Większość obciążeń OLTP obejmuje losowe użycie operacji we/wy dysku. Wiedząc, że dyski (w tym SSD) działają wolniej niż w przypadku pamięci RAM, systemy baz danych wykorzystują buforowanie w celu zwiększenia wydajności. Buforowanie polega na przechowywaniu danych w pamięci (RAM) w celu uzyskania szybszego dostępu w późniejszym czasie.
PostgreSQL wykorzystuje również buforowanie swoich danych w przestrzeni zwanej shared_buffers. W tym blogu zbadamy tę funkcję, aby pomóc Ci zwiększyć wydajność.
Podstawy buforowania PostgreSQL
Zanim zagłębimy się w koncepcję buforowania, przyjrzyjmy się podstawom.
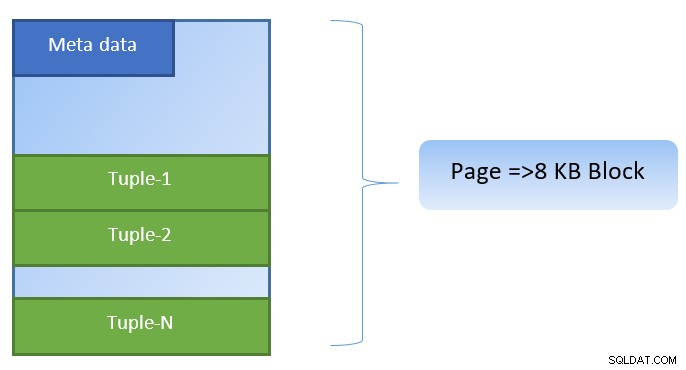
W PostgreSQL dane są zorganizowane w postaci stron o rozmiarze 8KB, a każda taka strona może zawierać wiele krotek (w zależności od rozmiaru krotki). Uproszczona reprezentacja może wyglądać jak poniżej:
PostgreSQL buforuje następujące elementy w celu przyspieszenia dostępu do danych:
- Dane w tabelach
- Indeksy
- Plany wykonania zapytań
Podczas gdy buforowanie planu wykonania zapytania koncentruje się na oszczędzaniu cykli procesora; buforowanie danych tabeli i danych indeksu koncentruje się na oszczędzaniu kosztownych operacji we/wy dysku.
PostgreSQL pozwala użytkownikom określić, ile pamięci chcieliby zarezerwować na przechowywanie takiej pamięci podręcznej dla danych. Odpowiednie ustawienie to shared_buffers w pliku konfiguracyjnym postgresql.conf. Skończona wartość shared_buffers określa, ile stron można buforować w dowolnym momencie.
Podczas wykonywania zapytania PostgreSQL wyszukuje na dysku stronę zawierającą odpowiednią krotkę i umieszcza ją w pamięci podręcznej shared_buffers w celu uzyskania dostępu bocznego. Następnym razem, gdy trzeba będzie uzyskać dostęp do tej samej krotki (lub dowolnej krotki na tej samej stronie), PostgreSQL może zapisać IO dysku, odczytując ją w pamięci.
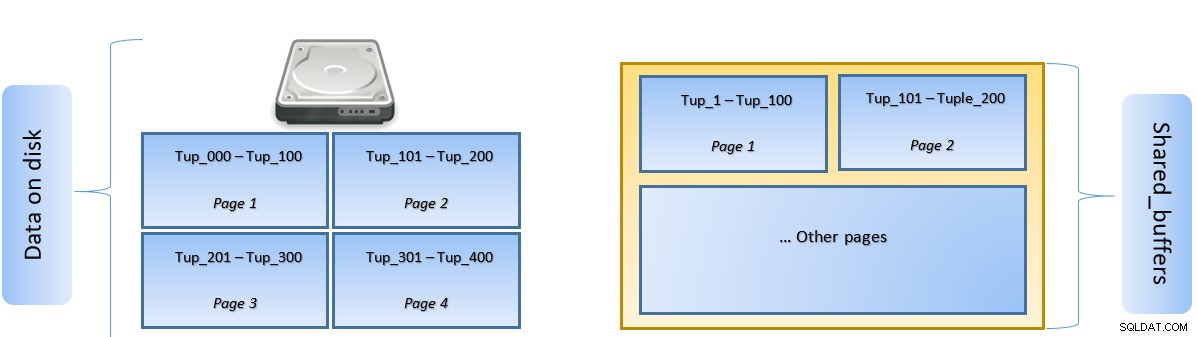
Na powyższym rysunku Strona 1 i Strona 2 określonego tabela została zbuforowana. W przypadku, gdy zapytanie użytkownika wymaga dostępu do krotek między Tuple-1 a Tuple-200, PostgreSQL może pobrać je z samej pamięci RAM.
Jeśli jednak zapytanie musi uzyskać dostęp do krotek od 250 do 350, będzie musiało wykonać dyskowe operacje we/wy dla strony 3 i strony 4. Wszelki dalszy dostęp dla krotek od 201 do 400 będzie pobierany z pamięci podręcznej i dyskowe we/wy nie będą potrzebne – dzięki temu zapytanie będzie szybsze.
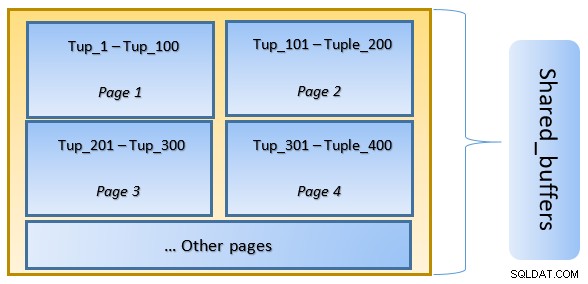
Na wysokim poziomie PostgreSQL podąża za algorytmem LRU (ostatnio używanym), aby zidentyfikować strony, które należy usunąć z pamięci podręcznej. Innymi słowy, strona, do której uzyskuje się dostęp tylko raz, ma większe szanse na eksmisję (w porównaniu do strony, do której uzyskuje się dostęp wielokrotnie), na wypadek gdyby nowa strona musiała zostać pobrana przez PostgreSQL do pamięci podręcznej.
Buforowanie PostgreSQL w akcji
Wykonajmy przykład i zobaczmy wpływ pamięci podręcznej na wydajność.
Uruchom PostgreSQL z ustawieniem shared_buffer na domyślną wartość 128 MB
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startPołącz się z serwerem i utwórz fikcyjną tabelę tblDummy i indeks na c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Wypełnij fałszywe dane 200000 krotek, tak aby było 10000 unikalnych p_id, a na każdy p_id przypadało 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Uruchom ponownie serwer, aby wyczyścić pamięć podręczną. Teraz wykonaj zapytanie i sprawdź czas potrzebny na wykonanie tego samego
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msNastępnie sprawdź bloki odczytane z dysku
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0W powyższym przykładzie odczytano 1000 bloków z dysku, aby znaleźć liczby krotek, gdzie c_id =1. Pobranie tych rekordów z dysku zajęło 160 ms, ponieważ było zaangażowanych we/wy dysku.
Wykonanie jest szybsze, jeśli to samo zapytanie zostanie ponownie wykonane, ponieważ na tym etapie wszystkie bloki są nadal w pamięci podręcznej serwera PostgreSQL
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msi bloki odczytane z dysku vs z pamięci podręcznej
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Widać z góry, że ponieważ wszystkie bloki zostały odczytane z pamięci podręcznej i nie było wymagane żadne operacje I/O na dysku. Dzięki temu wyniki były szybsze.
Ustawianie rozmiaru pamięci podręcznej PostgreSQL
Rozmiar pamięci podręcznej należy dostosować w środowisku produkcyjnym zgodnie z ilością dostępnej pamięci RAM oraz zapytaniami wymaganymi do wykonania.
Jako przykład – shared_buffer o wielkości 128 MB może nie wystarczyć do buforowania wszystkich danych, jeśli zapytanie miałoby pobrać więcej krotek:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Zmień shared_buffer na 1024MB, aby zwiększyć heap_blks_hit.
W rzeczywistości, biorąc pod uwagę zapytania (na podstawie c_id), w przypadku reorganizacji danych, lepszy współczynnik trafień w pamięci podręcznej można osiągnąć również przy mniejszym shared_buffer.
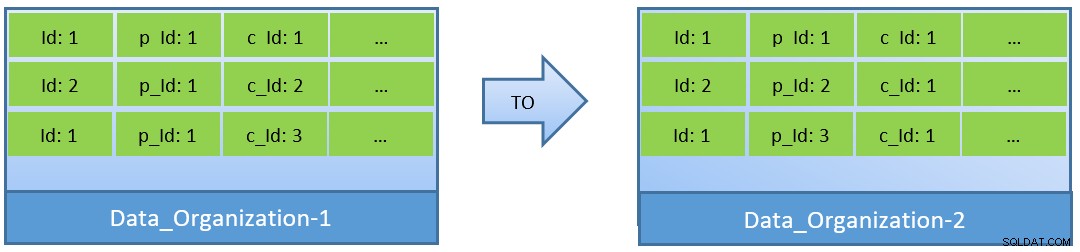
W Data_Organization-1 PostgreSQL będzie potrzebował 1000 odczytów bloków (i zużycia pamięci podręcznej ) do znalezienia c_id=1. Z drugiej strony, dla Data_Organisation-2, dla tego samego zapytania, PostgreSQL będzie potrzebował tylko 104 bloków.
Mniej bloków wymaganych dla tego samego zapytania ostatecznie zużywa mniej pamięci podręcznej, a także optymalizuje czas wykonania zapytania.
Wnioski
Podczas gdy shared_buffer jest utrzymywany na poziomie procesu PostgreSQL, pamięć podręczna na poziomie jądra jest również brana pod uwagę w celu identyfikacji zoptymalizowanych planów wykonywania zapytań. Zajmę się tym tematem w późniejszej serii blogów.



