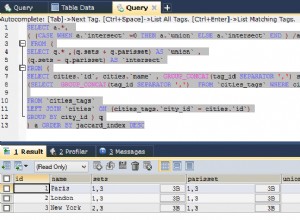
Pełnotekstowe wyszukiwanie w języku naturalnym w MySQL ma na celu dopasowanie zapytań do korpusu w celu znalezienia najbardziej odpowiednich dopasowań. Załóżmy więc, że mamy artykuł, który zawiera „Kocham ciasto” i mamy dokumenty d1, d2, d3 (baza danych w twoim przypadku). Dokument 1 i 2 dotyczą odpowiednio sportu i religii, a dokument 3 dotyczy jedzenia. Twoje zapytanie,
Zwróci d3, a następnie d2, d1 (losowa kolejność d2,d1 w zależności od tego, który jest bardziej równy przedimkowiu), ponieważ d3 najlepiej pasuje do przedimka.
Podstawowym algorytmem używanym przez MYSQL jest prawdopodobnie algorytm tf-idf, gdzie tf oznacza częstotliwość terminów, a idf odwrotną częstotliwość dokumentów. tf jest tak, jak to się mówi, tyle razy, ile razy słowo w w artykule występuje w dokumencie A. idf opiera się na tym, w ilu dokumentach występuje słowo. Tak więc słowa występujące w wielu dokumentach nie wpływają na wybór najbardziej reprezentatywnego dokumentu. Iloczyn tf*idf daje wynik, im wyższy, tym lepiej słowo reprezentuje dokument. Tak więc „ciastko” pojawi się tylko w dokumencie d3, a zatem będzie miało wysoki tf i wysoki idf (ponieważ jest to odwrotność). Podczas gdy „the” będzie miał wysoki tf, ale niski idf, co spowoduje zakończenie tf i da niski wynik.
Tryb języka naturalnego MYSQL zawiera również zestaw odrzuconych słów (the, a, some itp.) i usuwa słowa, które mają mniej niż 4 litery. Co można zobaczyć w podanym linku.