Twoje pytanie jest naprawdę nieprecyzyjny. Proszę, postępuj zgodnie z sugestiami @RiggsFolly i przeczytaj odniesienia, jak zadać dobre pytanie.
Ponadto, zgodnie z sugestią @DuduMarkovitz, powinieneś zacząć od uproszczenia problemu i oczyszczenia danych. Kilka zasobów na początek:
- Podstawowy samouczek przetwarzania tekstu autorstwa Matta Deny'ego
- Obsługa i przetwarzanie ciągów w R autorstwa Gastona Sancheza
Gdy będziesz zadowolony z wyników, możesz przystąpić do identyfikacji grupy dla każdej Var1 wpis (pomoże ci to w dalszej analizie/manipulacji podobnymi wpisami) Można to zrobić na wiele różnych sposobów, ale jak wspomniał @GordonLinoff, jednym z nich jest odległość Levenshteina.
Uwaga :w przypadku 50 000 wpisów wynik nie będzie w 100% dokładny, ponieważ nie będzie zawsze kategoryzować terminy w odpowiedniej grupie, ale powinno to znacznie zmniejszyć ręczne wysiłki.
W R możesz to zrobić używając adist()
Korzystając z przykładowych danych:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
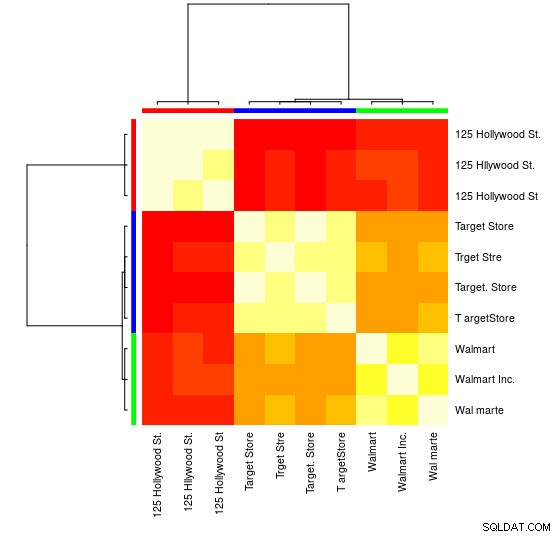
W przypadku tej małej próbki można zobaczyć 3 odrębne grupy (klastry o niskich wartościach odległości Levenstheina) i można je łatwo przypisać ręcznie, ale w przypadku większych zestawów prawdopodobnie będziesz potrzebować algorytmu grupowania.
Wskazałem Ci już w komentarzach do jednego z moich poprzednia odpowiedź
pokazuje, jak to zrobić za pomocą hclust() i metoda minimalnej wariancji Warda, ale myślę, że w tym przypadku lepiej byłoby użyć innych technik (jednym z moich ulubionych źródeł na ten temat zawierającym szybki przegląd niektórych z najczęściej używanych metod w R jest to szczegółowa odpowiedź
)
Oto przykład użycia klastrowania propagacji powinowactwa:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Znajdziesz w obiekcie APResult d_ap elementy związane z poszczególnymi klastrami i optymalna liczba klastrów, w tym przypadku:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Możesz także zobaczyć reprezentację wizualną:
> heatmap(d_ap, margins = c(10, 10))
Następnie możesz wykonać dalsze manipulacje dla każdej grupy. Jako przykład tutaj używam hunspell aby wyszukać każde oddzielne słowo z Var1 w słowniku en_US dla błędów ortograficznych i spróbuj znaleźć w każdej group , który id nie zawiera błędów ortograficznych (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Co daje:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Uwaga :Tutaj, ponieważ nie wykonaliśmy żadnego przetwarzania tekstu, wyniki nie są zbyt jednoznaczne, ale masz pomysł.
Dane
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)