Wprowadzenie
Ustalenie, jakiego rodzaju infrastruktury bazy danych potrzebujesz, aby spełnić wymagania dotyczące wydajności, niezawodności i skalowania aplikacji, może być trudnym zadaniem. Wybory dokonane dla topologii bazy danych mogą mieć wpływ na to, jak cały stos aplikacji reaguje na różne typy użycia i jakie scenariusze awarii może uwzględniać. Z tego powodu ważne jest, aby zrozumieć swoje możliwości i podjąć świadomą decyzję, która jest zgodna z Twoimi celami.
Istnieje wiele różnych sposobów przejścia od jednej bazy danych obsługującej wszystkie potrzeby związane z infrastrukturą do bardziej złożonych systemów. Wraz z tym należy rozważyć wiele kompromisów.
W tym przewodniku przedstawimy niektóre z najczęstszych wzorców infrastruktury relacyjnej bazy danych oraz ich dopasowanie do różnych wzorców użytkowania. Przejdziemy przez zalety każdej konfiguracji, a także o niektórych niedociągnięciach, które należy uwzględnić. Porozmawiamy również o wpływie różnych decyzji na ogólną złożoność operacji. Po zakończeniu powinieneś być w stanie podjąć lepszą decyzję o tym, jakie projekty najlepiej pasują do Twoich aktualnych potrzeb i z jakimi opcjami możesz chcieć poeksperymentować, gdy zmienią się Twoje potrzeby.
Skalowanie w pionie
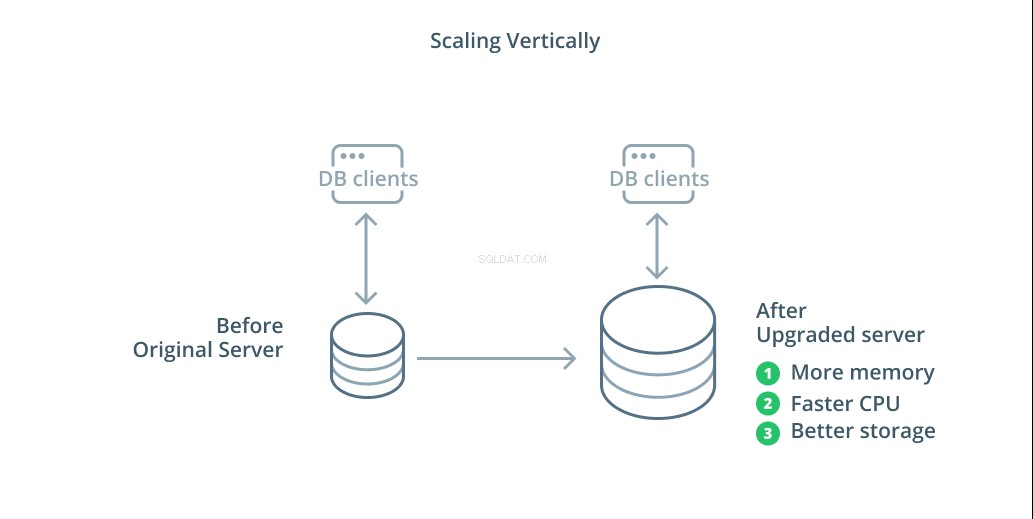
Najprostszym sposobem skalowania systemu bazy danych jest skalowanie w pionie. Skalowanie w pionie , zwany także skalowaniem , oznacza zwiększenie pojemności serwera zarządzającego bazą danych. Zwiększając moc obliczeniową, alokację pamięci lub pojemność pamięci, możesz zwiększyć wydajność i objętość, z jaką może obsłużyć system baz danych bez zwiększania złożoności systemu jako całości.
Zasadniczo skalowanie bazy danych jest dobrym pierwszym krokiem, ponieważ zwiększa możliwości bazy danych bez wpływu na topologię infrastruktury. Skalowanie w górę jest zwykle również dość proste, ponieważ maszyna o większej pojemności może być skonfigurowana jako podążająca za replikacją, dopóki nie zostanie zsynchronizowana, a następnie może zostać uruchomione przełączenie awaryjne, aby uczynić go nowym serwerem głównym.
Skalowanie w górę ma jednak swoje ograniczenia, ponieważ ilość zasobów, które można racjonalnie przydzielić do jednej maszyny, jest ograniczona. Reprezentuje również pojedynczy punkt awarii, jeśli nie skonfigurowano zwolenników replikacji do przejęcia zadań w przypadku wystąpienia problemów. Problemy te są rozwiązywane przez niektóre inne opcje skalowania.
Segregacja odpowiedzialności za zapytania poleceń (CQRS) i repliki tylko do odczytu
Innym podstawowym sposobem skalowania infrastruktury bazy danych jest skalowanie w poziomie. Skalowanie oznacza, że zamiast zwiększać pojemność pojedynczego serwera, zwiększasz liczbę serwerów dedykowanych do obsługi określonej potrzeby. Zwiększasz więc wydajność, dodając dodatkowe maszyny do swojej infrastruktury.
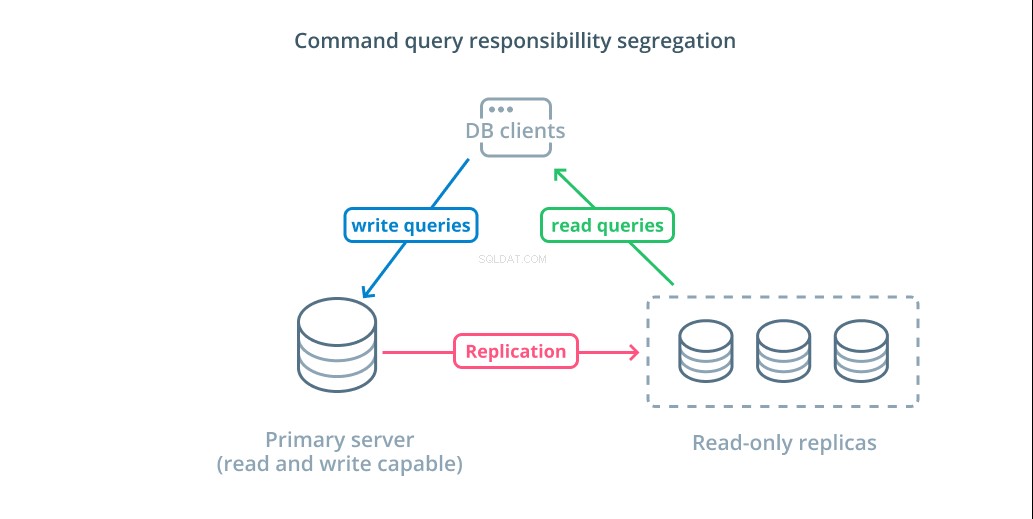
Rozdzielenie odpowiedzialności za zapytania dotyczące poleceń (CQRS) to termin używany do opisania logiki dodawania w celu oddzielenia zapytań, które mutują dane (zapis zapytań) od tych, które tego nie robią (odczytaj zapytania). Pozwala to na kierowanie tych różnych kategorii żądań do różnych hostów, aby pomóc w rozłożeniu obciążenia.
Najbardziej podstawową infrastrukturą, w której można skorzystać z tego projektu, jest serwer główny, który może akceptować zapytania odczytu i zapisu w połączeniu z co najmniej jednym serwerem replik, znajdującym się za serwerem głównym, który może akceptować zapytania odczytu. Ten projekt jest odpowiedni dla wzorców użytkowania aplikacji, które są intensywnie odczytywane, ponieważ operacje odczytu mogą być obsługiwane przez dowolny serwer bazy danych.
Dodatkowo ten system zapewnia pewną redundancję w Twojej architekturze, ponieważ system będzie nadal działał, jeśli którykolwiek z serwerów ulegnie awarii. Jeśli obserwujący przestanie działać, żądania odczytu mogą być kierowane do innych serwerów. Jeśli serwer główny ulegnie awarii, jeden z obserwatorów repliki może zostać awansowany do akceptowania zapytań zapisu.
Multi-primary-replication
Chociaż używanie CQRS z replikami tylko do odczytu pomaga w adresowaniu większej liczby żądań odczytu, nie ma to znaczącego wpływu na wydajność zapisu w infrastrukturze. Aby zwiększyć liczbę zapisów, które może obsłużyć Twoja architektura, musisz rozważyć, czy możesz zastosować projekt replikacji z wieloma podstawowymi danymi.
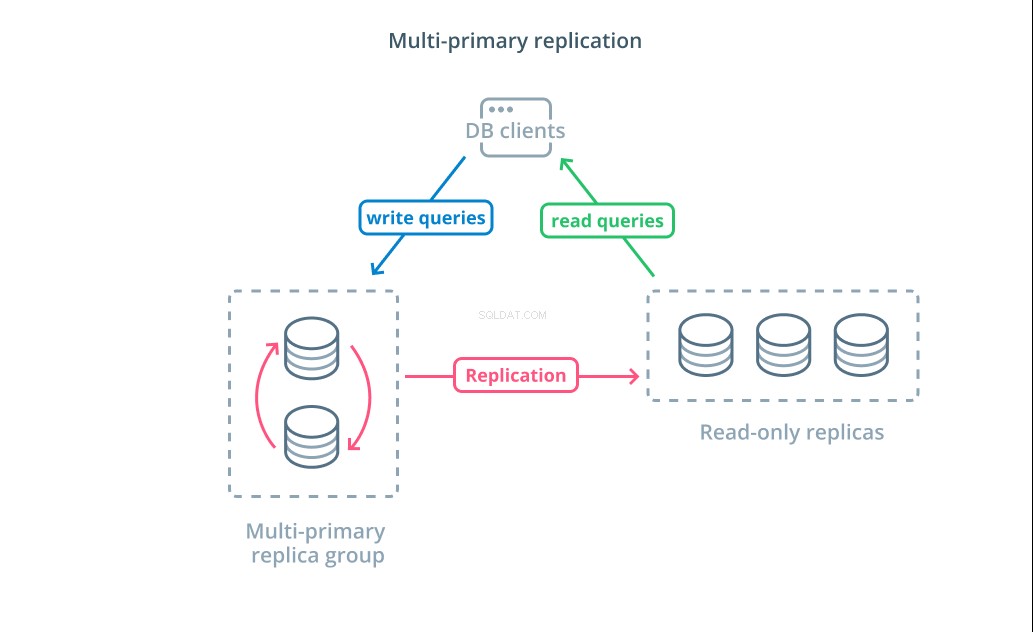
Replikacja wielu podstawowych to forma replikacji, w której wiele serwerów może akceptować żądania zapisu. Niektóre systemy są skonfigurowane w taki sposób, że każdy serwer może przetwarzać żądania zapisu, podczas gdy inne są zaprojektowane tak, aby podstawowa grupa serwerów podstawowych obsługiwała zapisy z większą liczbą obserwatorów tylko do odczytu. Niezależnie od implementacji, replikacja wieloelementowa zwiększa liczbę serwerów odpowiedzialnych za zapytania zapisu.
Chociaż ten projekt na początku brzmi idealnie, istnieją pewne poważne wyzwania, które uniemożliwiają mu to, aby był powszechnie stosowanym wzorcem. Chociaż wiele serwerów może obsługiwać żądania zapisu, nadal muszą koordynować replikację zmian między swoimi serwerami i rozwiązywać konflikty w zmianach danych. Może to prowadzić albo do długich czasów odpowiedzi, gdy negocjowane są konflikty, albo do możliwości niespójnych danych.
Każdy system wybiera własne podejście do radzenia sobie z tymi wyzwaniami. To jest demonstracja twierdzenia CAP — stwierdzenie opisujące współzależność między spójnością, dostępnością i tolerancją partycji w systemach rozproszonych — w działaniu. Niektóre systemy oferują słabsze gwarancje spójności w celu utrzymania dostępności, podczas gdy inne bazy danych odmawiają akceptacji zmian, jeśli ich peery nie mogą koordynować transakcji w momencie zapisu. Wybór podejścia, które najlepiej odpowiada Twoim potrzebom, jest ważnym czynnikiem przy podejmowaniu decyzji między różnymi implementacjami.
Buforowanie zapytań odczytu
Chociaż korzystanie z replik tylko do odczytu jest sposobem na zwiększenie dostępnych baz danych, które mogą odpowiadać na żądania odczytu, nie poprawia to podstawowej wydajności zapytań złożonych operacji odczytu. Oczekuje się, że jeden z serwerów nadal wykona operację odczytu za każdym razem, gdy zostanie wysłane żądanie, nawet jeśli wyniki są identyczne jak w poprzednim wyszukiwaniu.
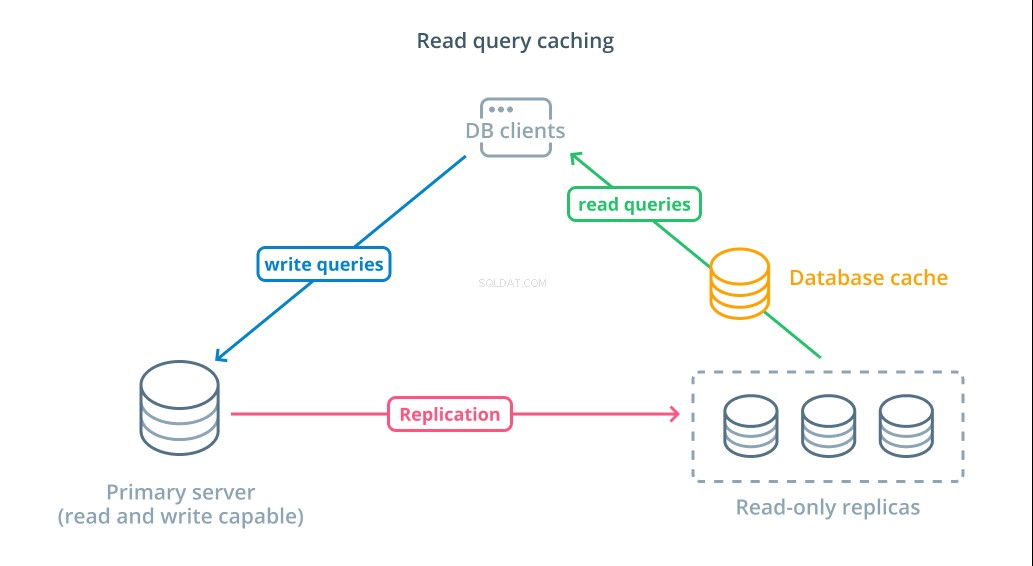
Aby skrócić czas odpowiedzi, buforowanie zapytań odczytu można wprowadzić warstwę. Dodanie pamięci podręcznej między klientami bazy danych a samymi bazami danych może znacznie skrócić czas wykonywania zapytań dla typowych żądań. Aplikacja może zażądać wyników odczytu z pamięci podręcznej i otrzymać je niemal natychmiast, jeśli są dostępne. W przypadku, gdy wyniki nie zostaną znalezione w pamięci podręcznej, są one pobierane z samej bazy danych i dodawane do pamięci podręcznej następnym razem.
Konfiguracja buforowania w ten sposób jest niezwykle wydajna w scenariuszach, w których dane prawdopodobnie nie zmienią się za każdym razem, gdy zostanie wysłane żądanie. Jest to szczególnie przydatne w przypadku kosztownych zapytań odczytu, które konsultują wiele tabel i zawierają złożone operacje łączenia. Wyniki te można wykonać raz, a następnie zapisać dla przyszłych zapytań.
W przypadkach, w których dane zmieniają się szybciej, pamięć podręczna odczytu może nie pomagać prawie tak bardzo. W zależności od skonfigurowanego zachowania, pamięci podręczne ryzykują zwracanie nieaktualnych danych w takich sytuacjach i należy wdrożyć przemyślane strategie unieważniania pamięci podręcznej, aby usunąć nieaktualne dane z pamięci podręcznej po zmianie.
Dzielenie danych
Do tej pory projekty, które omówiliśmy, zawierały segmentację komponentów bazy danych na podstawie tego, czy odpowiadają na żądania zapisu, czy nie. Jednak innym sposobem podziału odpowiedzialności jest podzielenie rzeczywistego zestawu danych na wiele części.
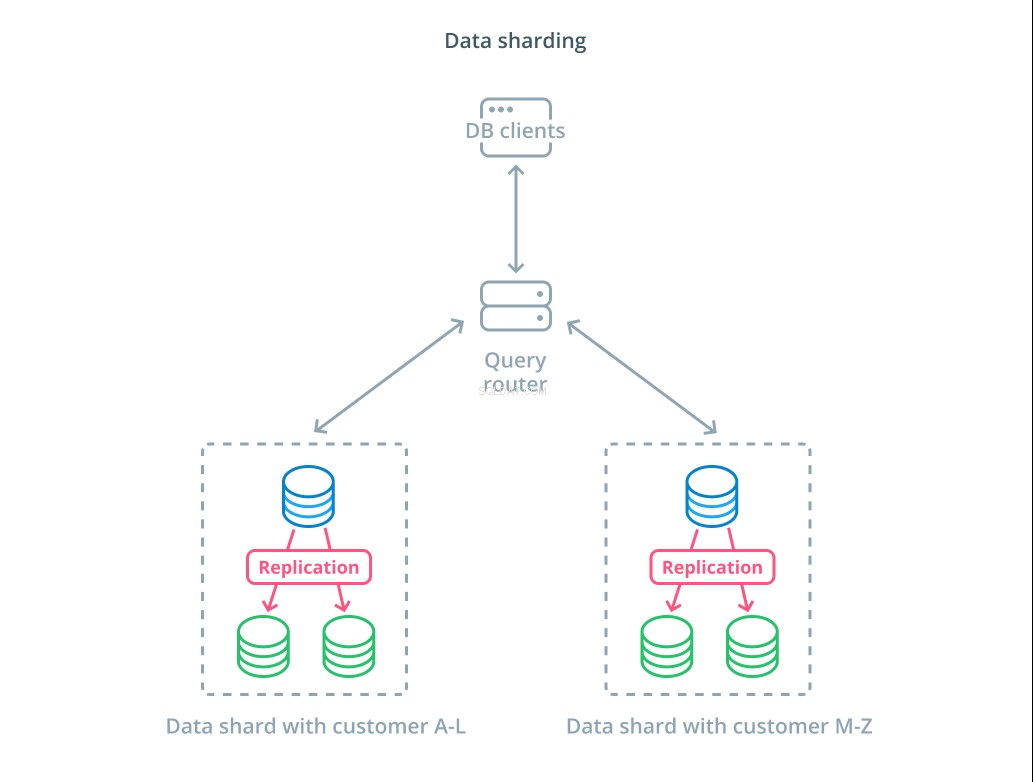
Sharding to proces dzielenia logicznego zestawu danych na mniejsze podzbiory w celu rozprowadzenia zarządzania nimi na różne komputery. Każdy serwer bazy danych obsługuje tylko część danych i wprowadza się mechanikę routingu, która rozumie, które maszyny są odpowiedzialne za które fragmenty danych.
Zazwyczaj fragmentowanie jest wykonywane w scenariuszach, w których jednoczesne działanie na całym zestawie danych jest niepotrzebne lub rzadkie. Zbiór danych jest podzielony na segmenty na podstawie wartości każdego rekordu dla określonego klucza, znanego jako klucz shardingowy . Na przykład możesz ręcznie dzielić dane na podstawie lokalizacji klientów. Możesz także automatycznie podzielić na fragmenty przy użyciu algorytmu mieszającego, aby określić, które węzły powinny obsługiwać które klucze. Może to pomóc Twojemu systemowi uniknąć niezrównoważonej dystrybucji w przypadkach, gdy przestrzeń kluczy fragmentu jest nierównomiernie rozłożona.
Sharding wprowadza sporo złożoności do systemów danych i nie jest odpowiedni dla wszystkich scenariuszy. Operacje, które wchodzą w interakcję z wieloma fragmentami, będą obciążone znacznymi spadkami wydajności, ponieważ pobierają wyniki od każdego członka. Może się to zdarzyć w przypadku zapytań agregujących lub jeśli określony klucz fragmentu nie jest znany z wyprzedzeniem. Ponadto nierówne przydzielanie fragmentów może również powodować nieefektywność i wąskie gardła, które należy naprawić, równoważąc dystrybucję całego zestawu danych.
Zdecentralizowane funkcjonalne zarządzanie danymi
Zamiast dzielić wartości zestawu danych na wiele segmentów, w wielu przypadkach bardziej sensowne jest używanie różnych baz danych do różnych celów funkcjonalnych. Na przykład, jeśli masz usługę kont i usługę produktów, posiadanie dedykowanych baz danych, które pokrywają się z każdym problemem, może pomóc w niezależnym skalowaniu różnych komponentów.
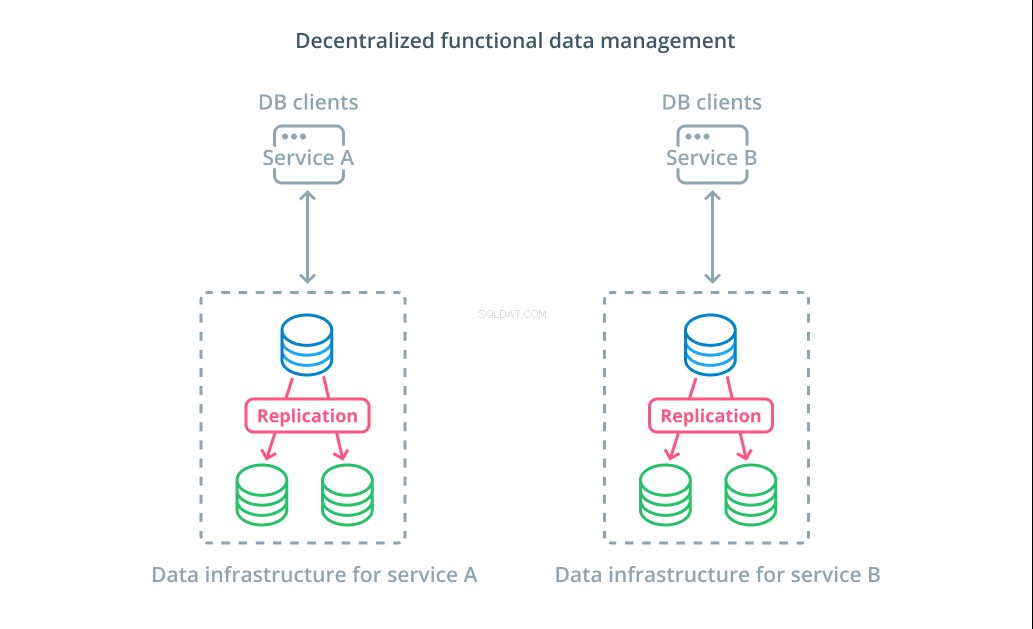
Funkcjonalne zarządzanie danymi pozwala na rozbicie infrastruktury bazy danych i zarządzanie każdą częścią zgodnie z potrzebami jej klientów. Każda część funkcjonalna może być skalowana przy użyciu dowolnej strategii, która ma największy sens. Pozwala zaprojektować schemat bazy danych i wdrożyć go w lokalizacji, która najlepiej pasuje do wzorców konkretnego przypadku użycia, zamiast wymagać, aby obsługiwał całą organizację.
Dla wielu organizacji strategia ta ma ważne zalety, które wykraczają poza właściwości rzeczywistych systemów. Decentralizacja zarządzania danymi może umożliwić mniejszym zespołom posiadanie własnych danych bez koordynowania zmian z innymi podmiotami. Dobrze pasuje do ukierunkowanej separacji problemów promowanych przez architektury aplikacji zorientowane na mikrousługi.
Bezserwerowe bazy danych
Różne kompromisy, które musisz ocenić, oraz ilość infrastruktury, której możesz oczekiwać, aby właściwie skalować, mogą być dla wielu osób przytłaczające. Jedną z opcji odciążenia tej złożoności jest skorzystanie z usług baz danych, które zarządzają infrastrukturą i skalują za Ciebie.
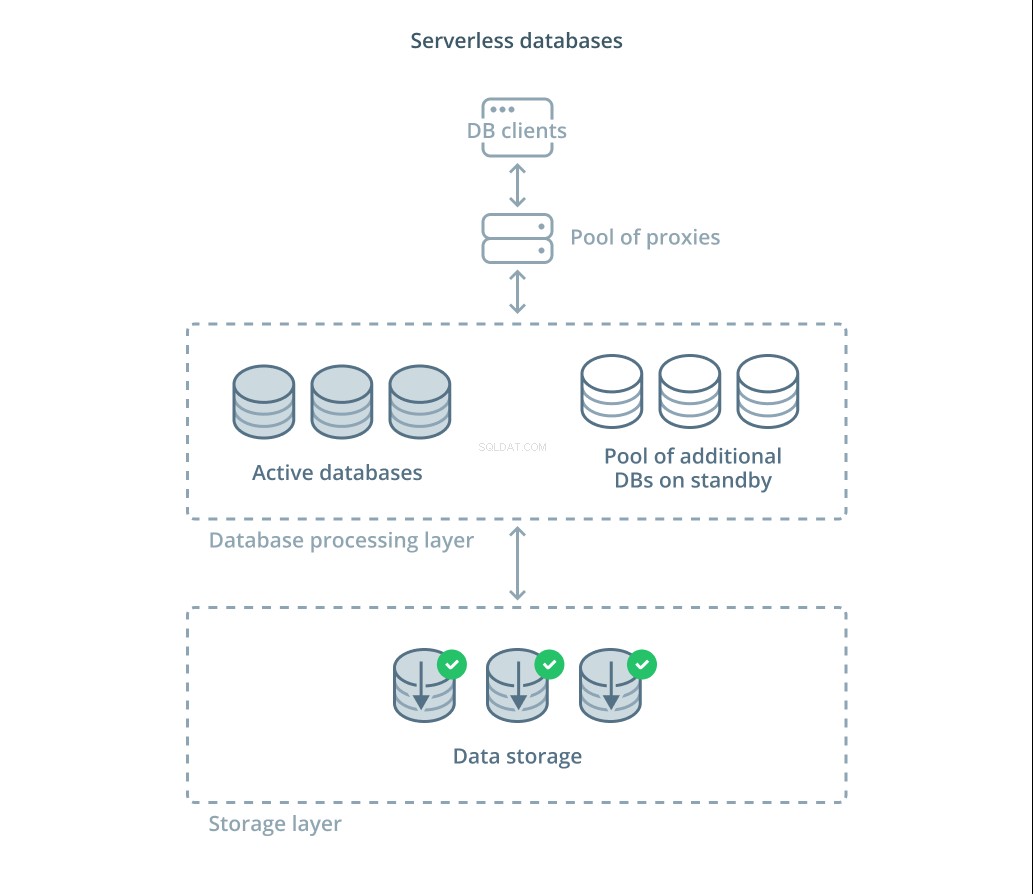
Bezserwerowe bazy danych to kategoria usług, które oddzielają przechowywanie danych od przetwarzania danych w celu łatwego skalowania zasobów w odpowiedzi na zmiany popytu.
Warstwa przechowywania danych odpowiada za utrzymanie rzeczywistych danych zarządzanych przez system. Przed tą warstwą wdrażana jest warstwa skalowalnych jednostek przetwarzania bazy danych, które obsługują rzeczywiste przetwarzanie zapytań w odniesieniu do zestawów danych. Liczba jednostek aktywnych w danym momencie jest bezpośrednio powiązana z bieżącym wykorzystaniem, więc więcej zasobów jest przydzielanych w szczytowych momentach zapotrzebowania, a jednostki przetwarzające wracają do trybu czuwania, jeśli sytuacja się uspokoi.
Zapytania są przekazywane do procesorów baz danych przez serwer proxy routingu, który wie, jak przekazywać żądania do aktywnych węzłów i kiedy żądać dodatkowych zasobów.
Bezserwerowe bazy danych mają wiele takich samych właściwości, jak tradycyjne usługi baz danych, które implementują funkcje autoskalowania. Oba mogą przydzielać pojemność na podstawie zapotrzebowania. Jednak bezserwerowe bazy danych umożliwiają oddzielenie kosztów przechowywania od kosztów przetwarzania i mogą skalować przetwarzanie do zera, gdy nie są potrzebne. Ponadto rozwiązania bezserwerowe są w stanie znacznie szybciej skalować się w celu zaspokojenia popytu w porównaniu z autoskalowaniem oferowanym przez tradycyjne oferty.
Chociaż bezserwerowe bazy danych mogą być dobrym rozwiązaniem dla niektórych, nie są one srebrną kulą. W przypadkach, w których procesory baz danych były skalowane do zera, mogą wystąpić opóźnienia w przetwarzaniu z powodu zimnych startów. Co więcej, zmienność połączeń między różnymi komponentami w stosie bezserwerowej bazy danych może prowadzić do dodatkowych opóźnień.
Bezserwerowe platformy baz danych mogą być również trudne z operacyjnego punktu widzenia. Wdrożenia i zmiany bazy danych mogą być trudniejsze do uzasadnienia i monitorowania. Lokalne środowisko programistyczne może również znacznie różnić się od środowiska produkcyjnego ze względu na dynamiczny stan systemu bazy danych. I wreszcie, podobnie jak w przypadku każdej innej usługi w chmurze, korzystanie z bezserwerowych baz danych może potencjalnie narazić Cię na ryzyko zablokowania dostawcy. Ważne jest, aby pamiętać o tych kompromisach podczas projektowania wokół platformy bezserwerowej.
Wniosek
Istnieje wiele sposobów projektowania i wdrażania infrastruktury bazy danych oraz zarządzania nią, gdy wymagania aplikacji stają się coraz poważniejsze. Każde rozwiązanie ma swoje mocne strony i ograniczenia, które należy zrozumieć, próbując znaleźć dopasowanie do swojego środowiska.
Poznanie wpływu infrastruktury bazy danych na dostępność, wydajność i integralność danych pozwala uniknąć kosztownych błędów i implementacji, które nie zapewniają wymaganych gwarancji. Jeśli jeden z powyższych projektów nie spełnia Twoich wymagań, możesz połączyć niektóre elementy różnych podejść, aby uzyskać dodatkowe korzyści.
Jeśli chcesz dowiedzieć się więcej o ogólnych wzorcach omówionych powyżej, oto kilka dodatkowych zasobów, które możesz chcieć sprawdzić:
- Skalowanie w górę a skalowanie w górę
- Segregacja odpowiedzialności za zapytania dotyczące poleceń
- Replikacja wielu podstawowych
- Buforowanie zapytań odczytu
- Podział danych
- Zdecentralizowane zarządzanie danymi
- Bezserwerowe bazy danych