Galera Cluster, ze swoją (praktycznie) synchroniczną replikacją, jest powszechnie używany w wielu różnych typach środowisk. Skalowanie przez dodanie nowych węzłów nie jest trudne (lub wystarczy kilka kliknięć, gdy używasz ClusterControl).
Głównym problemem z replikacją synchroniczną jest, cóż, część synchroniczna, która często powoduje, że cały klaster jest tak szybki, jak jego najwolniejszy węzeł. Każdy zapis wykonywany w klastrze musi zostać zreplikowany do wszystkich węzłów i certyfikowany na nich. Jeśli z jakiegoś powodu proces ten zostanie spowolniony, może to poważnie wpłynąć na zdolność klastra do obsługi zapisów. Następnie uruchomi się kontrola przepływu, aby zapewnić, że najwolniejszy węzeł nadal będzie w stanie nadążyć za obciążeniem. To sprawia, że jest to dość trudne w przypadku niektórych typowych scenariuszy, które mają miejsce w środowisku rzeczywistym.
Najpierw omówmy geograficznie rozproszone odzyskiwanie po awarii. Oczywiście możesz uruchomić klastry w sieci rozległej, ale zwiększone opóźnienie będzie miało znaczący wpływ na wydajność klastra. To poważnie ogranicza możliwość korzystania z takiej konfiguracji, zwłaszcza na dłuższych dystansach, gdy opóźnienie jest wyższe.
Kolejny dość powszechny przypadek użycia - środowisko testowe do aktualizacji głównej wersji. Nie jest dobrym pomysłem łączenie różnych wersji węzłów MariaDB Galera Cluster w tym samym klastrze, nawet jeśli jest to możliwe. Z drugiej strony migracja do nowszej wersji wymaga szczegółowych testów. Najlepiej byłoby, gdyby przetestowano zarówno odczyt, jak i zapis. Jednym ze sposobów na osiągnięcie tego jest utworzenie oddzielnego klastra Galera i uruchomienie testów, ale chciałbyś przeprowadzać testy w środowisku jak najbardziej zbliżonym do produkcyjnego. Po udostępnieniu klaster może być używany do testów z zapytaniami ze świata rzeczywistego, ale trudno byłoby wygenerować obciążenie zbliżone do produkcyjnego. Nie można przenieść części ruchu produkcyjnego do takiego systemu testowego, ponieważ dane nie są aktualne.
Wreszcie sama migracja. Ponownie, to co powiedzieliśmy wcześniej, nawet jeśli możliwe jest łączenie starych i nowych wersji węzłów Galera w tym samym klastrze, nie jest to najbezpieczniejszy sposób.
Na szczęście najprostszym rozwiązaniem wszystkich tych trzech problemów byłoby połączenie osobnych klastrów Galera za pomocą replikacji asynchronicznej. Co sprawia, że jest to tak dobre rozwiązanie? Cóż, jest asynchroniczny, co sprawia, że nie wpływa na replikację Galery. Nie ma kontroli przepływu, zatem wydajność klastra „głównego” nie będzie miała wpływu na wydajność klastra „podrzędnego”. Jak w przypadku każdej replikacji asynchronicznej, może pojawić się opóźnienie, ale dopóki pozostaje w akceptowalnych granicach, może działać doskonale. Należy również pamiętać, że w dzisiejszych czasach asynchroniczna replikacja może być zrównoleglona (wiele wątków może współpracować ze sobą, aby zwiększyć przepustowość) i jeszcze bardziej zmniejszyć opóźnienie replikacji.
W tym poście na blogu omówimy kroki, jakie należy wykonać, aby wdrożyć replikację asynchroniczną między klastrami MariaDB Galera.
Jak skonfigurować replikację asynchroniczną między klastrami MariaDB Galera?
Po pierwsze musimy wdrożyć klaster. Dla naszych celów skonfigurujemy klaster z trzema węzłami. Ograniczymy konfigurację do minimum, dzięki czemu nie będziemy omawiać złożoności aplikacji i warstwy proxy. Warstwa proxy może być bardzo przydatna do obsługi zadań, dla których chcesz wdrożyć replikację asynchroniczną - przekierowując podzbiór ruchu tylko do odczytu do klastra testowego, pomagając w sytuacji odzyskiwania po awarii, gdy „główny” klaster jest niedostępny poprzez przekierowanie ruch do klastra DR. Istnieje wiele serwerów proxy, które możesz wypróbować, w zależności od twoich preferencji - HAProxy, MaxScale lub ProxySQL - wszystkie mogą być używane w takich konfiguracjach i, w zależności od przypadku, niektóre z nich mogą pomóc w zarządzaniu ruchem.
Konfigurowanie klastra źródłowego
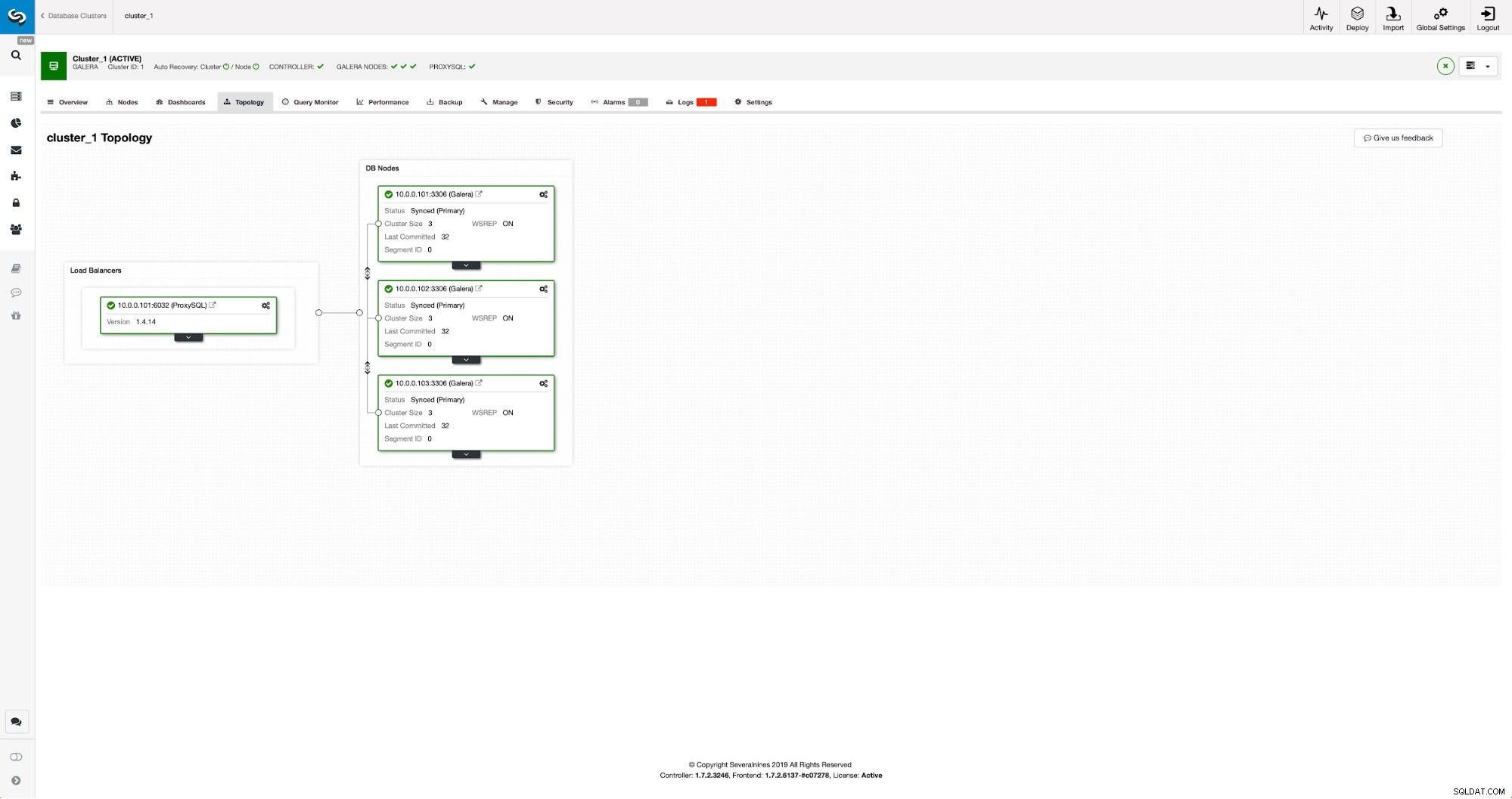
Nasz klaster składa się z trzech węzłów MariaDB 10.3, wdrożyliśmy również ProxySQL w celu podziału odczytu i zapisu oraz dystrybucji ruchu na wszystkie węzły w klastrze. To nie jest wdrożenie na poziomie produkcyjnym, w tym celu musielibyśmy wdrożyć więcej węzłów ProxySQL i na nich Keepalived. To wciąż wystarcza do naszych celów. Aby skonfigurować replikację asynchroniczną, będziemy musieli mieć włączony dziennik binarny w naszym klastrze. Co najmniej jeden węzeł, ale lepiej pozostawić go włączonym na wszystkich z nich na wypadek awarii jedynego węzła z włączonym binlogem – wtedy chcesz, aby kolejny węzeł w klastrze działał i można go było wyłączyć.
Podczas włączania dziennika binarnego upewnij się, że skonfigurowałeś rotację dziennika binarnego, aby stare dzienniki zostały w pewnym momencie usunięte. Użyjesz formatu dziennika binarnego ROW. Powinieneś również upewnić się, że masz skonfigurowane i używane GTID – będzie to bardzo przydatne, gdy będziesz musiał ponownie podporządkować swój „podrzędny” klaster lub jeśli będziesz musiał włączyć replikację wielowątkową. Ponieważ jest to klaster Galera, chcesz mieć skonfigurowane „wsrep_gtid_domain_id” i włączone „wsrep_gtid_mode”. Te ustawienia zapewnią, że identyfikatory GTID będą generowane dla ruchu pochodzącego z klastra Galera. Więcej informacji można znaleźć w dokumentacji. Gdy to wszystko zrobisz, możesz przystąpić do konfigurowania drugiego klastra.
Konfigurowanie klastra docelowego
Biorąc pod uwagę, że obecnie nie ma klastra docelowego, musimy zacząć od jego wdrożenia. Nie będziemy szczegółowo omawiać tych kroków, instrukcje znajdziesz w dokumentacji. Ogólnie rzecz biorąc, proces składa się z kilku kroków:
- Skonfiguruj repozytoria MariaDB
- Zainstaluj pakiety MariaDB 10.3
- Skonfiguruj węzły, aby utworzyć klaster
Na początku zaczniemy od jednego węzła. Możesz skonfigurować je wszystkie tak, aby tworzyły klaster, ale wtedy powinieneś je zatrzymać i użyć tylko jednego do następnego kroku. Ten jeden węzeł stanie się niewolnikiem pierwotnego klastra. Do jej udostępnienia użyjemy mariabackup. Następnie skonfigurujemy replikację.
Najpierw musimy stworzyć katalog, w którym będziemy przechowywać kopię zapasową:
mkdir /mnt/mariabackupNastępnie wykonujemy kopię zapasową i tworzymy ją w katalogu przygotowanym w powyższym kroku. Upewnij się, że używasz prawidłowego użytkownika i hasła, aby połączyć się z bazą danych:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Następnie musimy skopiować pliki kopii zapasowej do pierwszego węzła w drugim klastrze. Użyliśmy do tego scp, możesz użyć, co chcesz - rsync, netcat, cokolwiek, co będzie działać.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Po skopiowaniu kopii zapasowej musimy ją przygotować, stosując pliki dziennika:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!W przypadku jakiegokolwiek błędu może być konieczne ponowne wykonanie kopii zapasowej. Jeśli wszystko poszło dobrze, możemy usunąć stare dane i zastąpić je informacjami z kopii zapasowej
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Chcemy również ustawić właściwego właściciela plików:
chown -R mysql.mysql /var/lib/mysql/Będziemy polegać na GTID, aby zachować spójność replikacji, dlatego musimy zobaczyć, jaki był ostatnio zastosowany GTID w tej kopii zapasowej. Te informacje można znaleźć w pliku xtrabackup_info, który jest częścią kopii zapasowej:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Będziemy również musieli upewnić się, że węzeł podrzędny ma włączone logi binarne wraz z „log_slave_updates”. W idealnym przypadku będzie to włączone na wszystkich węzłach w drugim klastrze - na wypadek awarii węzła „podrzędnego” i konieczności skonfigurowania replikacji przy użyciu innego węzła w klastrze podrzędnym.
Ostatnią czynnością, jaką musimy zrobić, zanim będziemy mogli skonfigurować replikację, jest utworzenie użytkownika, którego użyjemy do uruchomienia replikacji:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)To wszystko, czego potrzebujemy. Teraz możemy uruchomić pierwszy węzeł w drugim klastrze, naszym bycie niewolnikiem:
galera_new_clusterPo uruchomieniu możemy wejść do MySQL CLI i skonfigurować go tak, aby stał się niewolnikiem, korzystając z pozycji GITD, którą znaleźliśmy kilka kroków wcześniej:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Gdy to zrobimy, możemy wreszcie skonfigurować replikację i uruchomić ją:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)W tym momencie mamy klaster Galera składający się z jednego węzła. Węzeł ten jest również niewolnikiem pierwotnego klastra (w szczególności jego głównym węzłem jest węzeł 10.0.0.101). Aby dołączyć do innych węzłów, użyjemy SST, ale aby to zadziałało najpierw musimy upewnić się, że konfiguracja SST jest poprawna - pamiętaj, że właśnie zastąpiliśmy wszystkich użytkowników w naszym drugim klastrze zawartością klastra źródłowego. Teraz musisz upewnić się, że konfiguracja „wsrep_sst_auth” drugiego klastra jest zgodna z konfiguracją pierwszego klastra. Gdy to zrobisz, możesz uruchomić pozostałe węzły jeden po drugim i powinny one dołączyć do istniejącego węzła (10.0.0.104), pobrać dane przez SST i utworzyć klaster Galera. Ostatecznie powinieneś otrzymać dwa klastry, każdy po trzy węzły, z asynchronicznym łączem replikacji (od 10.0.0.101 do 10.0.0.104 w naszym przykładzie). Możesz potwierdzić, że replikacja działa, sprawdzając wartość:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Jak skonfigurować replikację asynchroniczną między klastrami MariaDB Galera za pomocą ClusterControl?
W chwili pisania tego bloga ClusterControl nie ma funkcji konfigurowania replikacji asynchronicznej w wielu klastrach, pracujemy nad tym, gdy to piszę. Niemniej jednak ClusterControl może być bardzo pomocny w tym procesie - pokażemy Ci, jak możesz przyspieszyć żmudne ręczne kroki, korzystając z automatyzacji zapewnianej przez ClusterControl.
Z tego, co pokazaliśmy wcześniej, możemy wywnioskować, że są to ogólne kroki, które należy wykonać podczas konfigurowania replikacji między dwoma klastrami Galera:
- Wdróż nowy klaster Galera
- Dostarcz nowy klaster, używając danych ze starego
- Skonfiguruj nowy klaster (konfiguracja SST, logi binarne)
- Skonfiguruj replikację między starym a nowym klastrem
Pierwsze trzy punkty są czymś, co możesz łatwo zrobić, używając ClusterControl nawet teraz. Pokażemy Ci, jak to zrobić.
Wdróż i udostępnij nowy klaster MariaDB Galera za pomocą ClusterControl
Sytuacja wyjściowa jest podobna - mamy uruchomiony jeden klaster. Musimy założyć drugi. Jedną z nowszych funkcji ClusterControl jest opcja wdrożenia nowego klastra i udostępnienia go przy użyciu danych z kopii zapasowej. Jest to bardzo przydatne przy tworzeniu środowisk testowych, jest to również opcja, której użyjemy do udostępnienia naszego nowego klastra na potrzeby konfiguracji replikacji. Dlatego pierwszym krokiem, który zrobimy, jest utworzenie kopii zapasowej za pomocą mariabackup:
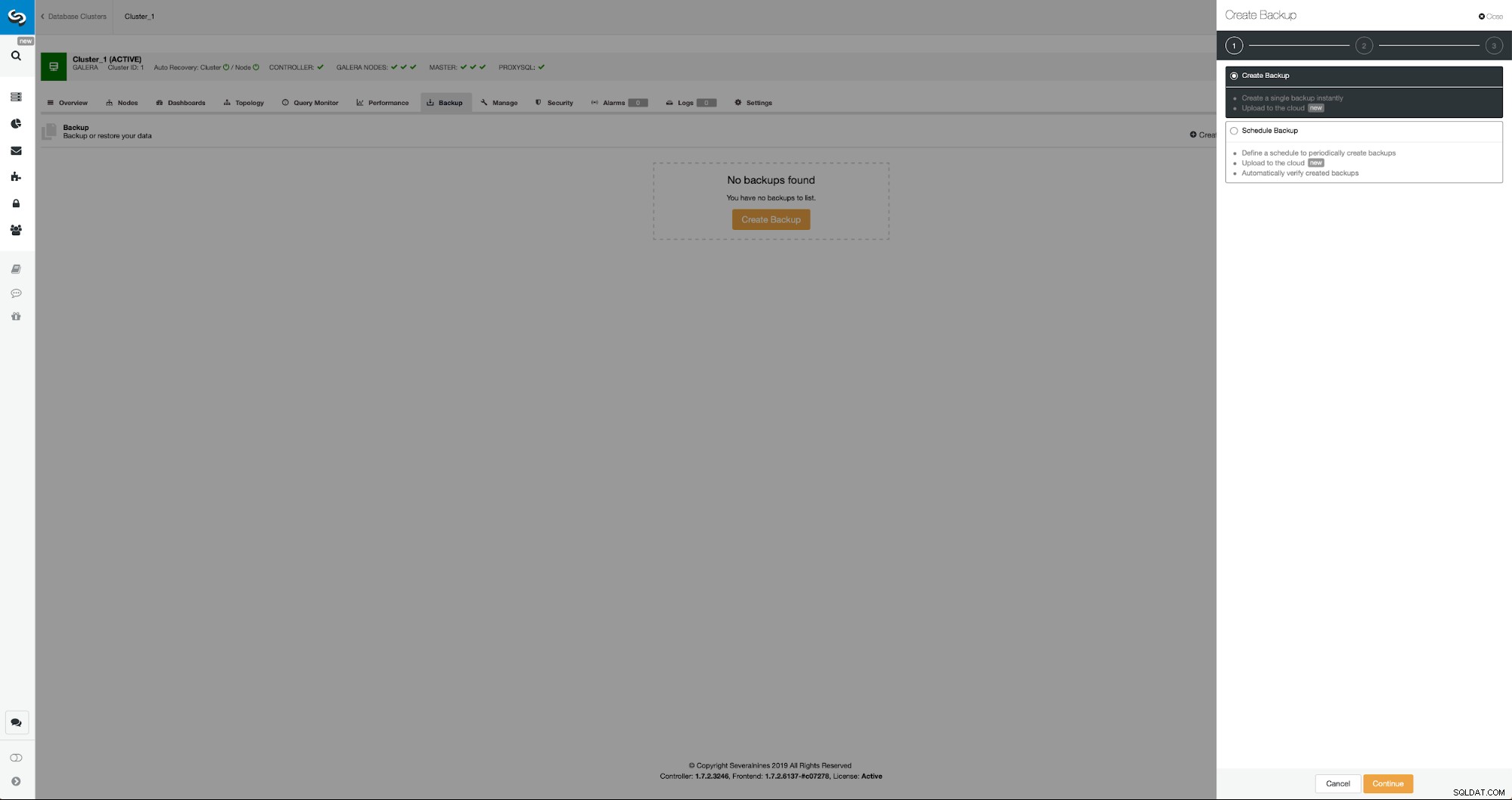
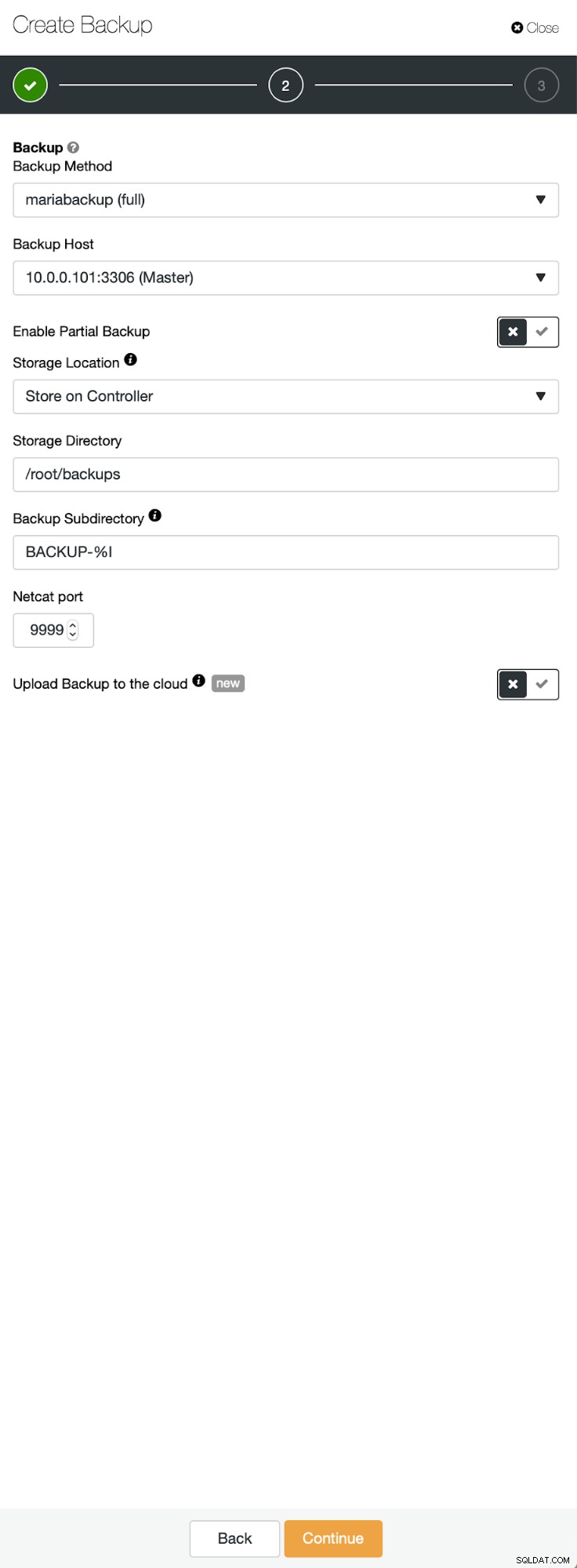
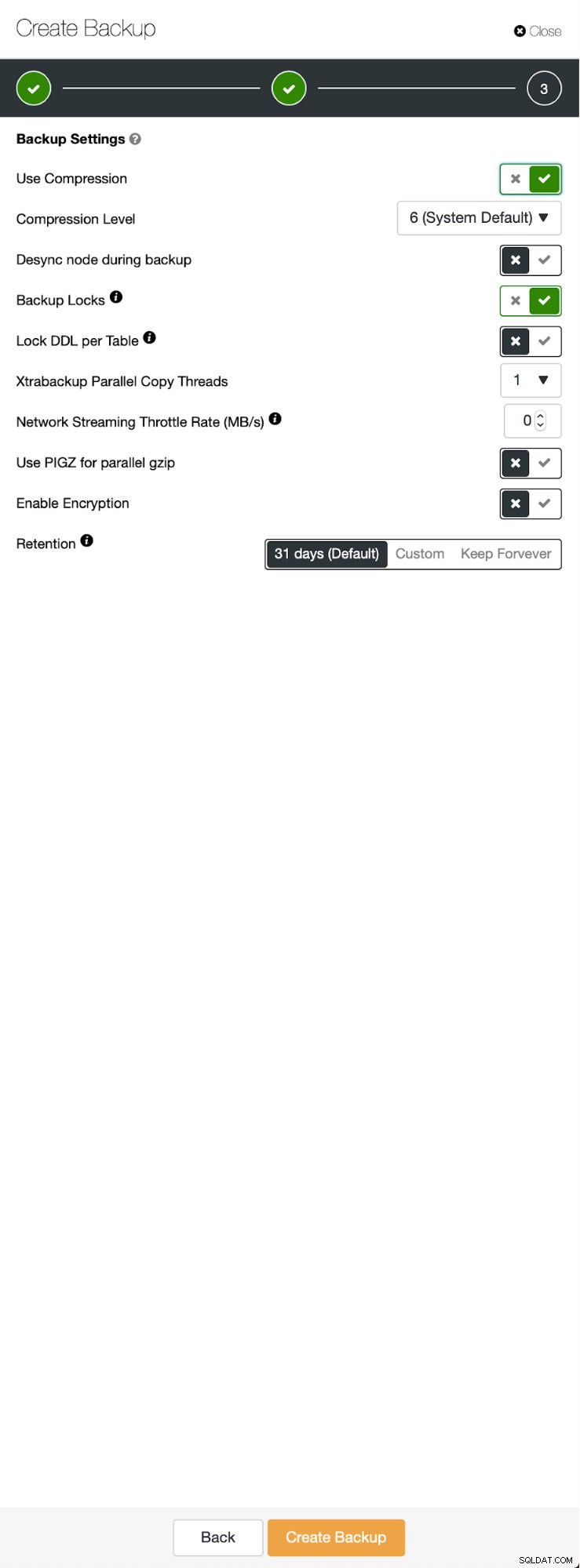
Trzy kroki, w których wybraliśmy węzeł do usunięcia z niego kopii zapasowej. Ten węzeł (10.0.0.101) stanie się masterem. Musi mieć włączone logi binarne. W naszym przypadku wszystkie węzły mają włączony binlog, ale gdyby nie, bardzo łatwo jest włączyć go z ClusterControl - pokażemy kroki później, gdy zrobimy to dla drugiego klastra.
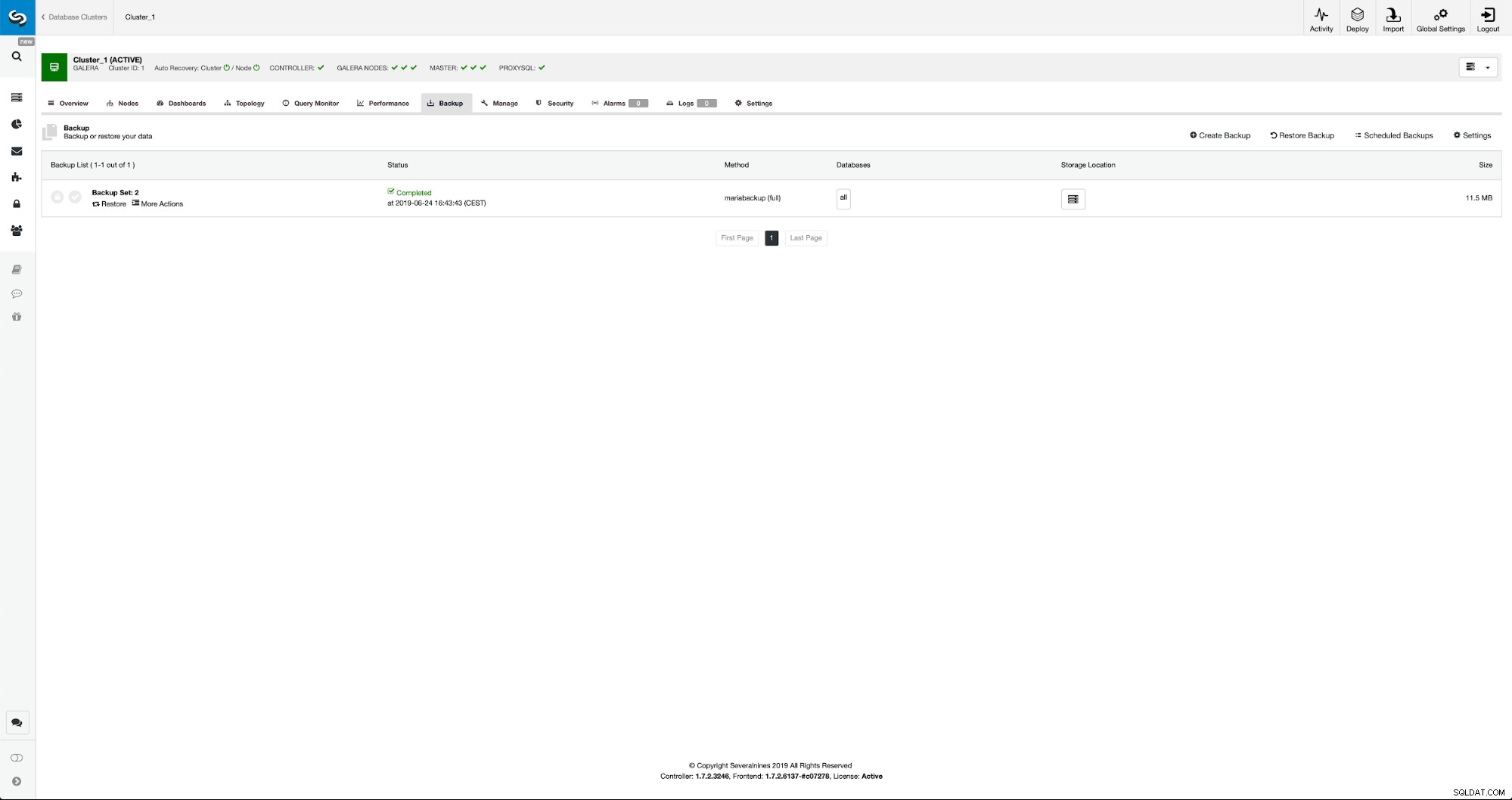
Po zakończeniu tworzenia kopii zapasowej stanie się ona widoczna na liście. Następnie możemy kontynuować i przywrócić go:

Gdybyśmy tego chcieli, moglibyśmy nawet wykonać odzyskiwanie do punktu w czasie, ale w naszym przypadku nie ma to większego znaczenia:po skonfigurowaniu replikacji wszystkie wymagane transakcje z dzienników binarnych zostaną zastosowane w nowym klastrze.

Następnie wybieramy opcję utworzenia klastra z kopii zapasowej. Spowoduje to otwarcie kolejnego okna dialogowego:
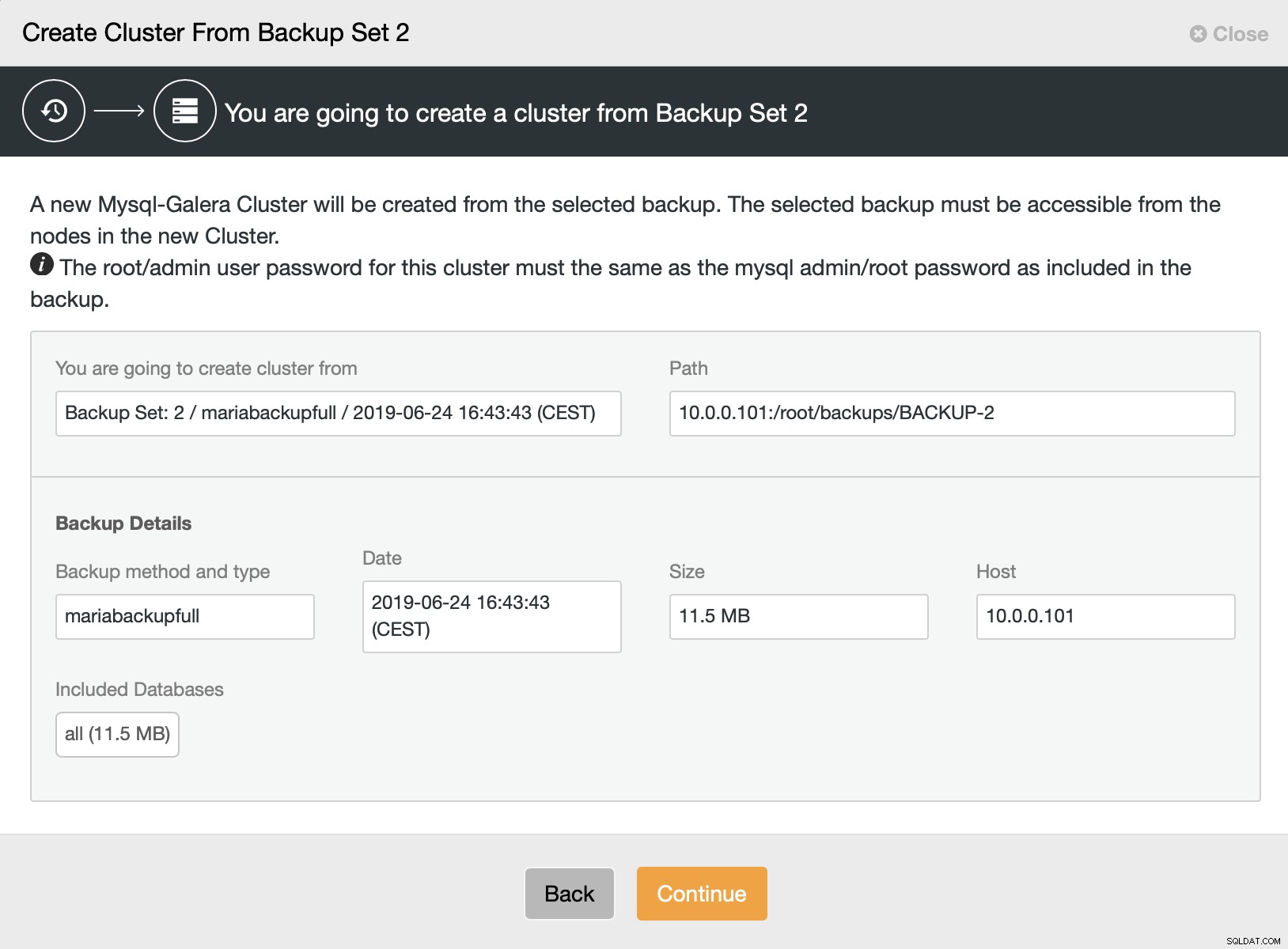
Jest to potwierdzenie, która kopia zapasowa zostanie użyta, z którego hosta została pobrana kopia zapasowa, jaka metoda została użyta do jej utworzenia oraz kilka metadanych, które pomogą zweryfikować, czy kopia zapasowa wygląda prawidłowo.
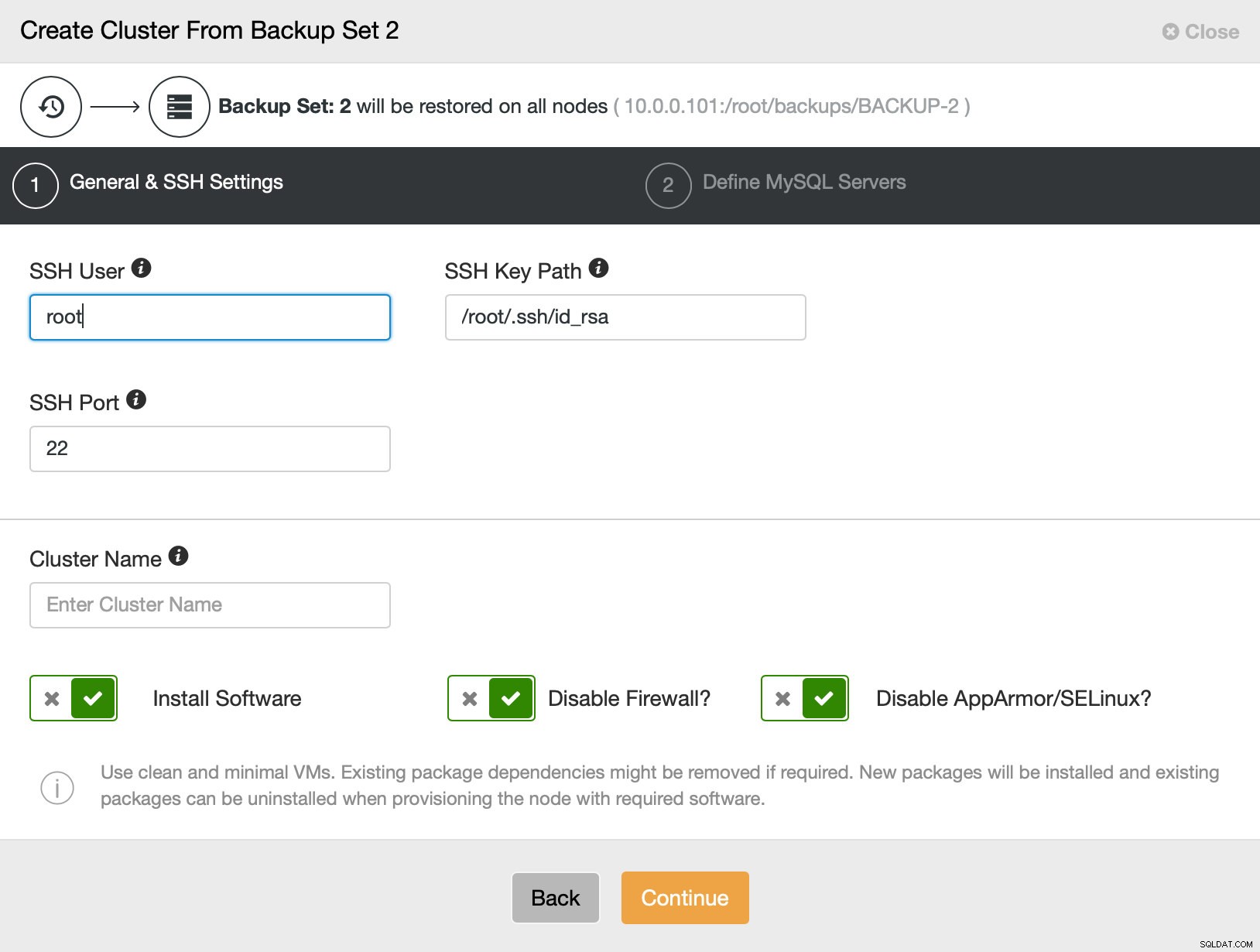
Następnie przechodzimy do zwykłego kreatora wdrażania, w którym musimy zdefiniować łączność SSH między hostem ClusterControl a węzłami, na których ma zostać wdrożony klaster (wymaganie ClusterControl), a w drugim kroku, dostawca, wersja, hasło i węzły do wdrożenia w dniu:
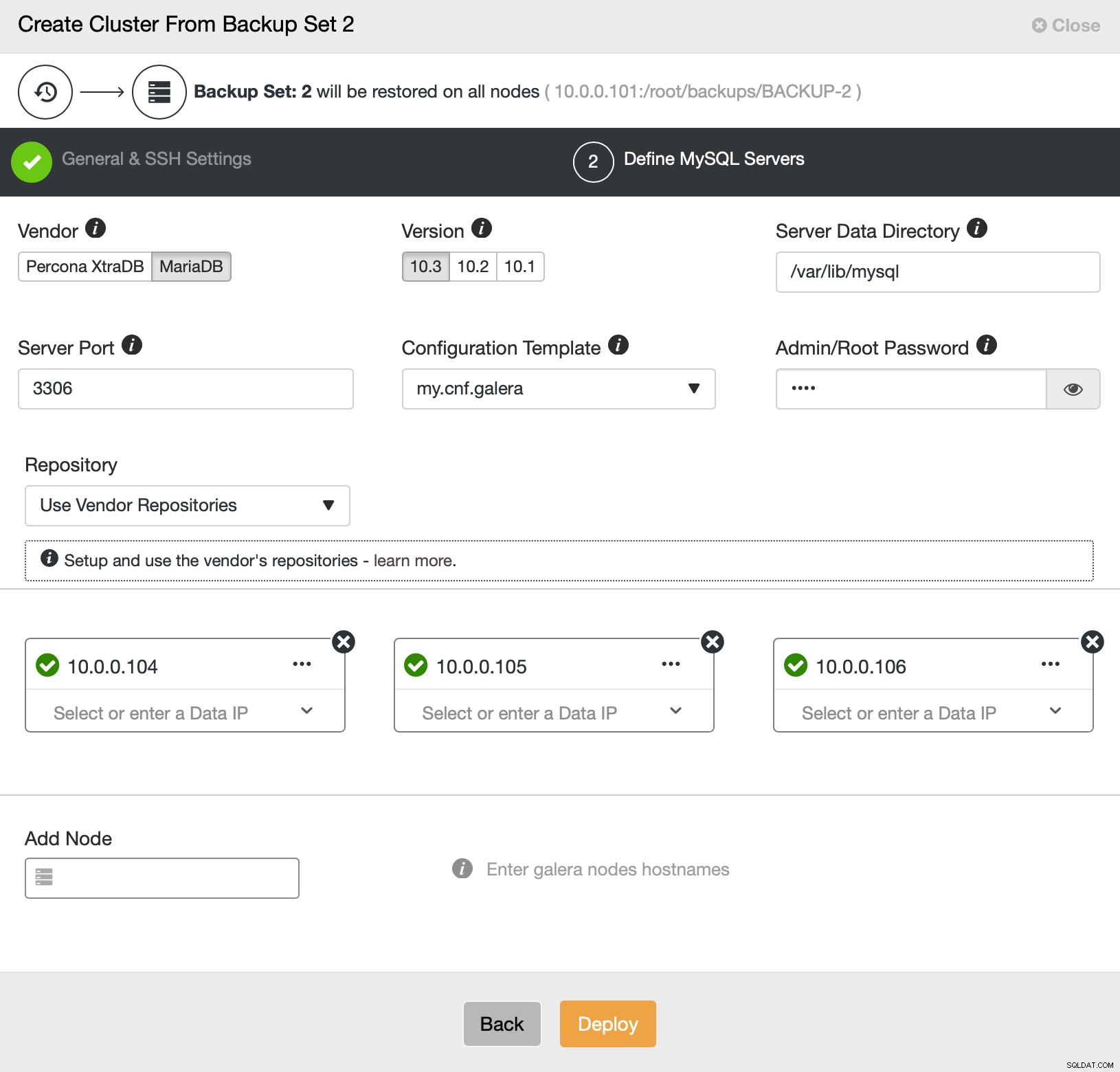
To wszystko, jeśli chodzi o wdrażanie i udostępnianie. ClusterControl skonfiguruje nowy klaster i udostępni go przy użyciu danych ze starego.
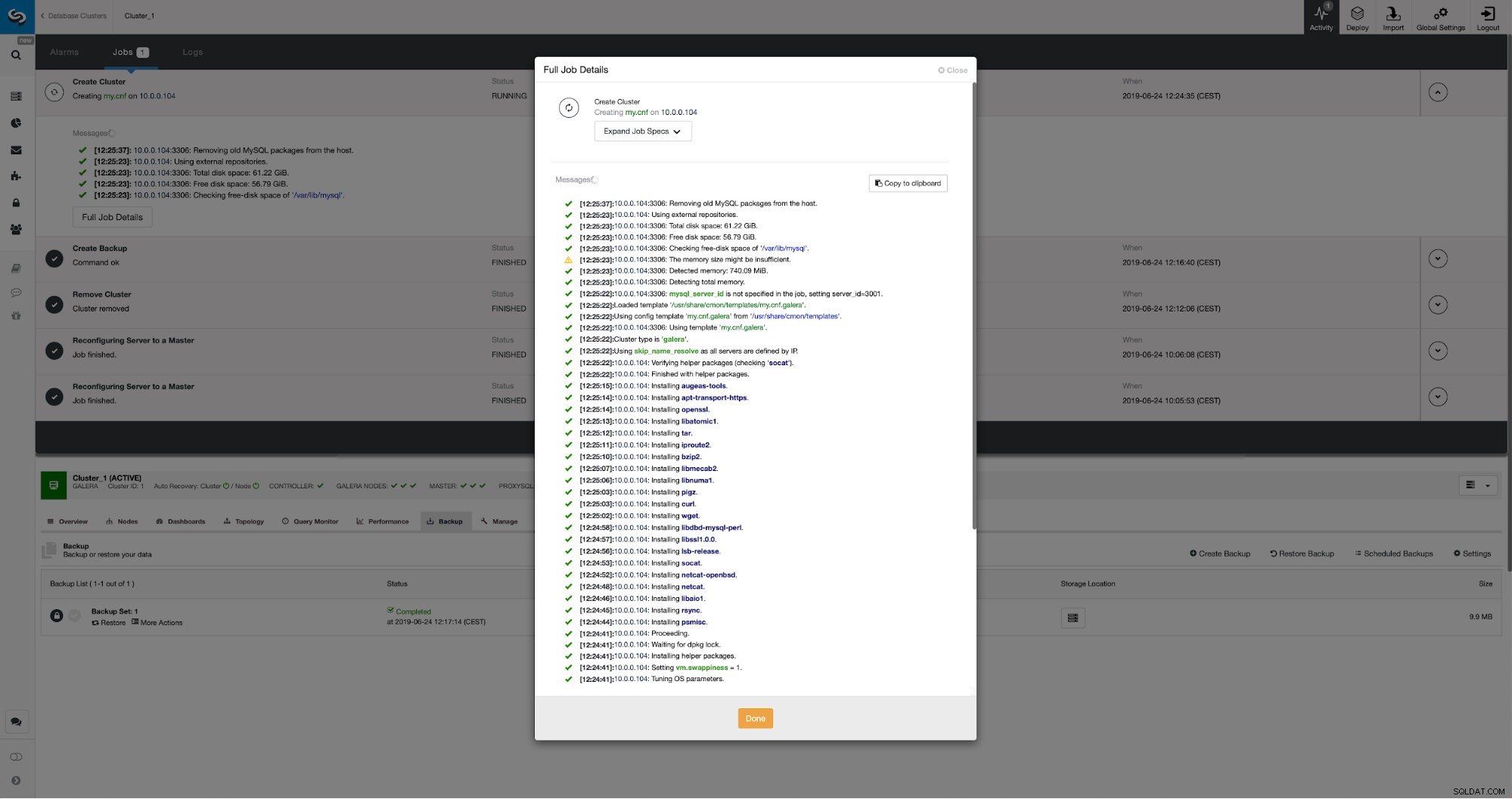
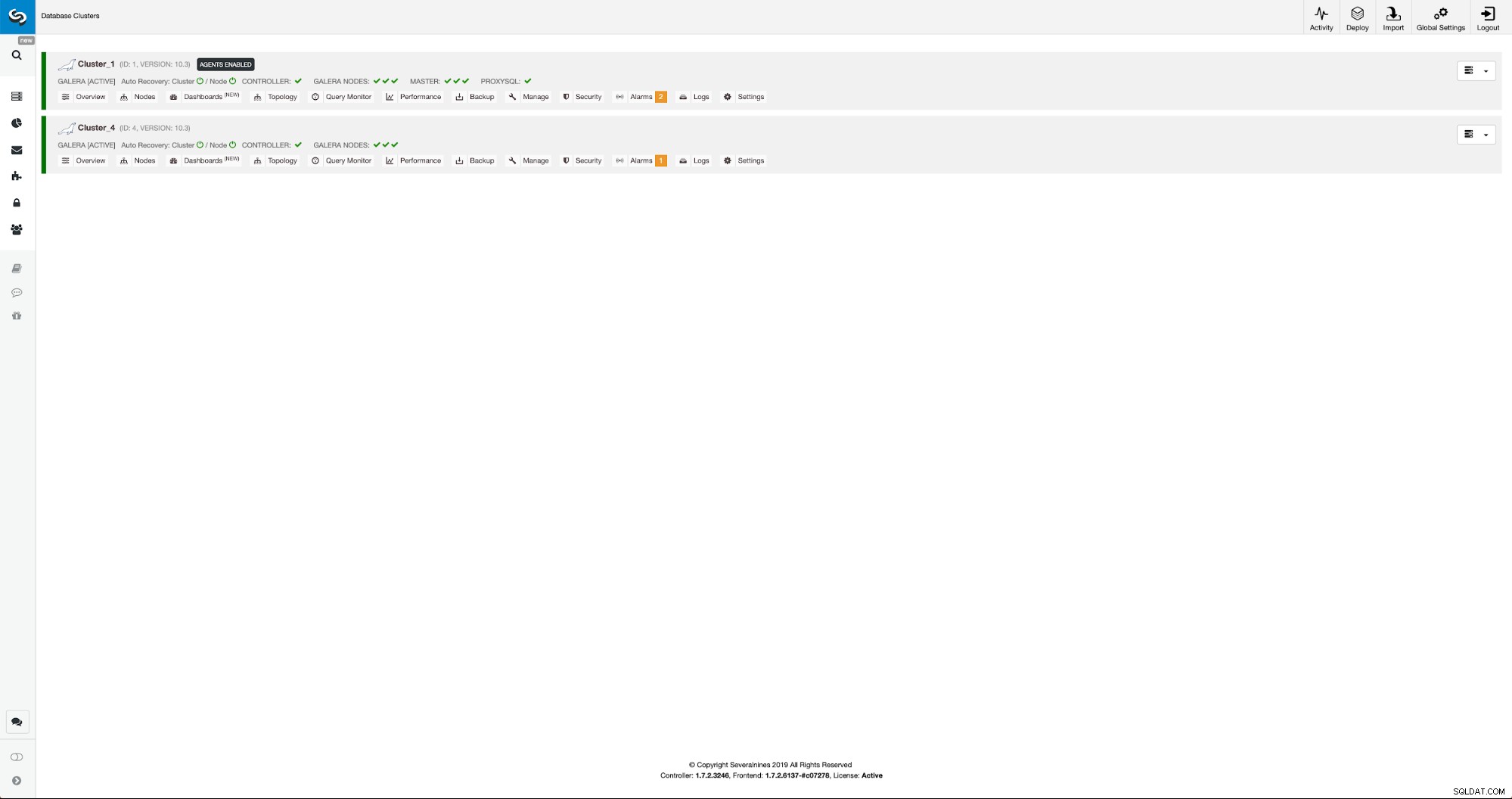
Postęp możemy monitorować w zakładce aktywności. Po zakończeniu drugi klaster pojawi się na liście klastrów w ClusterControl.
Ponowna konfiguracja nowego klastra za pomocą ClusterControl
Teraz musimy przekonfigurować klaster - włączymy logi binarne. W procesie ręcznym musieliśmy wprowadzić zmiany w konfiguracji wsrep_sst_auth, a także wpisy konfiguracyjne w sekcjach [mysqldump] i [xtrabackup] konfiguracji. Ustawienia te można znaleźć w pliku secrets-backup.cnf. Tym razem nie jest to potrzebne, ponieważ ClusterControl wygenerował nowe hasła dla klastra i poprawnie skonfigurował pliki. Należy jednak pamiętać, że jeśli zmienisz hasło użytkownika „backupuser”@„127.0.0.1” w pierwotnym klastrze, będziesz musiał dokonać zmian w konfiguracji również w drugim klastrze, aby odzwierciedlić to jako zmiany w pierwszy klaster zreplikuje się do drugiego klastra.
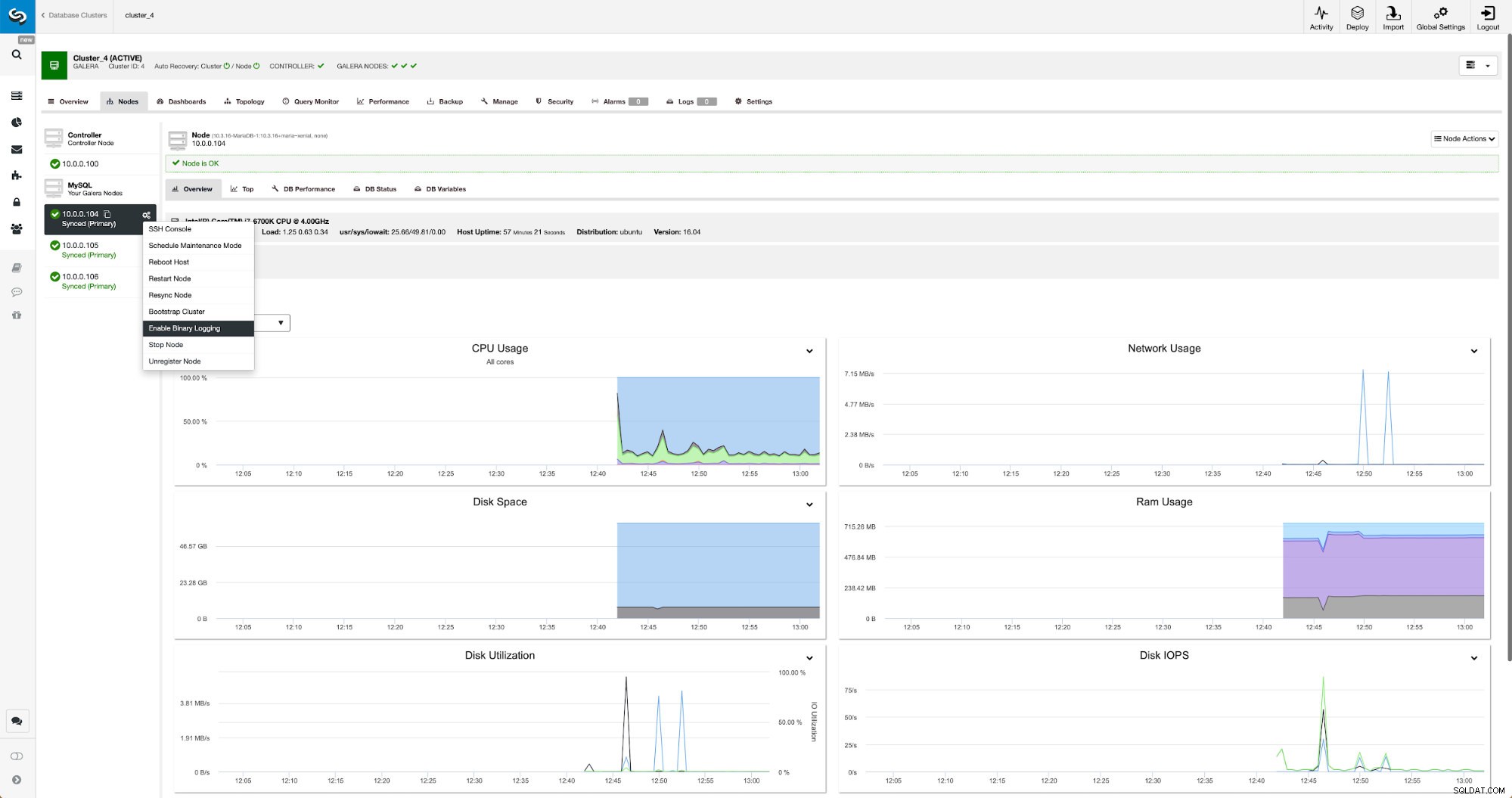
Dzienniki binarne można włączyć w sekcji Węzły. Musisz wybrać węzeł po węźle i uruchomić zadanie „Włącz rejestrowanie binarne”. Zostanie wyświetlone okno dialogowe:
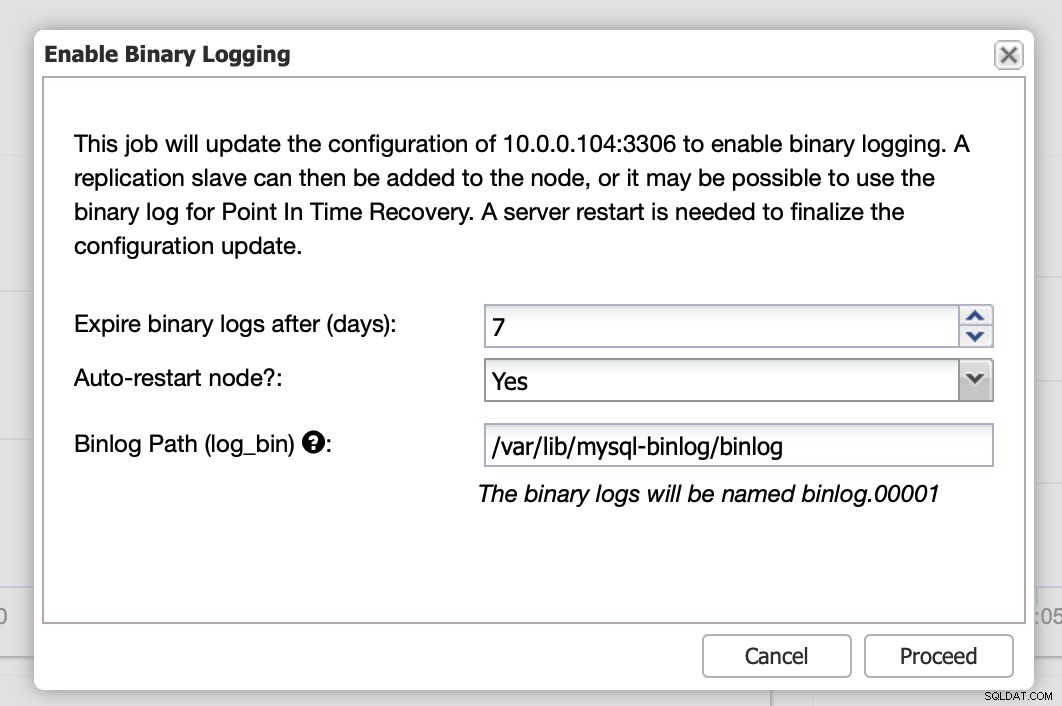
Tutaj możesz określić, jak długo chcesz przechowywać dzienniki, gdzie powinny być przechowywane i czy ClusterControl powinien ponownie uruchomić węzeł w celu zastosowania zmian — konfiguracja dziennika binarnego nie jest dynamiczna i MariaDB musi zostać ponownie uruchomiona, aby zastosować te zmiany.
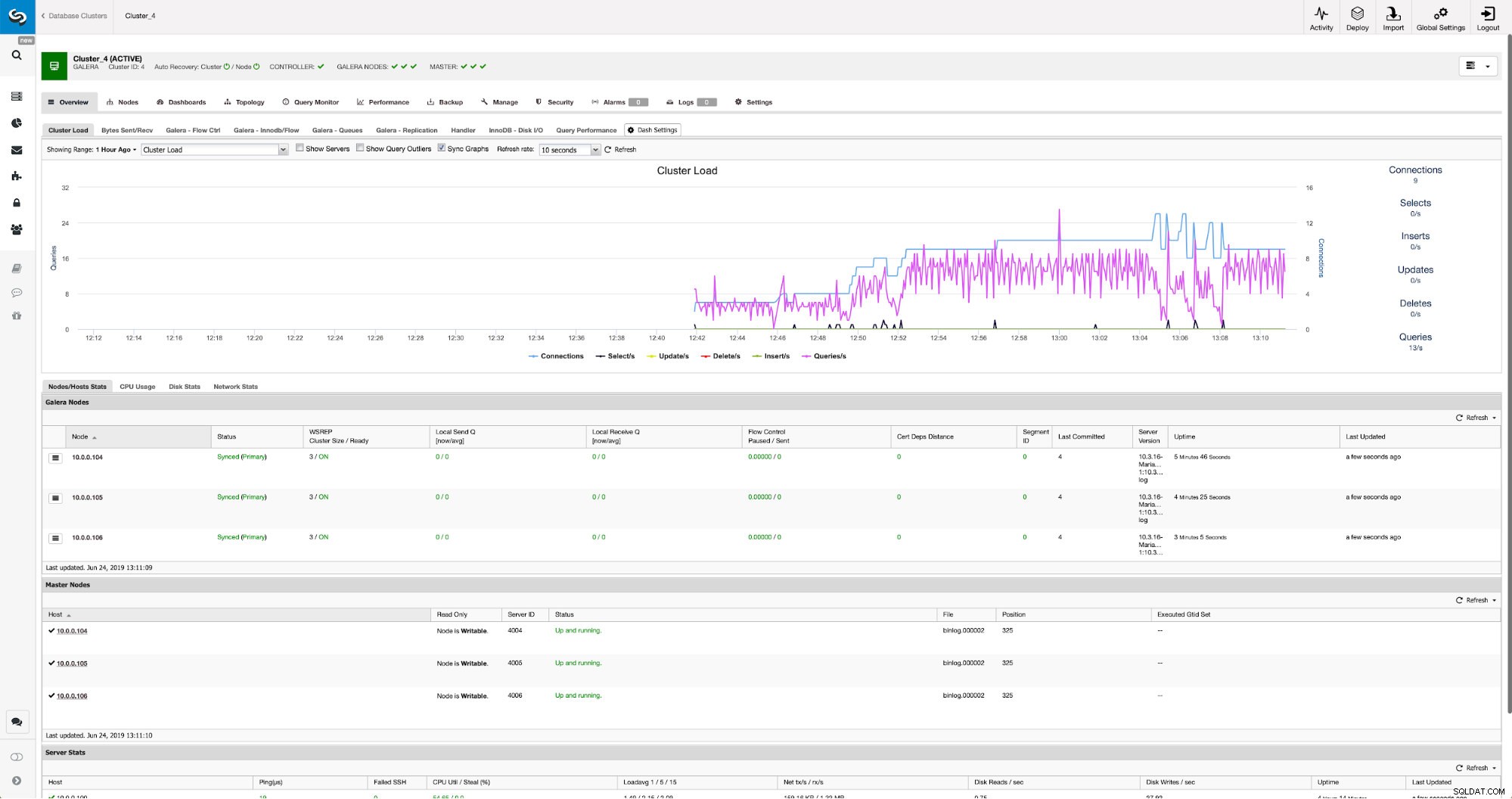
Kiedy zmiany zostaną zakończone, zobaczysz wszystkie węzły oznaczone jako „master”, co oznacza, że te węzły mają włączony log binarny i mogą działać jako master.
Jeśli nie mamy jeszcze utworzonego użytkownika replikacji, musimy to zrobić. W pierwszym klastrze musimy przejść do Zarządzaj -> Schematy i Użytkownicy:
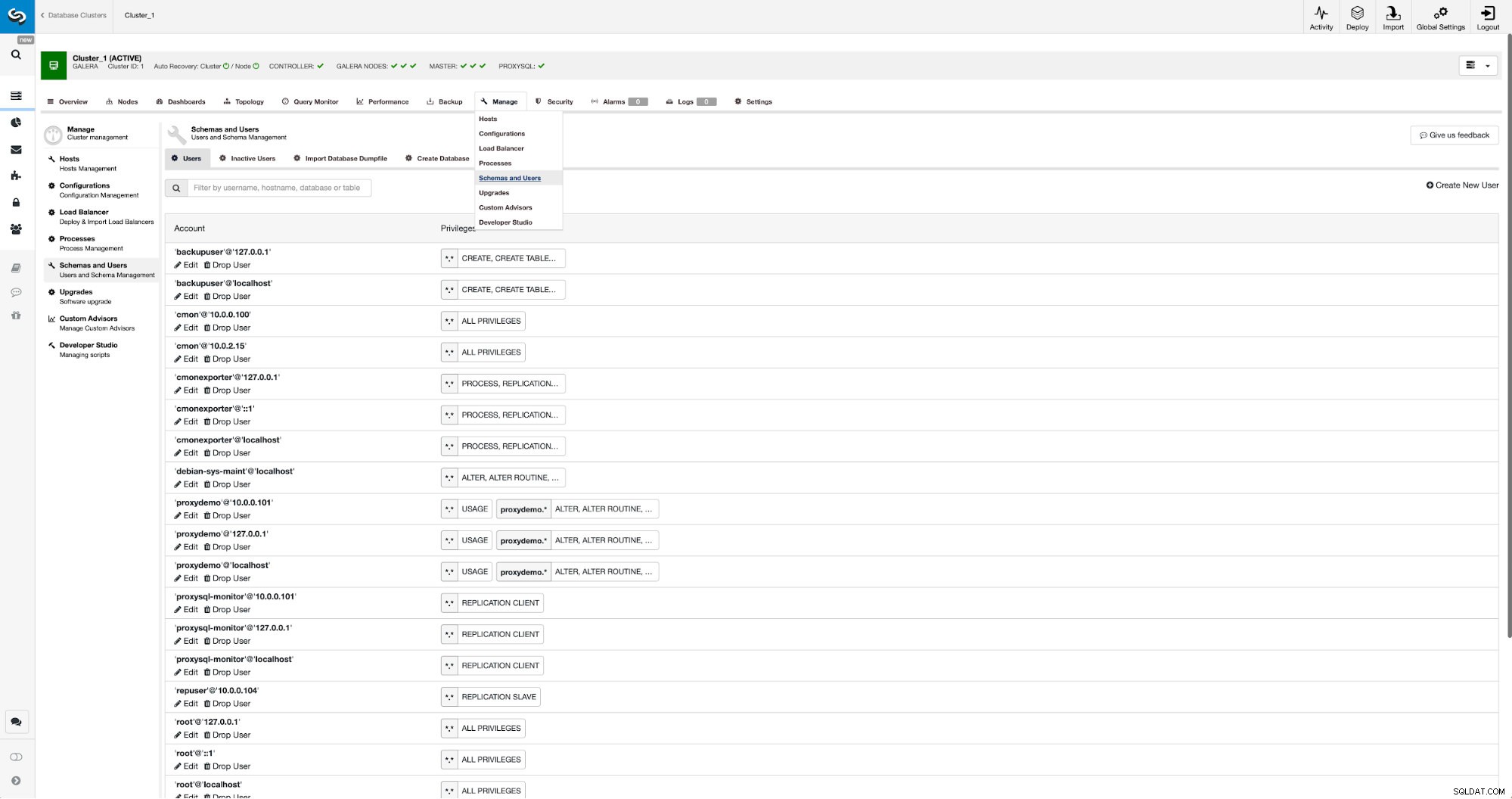
Po prawej stronie mamy opcję utworzenia nowego użytkownika:
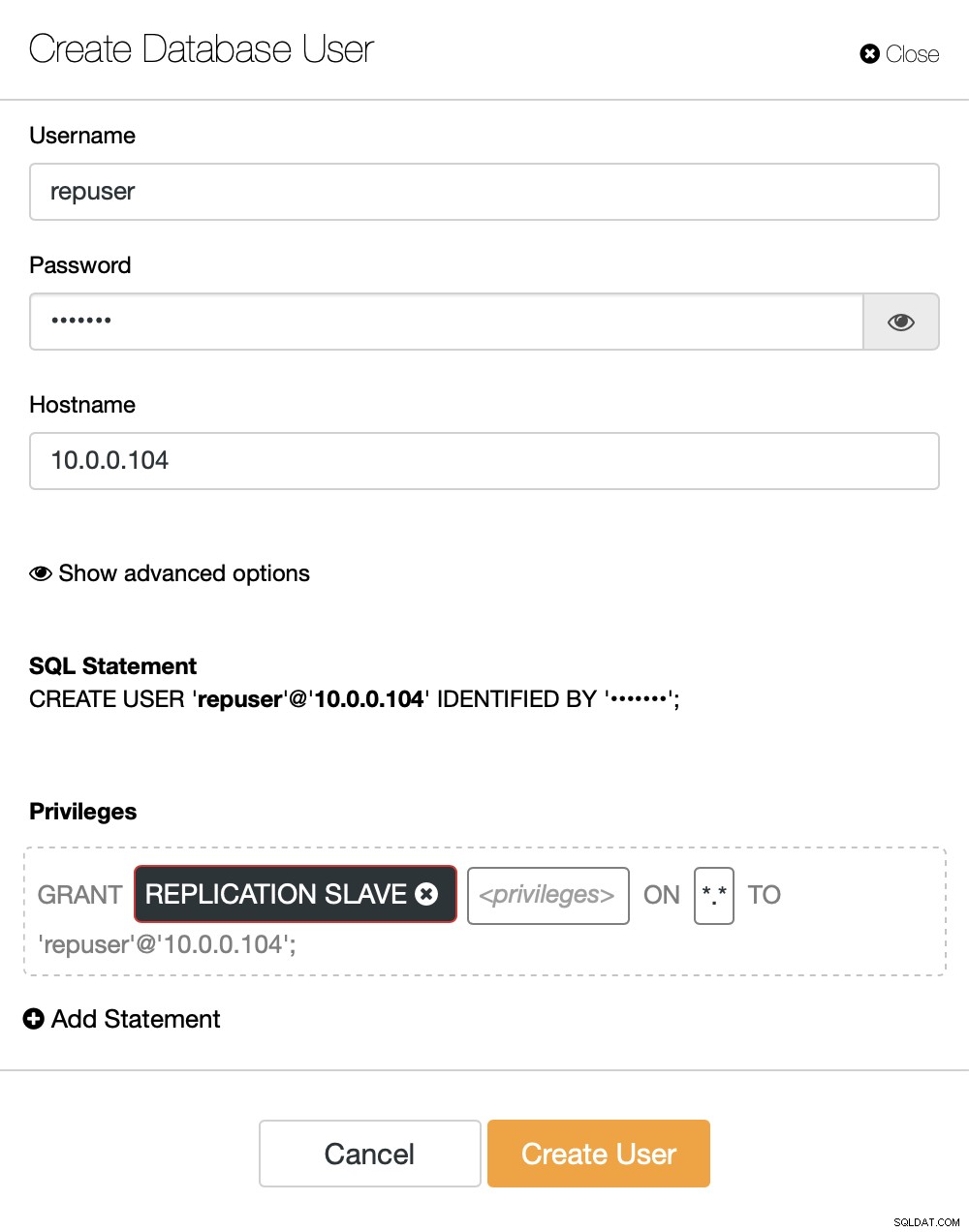
Na tym kończy się konfiguracja wymagana do skonfigurowania replikacji.
Konfigurowanie replikacji między klastrami za pomocą ClusterControl
Jak już wspomnieliśmy, pracujemy nad zautomatyzowaniem tej części. Obecnie trzeba to zrobić ręcznie. Jak być może pamiętasz, potrzebujemy pozycji GITD naszej kopii zapasowej, a następnie uruchamiamy kilka poleceń za pomocą MySQL CLI. Dane GTID są dostępne w kopii zapasowej. ClusterControl tworzy kopię zapasową za pomocą xbstream/mbstream, a następnie ją kompresuje. Nasza kopia zapasowa jest przechowywana na hoście ClusterControl, gdzie nie mamy dostępu do pliku binarnego mbstream. Możesz spróbować go zainstalować lub skopiować plik kopii zapasowej do lokalizacji, w której taki plik binarny jest dostępny:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Gdy to zrobimy, 10.0.0.104 chcemy sprawdzić zawartość pliku xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Na koniec konfigurujemy replikację i uruchamiamy ją:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)To wszystko — właśnie skonfigurowaliśmy replikację asynchroniczną między dwoma klastrami MariaDB Galera za pomocą ClusterControl. Jak widać, ClusterControl był w stanie zautomatyzować większość kroków, które musieliśmy wykonać, aby skonfigurować to środowisko.