Chciałem wskoczyć z opcją rozwiązania swojego zadania za pomocą czystego BigQuery (Standard SQL)
Warunki wstępne/założenia :dane źródłowe znajdują się w sandbox.temp.id1_id2_pairs
Powinieneś to zastąpić własnym lub jeśli chcesz przetestować z fikcyjnymi danymi ze swojego pytania - możesz utworzyć tę tabelę jak poniżej (oczywiście zastąp sandbox.temp z własnym project.dataset )
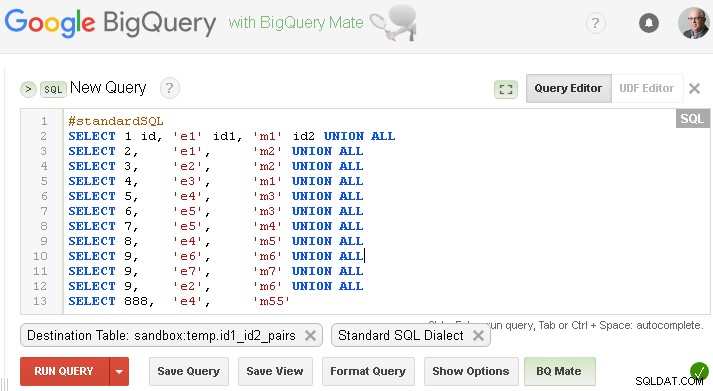
Upewnij się, że ustawiłeś odpowiednią tabelę docelową
Uwaga :możesz znaleźć wszystkie odpowiednie zapytania (jako tekst) na dole tej odpowiedzi, ale na razie ilustruję moją odpowiedź zrzutami ekranu - więc wszystko jest przedstawione - zapytanie, wynik i użyte opcje
Tak więc będą trzy kroki:
Krok 1 — Inicjalizacja
Tutaj po prostu robimy wstępne grupowanie id1 na podstawie połączeń z id2:
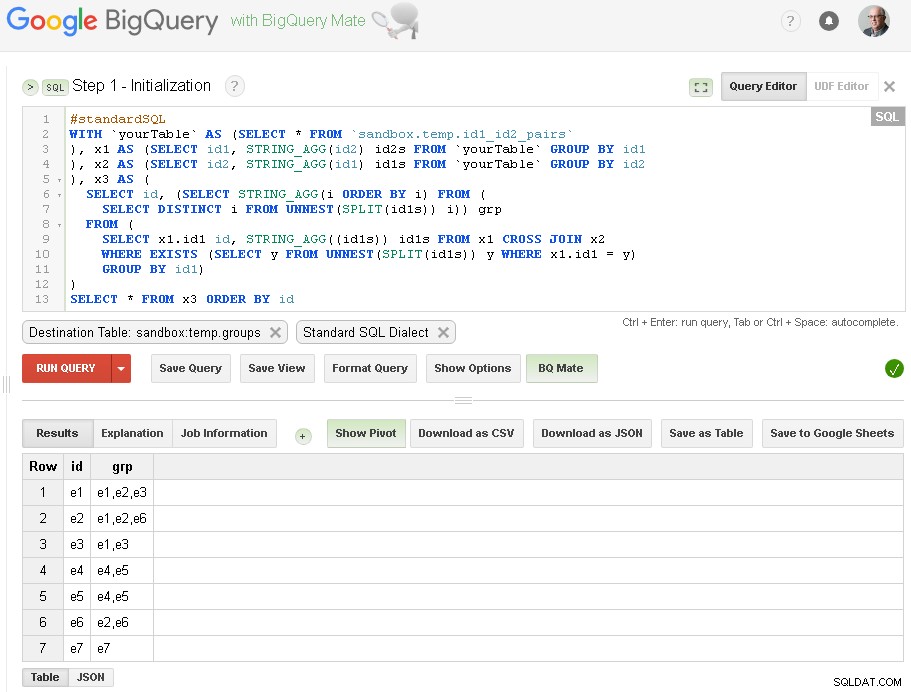
Jak widać tutaj - stworzyliśmy listę wszystkich wartości id1 z odpowiednimi połączeniami w oparciu o proste jednopoziomowe połączenie przez id2
Tabela wyjściowa to sandbox.temp.groups
Krok 2 — Grupowanie iteracji
W każdej iteracji będziemy wzbogacać grupowanie na podstawie już ustalonych grup.
Źródłem zapytania jest wyjściowa tabela z poprzedniego kroku (sandbox.temp.groups ) i Destination to ta sama tabela (sandbox.temp.groups ) z nadpisaniem
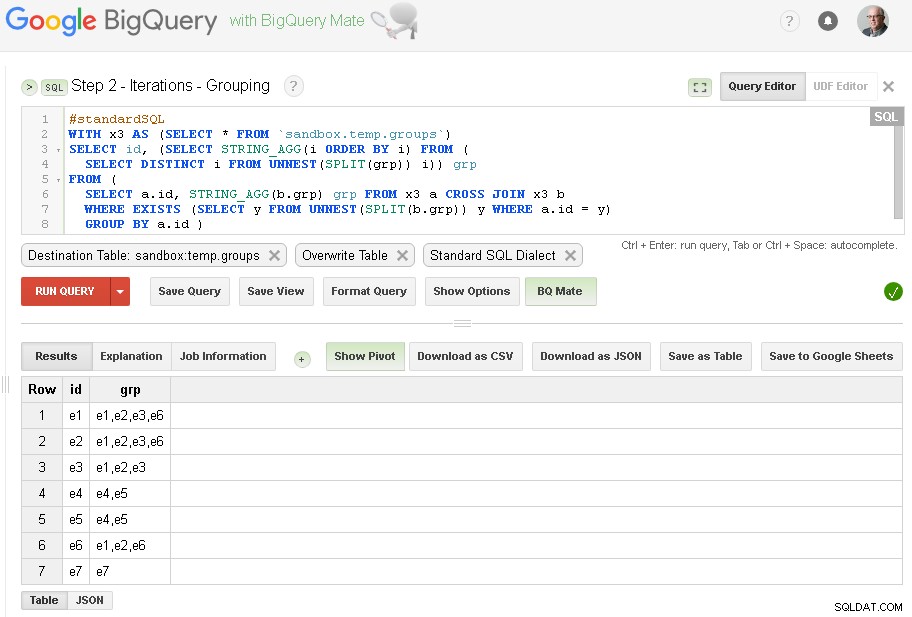
Będziemy kontynuować iteracje, aż liczba znalezionych grup będzie taka sama jak w poprzedniej iteracji
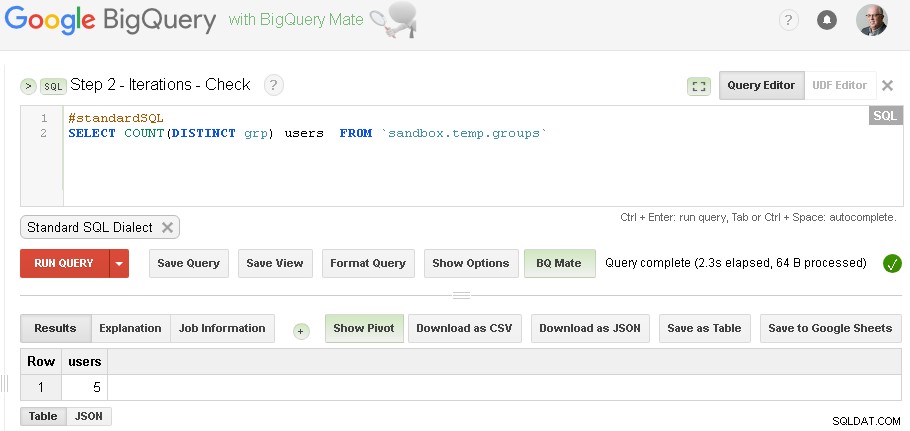
Uwaga :możesz po prostu otworzyć dwie karty internetowego interfejsu użytkownika BigQuery (jak pokazano powyżej) i bez zmiany kodu, po prostu uruchom Grupowanie, a następnie sprawdzaj raz za razem, aż iteracja zbiegnie się
(dla konkretnych danych, których użyłem w sekcji wymagań wstępnych - miałem trzy iteracje - pierwsza iteracja dała 5 użytkowników, druga iteracja dała 3 użytkowników, a trzecia iteracja dała ponownie 3 użytkowników - co wskazuje, że zrobiliśmy z iteracjami.
Oczywiście w prawdziwym przypadku - liczba iteracji może być większa niż tylko trzy - więc potrzebujemy pewnego rodzaju automatyzacji (patrz odpowiedni rozdział na dole odpowiedzi).
Krok 3 – Ostateczne grupowanie
Po zakończeniu grupowania id1 - możemy dodać końcowe grupowanie dla id2
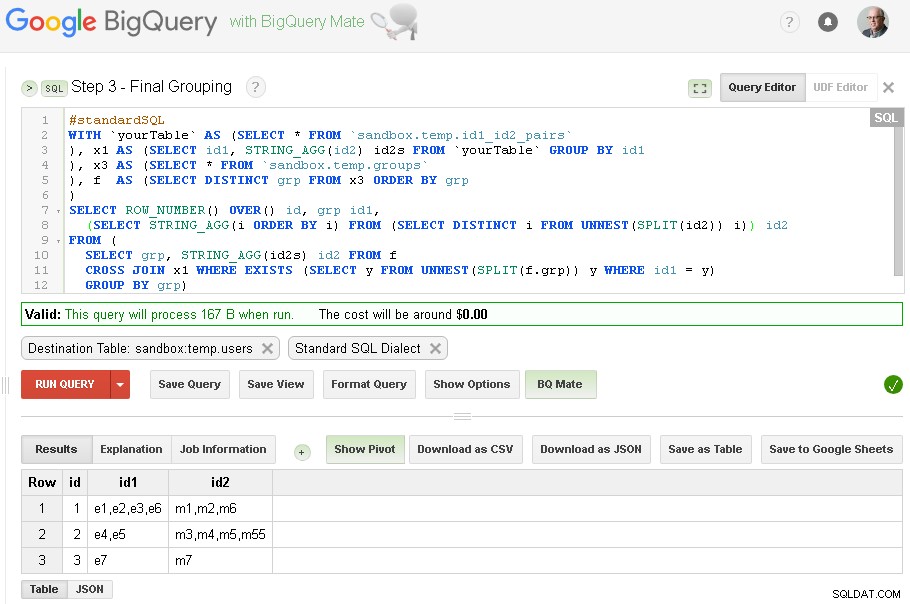
Ostateczny wynik jest teraz w sandbox.temp.users tabela
Użyte zapytania (nie zapomnij ustawić odpowiednich tabel docelowych i nadpisać w razie potrzeby zgodnie z opisaną powyżej logiką i zrzutami ekranu):
Wymagania wstępne:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Krok 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Krok 2 - Grupowanie
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Krok 2 - Sprawdź
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Krok 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automatyzacja :
Oczywiście, powyższy "proces" można wykonać ręcznie w przypadku, gdy iteracje szybko się zbiegają - w rezultacie otrzymasz 10-20 przebiegów. Ale w bardziej rzeczywistych przypadkach możesz to łatwo zautomatyzować z dowolnym klientem
do wyboru