Każde wydanie PostgreSQL zawiera kilka głównych ulepszeń funkcji, ale równie interesujące jest to, że każde wydanie ulepsza również swoje wcześniejsze funkcje.
Ponieważ PostgreSQL 13 ma zostać wkrótce wydany, nadszedł czas, aby sprawdzić, jakie funkcje i ulepszenia wnosi do nas społeczność. Jednym z takich ulepszeń bez hałasu jest „Udoskonalenie replikacji logicznej w zakresie partycjonowania”.
Zrozummy tę poprawę funkcji na przykładzie działającym.
Terminologia
Dwa terminy, które są ważne dla zrozumienia tej funkcji to:
- Tabele partycji
- Replikacja logiczna
Tabele partycji
Sposób na podzielenie dużego stołu na wiele fizycznych elementów w celu osiągnięcia korzyści, takich jak:
- Ulepszona wydajność zapytań
- Szybsze aktualizacje
- Szybsze zbiorcze ładowanie i usuwanie
- Organizowanie rzadko używanych danych na wolnych dyskach
Niektóre z tych zalet są osiągane przez przycinanie partycji (tj. planowanie zapytań używające definicji partycji do decydowania, czy skanować partycję, czy nie) oraz fakt, że partycję jest raczej łatwiej zmieścić w ograniczonej pamięci w porównaniu do ogromnego stołu.
Tabela jest podzielona na partycje na podstawie:
- Lista
- Hash
- Zakres

Replikacja logiczna
Jak sama nazwa wskazuje, jest to metoda replikacji, w której dane są replikowane przyrostowo na podstawie ich tożsamości (np. klucza). Nie jest podobny do WAL lub fizycznych metod replikacji, w których dane są przesyłane bajt po bajcie.
W oparciu o wzorzec wydawca-subskrybent, źródło danych musi określać wydawcę, podczas gdy cel musi być zarejestrowany jako subskrybent. Interesujące przypadki użycia to:
- Replikacja selektywna (tylko część bazy danych)
- Jednoczesny zapis do dwóch instancji bazy danych, w których dane są replikowane
- Replikacja między różnymi systemami operacyjnymi (np. Linux i Windows)
- Dokładne zabezpieczenia replikacji danych
- Wyzwala wykonanie, gdy dane docierają po stronie odbiorcy
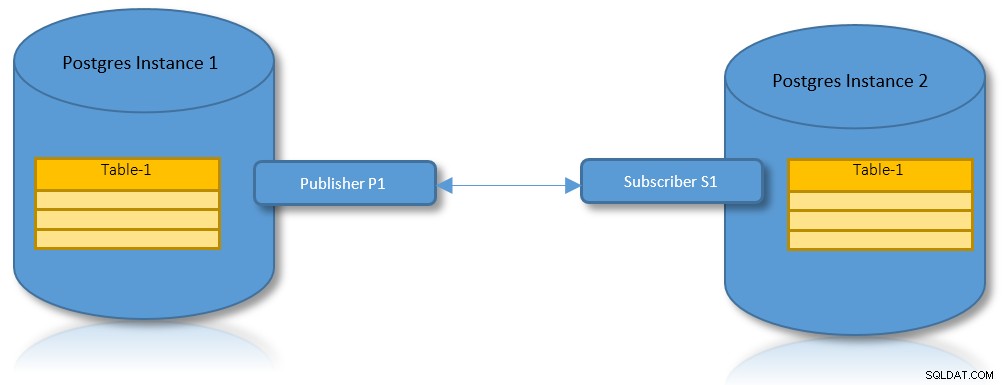
Replikacja logiczna dla partycji
Dzięki korzyściom zarówno replikacji logicznej, jak i partycjonowania, praktycznym przypadkiem użycia jest scenariusz, w którym podzielona na partycje tabela musi zostać zreplikowana w dwóch instancjach PostgreSQL.
Poniżej przedstawiono kroki w celu ustalenia i podkreślenia ulepszeń dokonywanych w PostgreSQL 13 w tym kontekście.
Konfiguracja
Rozważ konfigurację dwóch węzłów do uruchamiania dwóch różnych instancji zawierających tabelę podzieloną na partycje:
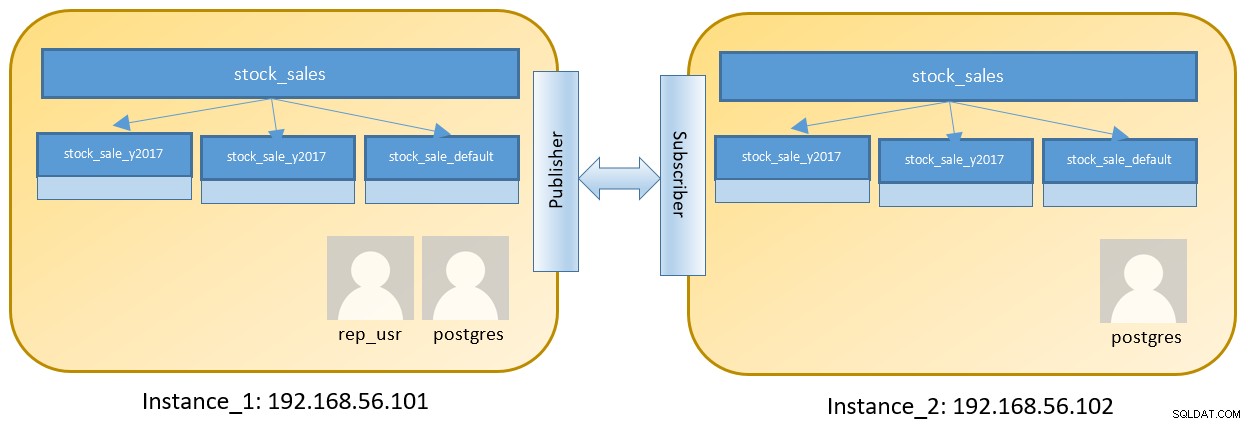
Kroki na Instance_1 są następujące:logowanie do posta 192.168.56.101 jako użytkownik postgres :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startUstawienie „wal_level” jest ustawione specjalnie na „logiczny”, aby wskazać, że replikacja logiczna będzie używana do replikacji danych z tej instancji. Plik konfiguracyjny „pg_hba.conf” został również zmodyfikowany, aby umożliwić połączenia z 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Chociaż rola postgres jest domyślnie tworzona w bazie danych Instance_1, należy również utworzyć osobnego użytkownika z ograniczonym dostępem – co ogranicza zakres tylko dla danej tabeli.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Prawie podobna konfiguracja jest wymagana w Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startNależy zauważyć, że ponieważ Instance_2 nie będzie źródłem danych dla żadnego innego węzła, ustawienia wal_level oraz plik pg_hba.conf nie wymagają żadnych dodatkowych ustawień. Nie trzeba dodawać, że pg_hba.conf może wymagać aktualizacji zgodnie z potrzebami produkcyjnymi.
Replikacja logiczna nie obsługuje DDL, musimy również utworzyć strukturę tabeli na Instance_2. Utwórz tabelę podzieloną na partycje, korzystając z powyższego tworzenia partycji, aby utworzyć taką samą strukturę tabeli również na Instance_2.
Konfiguracja replikacji logicznej
Konfiguracja replikacji logicznej staje się znacznie łatwiejsza dzięki PostgreSQL 13. Do czasu PostgreSQL 12 struktura była taka jak poniżej:
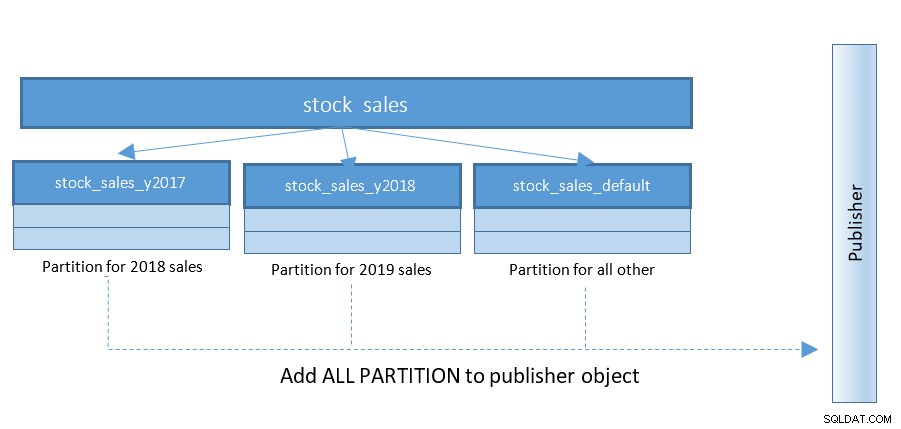
Dzięki PostgreSQL 13 publikowanie partycji staje się znacznie łatwiejsze. Zapoznaj się z poniższym diagramem i porównaj z poprzednim diagramem:
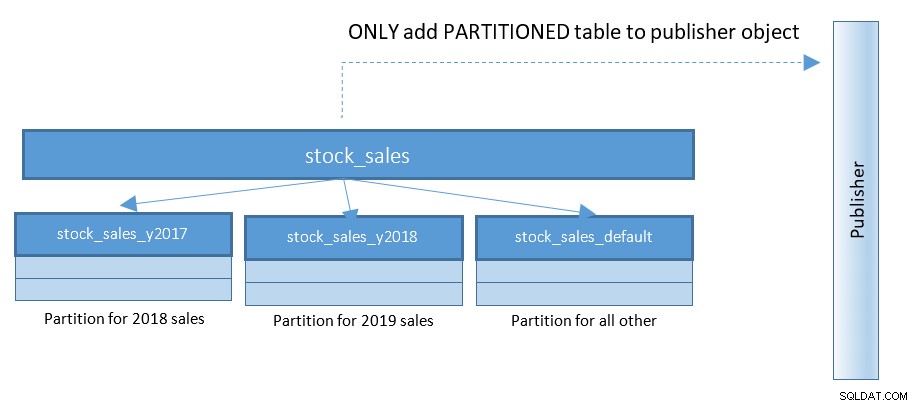
Z konfiguracjami szalejącymi z setkami i tysiącami podzielonych na partycje tabel – ta mała zmiana upraszcza rzeczy w dużym stopniu.
W PostgreSQL 13 instrukcje tworzenia takiej publikacji będą następujące:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Parametr konfiguracji publish_via_partition_root jest nowością w PostgreSQL 13, która pozwala węzłowi odbiorcy mieć nieco inną hierarchię liści. Samo tworzenie publikacji na partycjonowanych tabelach w PostgreSQL 12 zwróci komunikaty o błędach, jak poniżej:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Ignorując ograniczenia PostgreSQL 12 i kontynuując pracę nad tą funkcją w PostgreSQL 13, musimy ustanowić subskrybenta na Instance_2 za pomocą następujących oświadczeń:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Sprawdzanie, czy to naprawdę działa
Właściwie skończyliśmy z całą konfiguracją, ale przeprowadźmy kilka testów, aby sprawdzić, czy wszystko działa.
W instancji_1 wstaw wiele wierszy, upewniając się, że odradzają się w wielu partycjach:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Sprawdź dane w Instance_2:
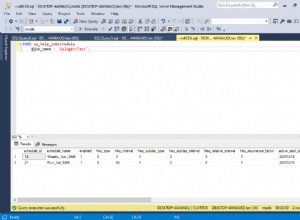
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Teraz sprawdźmy, czy replikacja logiczna działa, nawet jeśli węzły liści nie są takie same po stronie odbiorcy.
Dodaj kolejną partycję na Instance_1 i wstaw rekord:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Sprawdź dane w Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Inne funkcje partycjonowania w PostgreSQL 13
Istnieją również inne ulepszenia w PostgreSQL 13, które są związane z partycjonowaniem, a mianowicie:
- Ulepszenia łączenia między podzielonymi na partycje tabelami
- Tabele podzielone na partycje obsługują teraz PRZED wyzwalaczami na poziomie wiersza
Wnioski
Na pewno sprawdzę wyżej wymienione dwie nadchodzące funkcje w moim kolejnym zestawie blogów. Do tego czasu do myślenia – czy dzięki połączonej sile partycjonowania i logicznej replikacji PostgreSQL zbliża się do konfiguracji master-master?