Wprowadzenie
Obecnie Twoje warunki dopasowania mogą być zbyt szerokie. Możesz jednak użyć odległości levenshtein, aby sprawdzić swoje słowa. Zrealizowanie za jego pomocą wszystkich zamierzonych celów, takich jak podobieństwo brzmienia, może nie być zbyt łatwe. Dlatego sugeruję podzielić problem na kilka innych.
Na przykład, możesz utworzyć własny moduł sprawdzania, który będzie używał przekazanych danych wejściowych, które można wywołać, które pobierają dwa ciągi, a następnie odpowiadają na pytanie, czy są takie same (dla levenshtein to będzie odległość mniejsza niż jakaś wartość, dla similar_text - jakiś procent podobieństwa itp. - do Ciebie należy określenie zasad).
Podobieństwo na podstawie słów
Cóż, wszystkie wbudowane funkcje zawiodą, jeśli mówimy o przypadku, gdy szukasz dopasowania częściowego - zwłaszcza jeśli chodzi o dopasowanie nieuporządkowane. Dlatego musisz stworzyć bardziej złożone narzędzie do porównywania. Masz:
- Ciąg danych (który będzie na przykład w bazie danych). Wygląda na to, że D =D0 D1 D2 ... Dn
- Ciąg wyszukiwania (który będzie wprowadzany przez użytkownika). Wygląda na to, że S =S0 S1 ... Sm
Tutaj symbole spacji oznaczają dowolną spację (zakładam, że symbole spacji nie wpłyną na podobieństwo). Również n > m . Z tą definicją twój problem dotyczy - znaleźć zestaw m słowa w D który będzie podobny do S . Według set Mam na myśli dowolną nieuporządkowaną sekwencję. Dlatego jeśli znajdziemy dowolną taką sekwencję w D , a następnie S jest podobny do D .
Oczywiście, jeśli n < m wtedy input zawiera więcej słów niż ciąg danych. W tym przypadku możesz pomyśleć, że nie są one podobne lub działać jak powyżej, ale zamień dane i dane wejściowe (co jednak wygląda trochę dziwnie, ale w pewnym sensie ma zastosowanie)
Wdrożenie
Aby to zrobić, musisz być w stanie stworzyć zestaw łańcuchów, które są częściami z m słowa z D . Na podstawie mojego tego pytania
możesz to zrobić za pomocą:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-więc dla dowolnej tablicy, getAssoc() zwróci tablicę nieuporządkowanych wyborów składających się z m każdy przedmiot.
Następnym krokiem jest uporządkowanie produkowanej selekcji. Powinniśmy przeszukać oba Niels Andersen i Andersen Niels w naszym D strunowy. Dlatego musisz umieć tworzyć permutacje dla tablicy. To bardzo częsty problem, ale tutaj też umieszczę swoją wersję:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Po tym będziesz mógł tworzyć selekcje m słowa, a następnie, permutując każdy z nich, pobierz wszystkie warianty do porównania z ciągiem wyszukiwania S . To porównanie za każdym razem będzie wykonywane za pomocą wywołania zwrotnego, takiego jak levenshtein . Oto przykład:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Spowoduje to sprawdzenie podobieństwa na podstawie wywołania zwrotnego użytkownika, które musi zaakceptować co najmniej dwa parametry (tj. porównywane ciągi). Możesz również chcieć zwrócić ciąg znaków, który wywołał pozytywny zwrot wywołania zwrotnego. Zwróć uwagę, że ten kod nie będzie się różnił wielkimi i małymi literami - ale może nie chcesz takiego zachowania (wtedy po prostu zamień strtolower() ).
Przykładowy pełny kod jest dostępny w tym wykazie (Nie korzystałem z piaskownicy, ponieważ nie jestem pewien, jak długo będzie tam dostępna lista kodów). Z tą próbką użycia:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
otrzymasz wynik taki jak:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-tutaj jest demonstracją tego kodu, na wszelki wypadek.
Złożoność
Ponieważ zależy Ci nie tylko na jakichkolwiek metodach, ale także na tym, jak dobry jest, możesz zauważyć, że taki kod będzie generował dość przesadne operacje. Mam na myśli przynajmniej generowanie części smyczkowych. Złożoność tutaj składa się z dwóch części:
- Część generowania strun. Jeśli chcesz wygenerować wszystkie części ciągu - musisz to zrobić tak, jak opisałem powyżej. Możliwy punkt do poprawy - generowanie nieuporządkowanych zestawów ciągów (przed permutacją). Ale nadal wątpię, czy da się to zrobić, ponieważ metoda w dostarczonym kodzie wygeneruje je nie „brute-force”, ale tak, jak są wyliczone matematycznie (z licznością
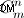 )
) - Część dotycząca sprawdzania podobieństwa. Tutaj twoja złożoność zależy od danego kontrolera podobieństwa. Na przykład
similar_text()ma złożoność O(N), dlatego przy dużych zestawach porównawczych będzie bardzo powolny.
Ale nadal możesz ulepszyć obecne rozwiązanie, sprawdzając w locie. Teraz ten kod najpierw wygeneruje wszystkie podsekwencje ciągów, a następnie zacznie je sprawdzać jeden po drugim. W powszechnym przypadku nie musisz tego robić, więc możesz chcieć zastąpić to zachowaniem, gdy po wygenerowaniu następnej sekwencji zostanie ona natychmiast sprawdzona. Wtedy zwiększysz wydajność dla ciągów, które mają pozytywną odpowiedź (ale nie dla tych, które nie mają dopasowania).