Ten artykuł jest ósmą częścią serii dotyczącej wyrażeń tabelowych. Do tej pory przedstawiłem tło wyrażeń tabelarycznych, obejmujące zarówno aspekty logiczne, jak i optymalizacyjne tabel pochodnych, aspekty logiczne CTE oraz niektóre aspekty optymalizacji CTE. W tym miesiącu kontynuuję omówienie aspektów optymalizacji CTE, w szczególności dotyczących obsługi wielu odwołań CTE.
Ten artykuł jest ósmą częścią serii dotyczącej wyrażeń tabelowych. Do tej pory przedstawiłem tło wyrażeń tabelarycznych, obejmujące zarówno aspekty logiczne, jak i optymalizacyjne tabel pochodnych, aspekty logiczne CTE oraz niektóre aspekty optymalizacji CTE. W tym miesiącu kontynuuję omówienie aspektów optymalizacji CTE, w szczególności dotyczących obsługi wielu odwołań CTE.
W moich przykładach będę kontynuował korzystanie z przykładowej bazy danych TSQLV5. Skrypt tworzący i wypełniający TSQLV5 można znaleźć tutaj, a jego diagram ER znajduje się tutaj.
Wiele odniesień i niedeterminizm
W zeszłym miesiącu wyjaśniłem i pokazałem, że CTE nie są zagnieżdżone, podczas gdy tymczasowe tabele i zmienne tabel faktycznie zachowują dane. Przedstawiłem zalecenia dotyczące tego, kiedy sensowne jest użycie CTE, a kiedy ma sens użycie tymczasowych obiektów z punktu widzenia wydajności zapytań. Poza wydajnością rozwiązania należy jednak wziąć pod uwagę inny ważny aspekt optymalizacji CTE lub przetwarzania fizycznego — sposób obsługi wielu odwołań do CTE z zapytania zewnętrznego. Ważne jest, aby zdać sobie sprawę, że jeśli masz zapytanie zewnętrzne z wieloma odwołaniami do tego samego CTE, każde z nich zostaje rozgnieżdżone osobno. Jeśli masz obliczenia niedeterministyczne w wewnętrznym zapytaniu CTE, obliczenia te mogą mieć różne wyniki w różnych odwołaniach.
Powiedzmy na przykład, że wywołujesz funkcję SYSDATETIME w wewnętrznym zapytaniu CTE, tworząc kolumnę wyników o nazwie dt. Ogólnie rzecz biorąc, zakładając brak zmian w danych wejściowych, funkcja wbudowana jest oceniana raz na zapytanie i odwołanie, niezależnie od liczby zaangażowanych wierszy. Jeśli odwołujesz się do CTE tylko raz z zapytania zewnętrznego, ale wielokrotnie wchodzisz w interakcję z kolumną dt, wszystkie odwołania powinny reprezentować tę samą ocenę funkcji i zwracać te same wartości. Jeśli jednak wielokrotnie odwołujesz się do CTE w zapytaniu zewnętrznym, czy to z wieloma podzapytaniami odnoszącymi się do CTE, czy z połączeniem między wieloma instancjami tego samego CTE (powiedzmy, aliasami C1 i C2), odwołania do C1.dt i C2.dt reprezentuje różne oceny podstawowego wyrażenia i może skutkować różnymi wartościami.
Aby to zademonstrować, rozważ następujące trzy partie:
-- Batch 1
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
SELECT @i += 1 WHERE SYSDATETIME() = SYSDATETIME();
PRINT @i;
GO
-- Batch 2
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 FROM C WHERE dt = dt;
PRINT @i;
GO
-- Batch 3
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 WHERE (SELECT dt FROM C) = (SELECT dt FROM C);
PRINT @i;
GO Na podstawie tego, co właśnie wyjaśniłem, czy możesz określić, które partie mają nieskończoną pętlę, a które zatrzymają się w pewnym momencie z powodu dwóch wartości porównawczych predykatu oceniających różne wartości?
Pamiętaj, że powiedziałem, że wywołanie wbudowanej funkcji niedeterministycznej, takiej jak SYSDATETIME, jest oceniane raz na zapytanie i odwołanie. Oznacza to, że w Batch 1 masz dwie różne oceny i po wystarczającej liczbie iteracji pętli dadzą różne wartości. Spróbuj. Ile iteracji zgłosił kod?
Jeśli chodzi o Batch 2, kod ma dwa odniesienia do kolumny dt z tej samej instancji CTE, co oznacza, że oba reprezentują tę samą ocenę funkcji i powinny reprezentować tę samą wartość. W konsekwencji Partia 2 ma nieskończoną pętlę. Uruchom go na dowolny czas, ale w końcu będziesz musiał zatrzymać wykonywanie kodu.
Jeśli chodzi o Batch 3, zewnętrzne zapytanie zawiera dwa różne podzapytania współdziałające z CTE C, z których każde reprezentuje inną instancję, która przechodzi oddzielnie przez proces rozgnieżdżania. Kod nie przypisuje wyraźnie różnych aliasów do różnych wystąpień CTE, ponieważ dwa podzapytania pojawiają się w niezależnych zakresach, ale aby ułatwić zrozumienie, możesz pomyśleć o używaniu różnych aliasów, takich jak C1 w jednym podzapytaniu i C2 w drugim. To tak, jakby jedno podzapytanie współdziałało z C1.dt, a drugie z C2.dt. Różne odniesienia reprezentują różne oceny podstawowego wyrażenia, a zatem mogą skutkować różnymi wartościami. Spróbuj uruchomić kod i zobacz, czy w pewnym momencie się zatrzymuje. Ile iteracji zajęło, zanim się zatrzymało?
Interesujące jest próba zidentyfikowania przypadków, w których masz pojedynczą lub wiele ocen bazowego wyrażenia w planie wykonania zapytania. Rysunek 1 przedstawia graficzne plany wykonania dla trzech partii (kliknij, aby powiększyć).
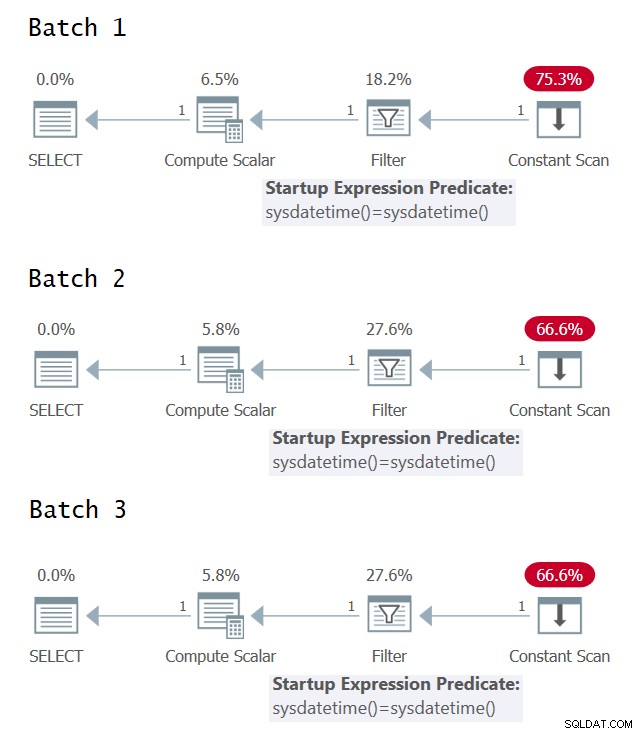 Rysunek 1:Graficzne plany wykonania dla Partii 1, Partii 2 i Partii 3
Rysunek 1:Graficzne plany wykonania dla Partii 1, Partii 2 i Partii 3
Niestety nie ma radości z graficznych planów wykonawczych; wszystkie wydają się identyczne, chociaż semantycznie te trzy partie nie mają identycznych znaczeń. Dzięki @CodeRecce i Forrest (@tsqladdict) jako społeczności udało nam się dotrzeć do sedna sprawy innymi sposobami.
Jak odkrył @CodeRecce, plany XML zawierają odpowiedź. Oto odpowiednie części XML dla trzech partii:
−− Partia 1
…
…
−− Partia 2
…
…
−− Partia 3
…
…
W planie XML dla partii 1 widać wyraźnie, że predykat filtra porównuje wyniki dwóch oddzielnych bezpośrednich wywołań wewnętrznej funkcji SYSDATETIME.
W planie XML dla partii 2 predykat filtra porównuje ze sobą wyrażenie stałe ConstExpr1002 reprezentujące jedno wywołanie funkcji SYSDATETIME.
W planie XML dla partii 3 predykat filtra porównuje dwa różne wyrażenia stałe o nazwach ConstExpr1005 i ConstExpr1006, z których każde reprezentuje oddzielne wywołanie funkcji SYSDATETIME.
Jako inną opcję Forrest (@tsqladdict) zasugerował użycie flagi śledzenia 8605, która pokazuje początkową reprezentację drzewa zapytań utworzoną przez program SQL Server, po włączeniu flagi śledzenia 3604, która powoduje, że dane wyjściowe TF 8605 mają być kierowane do klienta SSMS. Użyj następującego kodu, aby włączyć obie flagi śledzenia:
DBCC TRACEON(3604); -- direct output to client GO DBCC TRACEON(8605); -- show initial query tree GO
Następnie uruchamiasz kod, dla którego chcesz uzyskać drzewo zapytań. Oto odpowiednie części danych wyjściowych, które otrzymałem z TF 8605 dla trzech partii:
−− Partia 1
*** Przekonwertowane drzewo:***
LogOp_Project COL:Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [pusty]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopDodaj
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Nie posiadane,Wartość=1)
−− Partia 2
*** Przekonwertowane drzewo:***
LogOp_Project COL:Expr1001
LogOp_Select
LogOp_ViewKotwica
LogOp_Project
LogOp_ConstTableGet (1) [pusty]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Wyr1001
ScaOp_Arithmetic x_aopDodaj
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Nie posiadane,Wartość=1)
−− Partia 3
*** Przekonwertowane drzewo:***
LogOp_Project COL:Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [pusty]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewKotwica
LogOp_Project
LogOp_ConstTableGet (1) [pusty]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Wyr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Wyr1003
LogOp_Project
LogOp_ViewKotwica
LogOp_Project
LogOp_ConstTableGet (1) [pusty]
AncOp_PrjList
AncOp_PrjEl COL:Wyr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Wyr1003
ScaOp_Identifier COL:Wyr1002
AncOp_PrjList
AncOp_PrjEl COL:Wyr1004
ScaOp_Arithmetic x_aopDodaj
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,brak własności,wartość=1)
W partii 1 można zobaczyć porównanie wyników dwóch oddzielnych ocen funkcji wewnętrznej SYSDATETIME.
W Partii 2 widać jedną ocenę funkcji, której wynikiem jest kolumna o nazwie Expr1000, a następnie porównanie między tą kolumną a nią samą.
W partii 3 widzisz dwie oddzielne oceny funkcji. Jeden w kolumnie o nazwie Expr1000 (później przewidywany przez kolumnę podzapytania o nazwie Expr1001). Kolejna w kolumnie o nazwie Expr1002 (później rzutowana przez kolumnę podzapytania o nazwie Expr1003). Następnie masz porównanie między Expr1001 i Expr1003.
Tak więc, trochę więcej wykopując poza to, co ujawnia graficzny plan wykonania, możesz faktycznie dowiedzieć się, kiedy bazowe wyrażenie jest oceniane tylko raz, a kiedy wiele razy. Teraz, gdy rozumiesz różne przypadki, możesz opracować swoje rozwiązania w oparciu o pożądane zachowanie, którego szukasz.
Funkcje okien z niedeterministycznym porządkiem
Istnieje inna klasa obliczeń, które mogą wpędzić Cię w kłopoty, gdy są używane w rozwiązaniach z wieloma odniesieniami do tego samego CTE. Są to funkcje okien, które opierają się na niedeterministycznym porządkowaniu. Jako przykład weźmy funkcję okna ROW_NUMBER. W przypadku korzystania z częściowego zamawiania (uporządkowanie według elementów, które nie identyfikują jednoznacznie wiersza), każda ocena bazowego zapytania może skutkować innym przypisaniem numerów wierszy, nawet jeśli bazowe dane nie uległy zmianie. W przypadku wielu odwołań CTE pamiętaj, że każde z nich jest niezagnieżdżone osobno i możesz otrzymać różne zestawy wyników. W zależności od tego, co zewnętrzne zapytanie robi z każdym odwołaniem, np. z którymi kolumnami z każdego odwołania wchodzi w interakcję i w jaki sposób, optymalizator może zdecydować o dostępie do danych dla każdej instancji przy użyciu różnych indeksów o różnych wymaganiach dotyczących kolejności.
Rozważ poniższy kod jako przykład:
USE TSQLV5;
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Czy to zapytanie może kiedykolwiek zwrócić niepusty zestaw wyników? Być może twoją pierwszą reakcją jest to, że nie może. Ale pomyśl o tym, co właśnie wyjaśniłem nieco dokładniej, a zdasz sobie sprawę, że przynajmniej teoretycznie, dzięki dwóm oddzielnym procesom rozgnieżdżania CTE, które będą miały tutaj miejsce — jeden z C1, a drugi z C2 — jest to możliwe. Jednak jedną rzeczą jest teoretyzowanie, że coś może się wydarzyć, a inną zademonstrowanie tego. Na przykład, gdy uruchomiłem ten kod bez tworzenia nowych indeksów, otrzymywałem pusty zestaw wyników:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
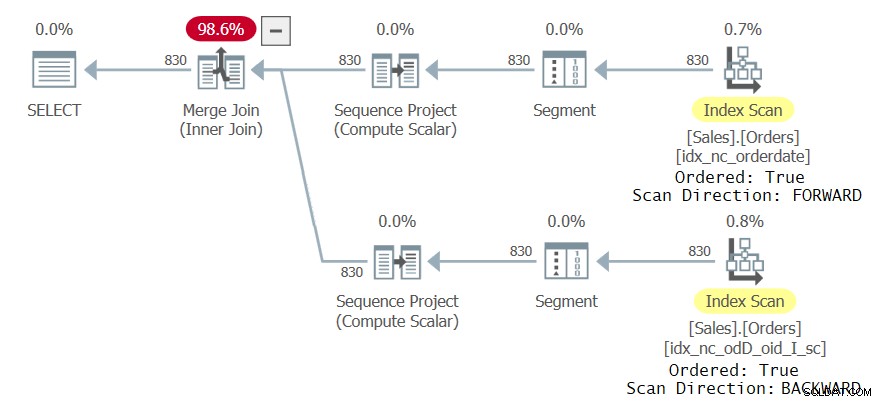
Mam plan pokazany na rysunku 23 dla tego zapytania.
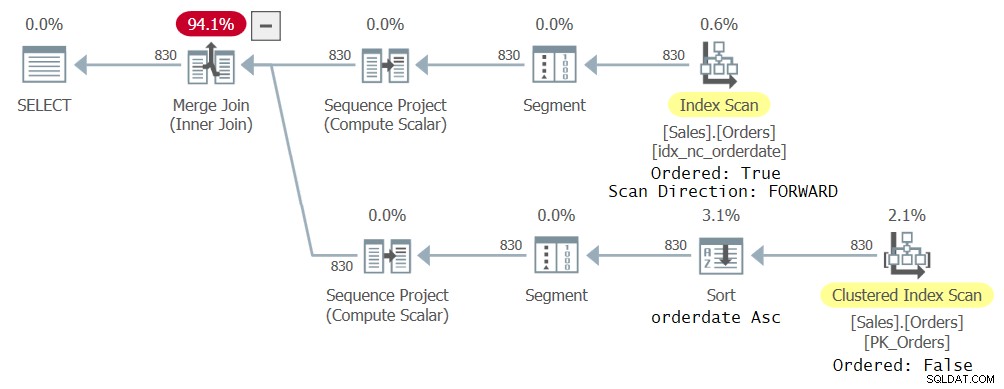 Rysunek 2:Pierwszy plan zapytania z dwoma odniesieniami CTE
Rysunek 2:Pierwszy plan zapytania z dwoma odniesieniami CTE
Co ciekawe, optymalizator zdecydował się na użycie różnych indeksów do obsługi różnych odwołań CTE, ponieważ właśnie to uznał za optymalne. W końcu każde odwołanie w zewnętrznym zapytaniu dotyczy innego podzbioru kolumn CTE. Jedno odwołanie skutkowało uporządkowanym skanowaniem w przód indeksu idx_nc_orderedate, a drugie nieuporządkowanym skanowaniem indeksu klastrowego, po którym następuje operacja sortowania rosnąco według daty zamówienia. Mimo że indeks idx_nc_orderedate jest jawnie zdefiniowany tylko w kolumnie orderdate jako klucz, w praktyce jest zdefiniowany w (orderdate, orderid) jako klucze, ponieważ orderid jest kluczem indeksu klastrowego i jest uwzględniany jako ostatni klucz we wszystkich indeksach nieklastrowanych. Tak więc uporządkowane skanowanie indeksu faktycznie emituje wiersze uporządkowane według daty zamówienia, id zamówienia. Jeśli chodzi o nieuporządkowane skanowanie indeksu klastrowego, na poziomie aparatu magazynu dane są skanowane w kolejności klucza indeksu (na podstawie identyfikatora zamówienia), aby spełnić minimalne oczekiwania co do spójności domyślnego poziomu izolacji zatwierdzonego odczytu. Operator Sort zatem pobiera dane uporządkowane według orderid, sortuje wiersze według orderdate i w praktyce emituje wiersze uporządkowane według orderdate, orderid.
Ponownie, teoretycznie nie ma pewności, że te dwa odniesienia zawsze będą reprezentować ten sam zestaw wyników, nawet jeśli dane bazowe się nie zmienią. Prostym sposobem na zademonstrowanie tego jest ustawienie dwóch różnych optymalnych indeksów dla dwóch odwołań, z których jeden porządkuje dane według daty zamówienia ASC, identyfikatora zamówienia ASC, a drugi porządkuje dane według daty zamówienia DESC, identyfikatora zamówienia ASC (lub dokładnie odwrotnie). Mamy już poprzedni indeks. Oto kod do stworzenia tego ostatniego:
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
Uruchom kod po raz drugi po utworzeniu indeksu:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Otrzymałem następujące dane wyjściowe podczas uruchamiania tego kodu po utworzeniu nowego indeksu:
orderid shipcountry orderid ----------- --------------- ----------- 10251 France 10250 10250 Brazil 10251 10261 Brazil 10260 10260 Germany 10261 10271 USA 10270 ... 11070 Germany 11073 11077 USA 11074 11076 France 11075 11075 Switzerland 11076 11074 Denmark 11077 (546 rows affected)
Ups.
Sprawdź plan zapytania dla tego wykonania, jak pokazano na rysunku 3:
 Rysunek 3:Drugi plan zapytania z dwoma odniesieniami CTE
Rysunek 3:Drugi plan zapytania z dwoma odniesieniami CTE
Zauważ, że górna gałąź planu skanuje indeks idx_nc_orderdate w uporządkowany sposób, powodując, że operator projektu Sequence, który oblicza numery wierszy, pobiera dane w praktyce uporządkowane według orderdate ASC, orderid ASC. Dolna gałąź planu skanuje nowy indeks idx_nc_odD_oid_I_sc w uporządkowany wsteczny sposób, powodując, że operator projektu Sequence pobiera dane w praktyce uporządkowane według daty zamówienia ASC, id zamówienia DESC. Powoduje to inny układ numerów wierszy dla dwóch odwołań CTE, gdy występuje więcej niż jedno wystąpienie tej samej wartości daty zamówienia. W konsekwencji zapytanie generuje niepusty zestaw wyników.
Jeśli chcesz uniknąć takich błędów, jedną z oczywistych opcji jest utrwalenie wewnętrznego wyniku zapytania w obiekcie tymczasowym, takim jak tabela tymczasowa lub zmienna tabeli. Jeśli jednak masz sytuację, w której wolisz trzymać się CTE, prostym rozwiązaniem jest użycie całkowitego porządku w funkcji okna poprzez dodanie rozstrzygnięcia. Innymi słowy, upewnij się, że porządkujesz według kombinacji wyrażeń, które jednoznacznie identyfikują wiersz. W naszym przypadku możesz po prostu dodać orderid jawnie jako rozstrzygający remis, na przykład:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Otrzymasz pusty zestaw wyników zgodnie z oczekiwaniami:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Bez dodawania dalszych indeksów otrzymujesz plan pokazany na rysunku 4:
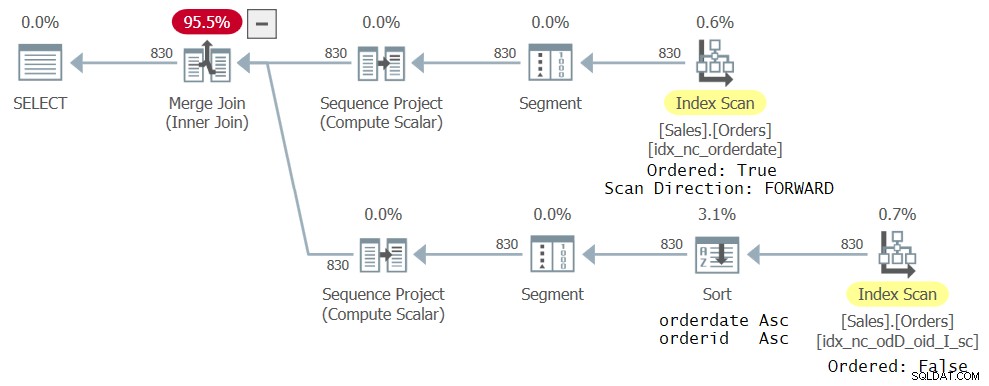 Rysunek 4:Trzeci plan dla zapytania z dwoma odniesieniami CTE
Rysunek 4:Trzeci plan dla zapytania z dwoma odniesieniami CTE
Górna gałąź planu jest taka sama, jak w poprzednim planie pokazanym na rysunku 3. Dolna gałąź jest jednak nieco inna. Nowy indeks utworzony wcześniej nie jest tak naprawdę idealny dla nowego zapytania w tym sensie, że nie ma uporządkowanych danych, jakich potrzebuje funkcja ROW_NUMBER (data zamówienia, identyfikator zamówienia). Jest to nadal najwęższy indeks pokrywający, jaki optymalizator mógł znaleźć dla odpowiedniego odniesienia CTE, więc został wybrany; jednak jest skanowany w sposób Ordered:False. Jawny operator Sort sortuje następnie dane według daty zamówienia, identyfikatora zamówienia, tak jak wymaga obliczeń ROW_NUMBER. Oczywiście można zmienić definicję indeksu, aby zarówno data zamówienia, jak i identyfikator zamówienia używały tego samego kierunku, a w ten sposób jawne sortowanie zostanie wyeliminowane z planu. Najważniejsze jest jednak to, że korzystając z całkowitego uporządkowania, unikasz kłopotów z powodu tego konkretnego błędu.
Kiedy skończysz, uruchom następujący kod w celu oczyszczenia:
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;
Wniosek
Ważne jest, aby zrozumieć, że wiele odwołań do tego samego CTE z zewnętrznego zapytania skutkuje oddzielnymi ocenami wewnętrznego zapytania CTE. Zachowaj szczególną ostrożność przy obliczeniach niedeterministycznych, ponieważ różne oceny mogą skutkować różnymi wartościami.
Podczas korzystania z funkcji okna, takich jak ROW_NUMBER i agregacji z ramką, upewnij się, że używasz całkowitej kolejności, aby uniknąć uzyskiwania różnych wyników dla tego samego wiersza w różnych odwołaniach CTE.