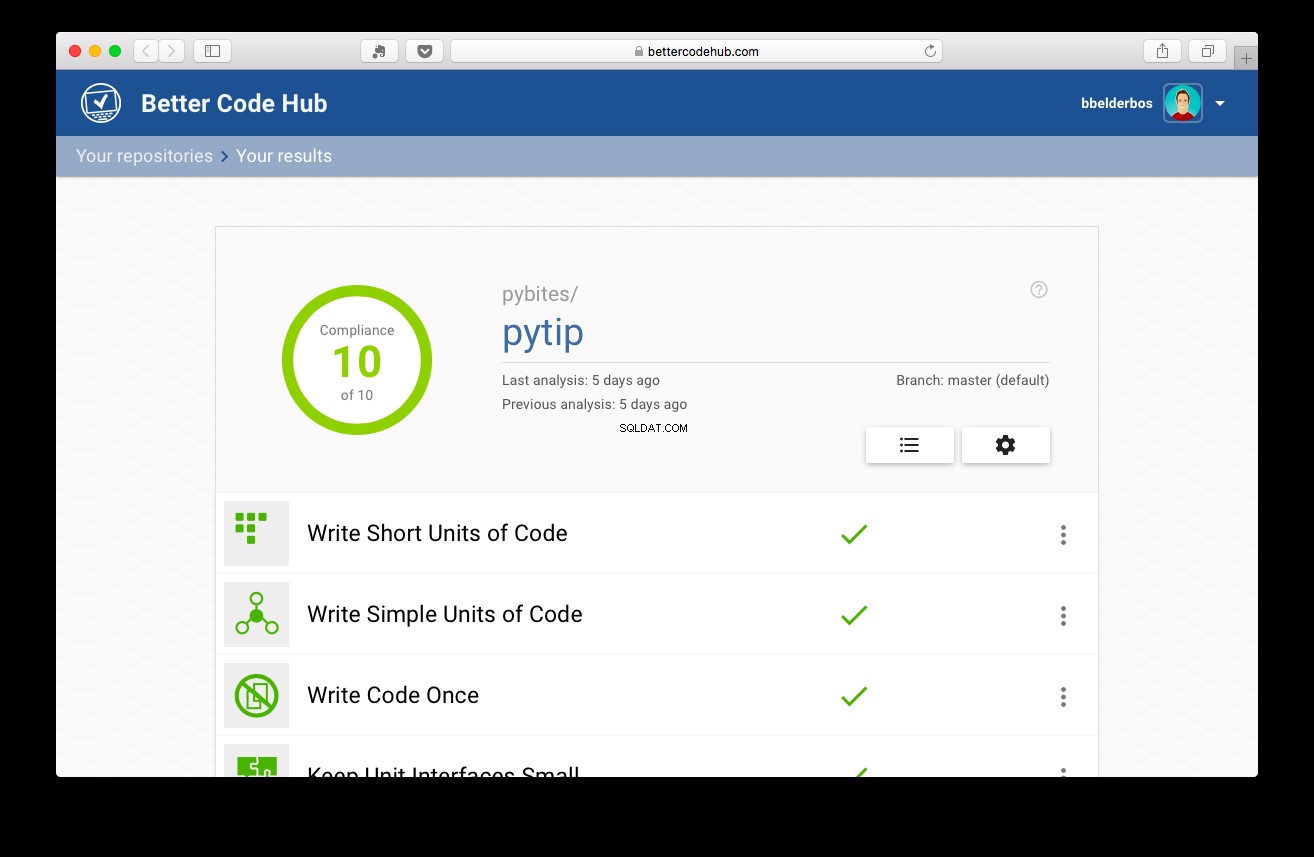
Wnioski i nauka
Nasze Code Challenge #40 zawierało kilka dobrych praktyk:
- Zbudowałem użyteczną aplikację, którą można rozszerzyć (chcę dodać API).
- Użyłem kilku fajnych modułów, które warto poznać:Tweepy, SQLAlchemy i Bottle.
- Nauczyłem się więcej pytest, ponieważ potrzebowałem urządzeń do testowania interakcji z DB.
- Przede wszystkim aplikacja stała się bardziej modułowa, dzięki czemu kod stał się testowalny, co ułatwiło jej utrzymanie. Better Code Hub było bardzo pomocne w tym procesie.
- Wdrożyłem aplikację w Heroku, korzystając z naszego przewodnika krok po kroku.
Wyzywamy Cię
Najlepszym sposobem na naukę i doskonalenie umiejętności kodowania jest praktyka. W PyBites ugruntowaliśmy tę koncepcję, organizując wyzwania dotyczące kodu Pythona. Sprawdź naszą rosnącą kolekcję, rozwidlej repozytorium i zacznij kodować!
Daj nam znać, jeśli tworzysz coś fajnego, wykonując pull request swojej pracy. Widzieliśmy, jak ludzie naprawdę przechodzą przez te wyzwania, podobnie jak my.
Miłego kodowania!