Ten artykuł jest czwartą częścią serii dotyczącej wyrażeń tabelowych. W części 1 i 2 omówiłem koncepcyjne traktowanie tabel pochodnych. W części 3 zacząłem omawiać zagadnienia optymalizacji tabel pochodnych. W tym miesiącu omówię dalsze aspekty optymalizacji tabel pochodnych; w szczególności skupiam się na zastępowaniu/rozmieszczaniu tabel pochodnych.
W moich przykładach użyję przykładowych baz danych o nazwach TSQLV5 i PerformanceV5. Skrypt tworzący i wypełniający TSQLV5 można znaleźć tutaj, a jego diagram ER znajduje się tutaj. Skrypt, który tworzy i wypełnia PerformanceV5, znajdziesz tutaj.
Rozgnieżdżanie/podstawianie
Rozgnieżdżanie/podstawianie wyrażeń tabelowych to proces przyjmowania zapytania, który obejmuje zagnieżdżanie wyrażeń tabelowych i zastępowanie go zapytaniem, w którym zagnieżdżona logika jest eliminowana. Powinienem podkreślić, że w praktyce nie ma rzeczywistego procesu, w którym SQL Server konwertuje oryginalny ciąg zapytania z zagnieżdżoną logiką na nowy ciąg zapytania bez zagnieżdżania. W rzeczywistości proces parsowania zapytania tworzy początkowe drzewo operatorów logicznych ściśle odzwierciedlające oryginalne zapytanie. Następnie SQL Server stosuje przekształcenia do tego drzewa zapytań, eliminując niektóre niepotrzebne kroki, zwijając wiele kroków do mniejszej liczby kroków i przenosząc operatory. W swoich przekształceniach, o ile spełnione są określone warunki, SQL Server może przesuwać elementy poza granice wyrażeń tabelarycznych — czasami skutecznie, jakby eliminując jednostki zagnieżdżone. Wszystko to w celu znalezienia optymalnego planu.
W tym artykule omówię zarówno przypadki, w których takie rozgnieżdżanie ma miejsce, jak i inhibitory rozgnieżdżania. Oznacza to, że użycie pewnych elementów zapytania uniemożliwia SQL Serverowi przenoszenie operatorów logicznych w drzewie zapytań, zmuszając go do przetwarzania operatorów na podstawie granic wyrażeń tabeli użytych w pierwotnym zapytaniu.
Zacznę od zademonstrowania prostego przykładu, w którym tabele pochodne zostają rozgnieżdżone. Pokażę również przykład dla inhibitora rozgniatania. Następnie opowiem o nietypowych przypadkach, w których rozgnieżdżanie może być niepożądane, powodując błędy lub pogorszenie wydajności, i pokażę, jak zapobiegać rozgnieżdżaniu w takich przypadkach, stosując inhibitor rozgnieżdżania.
Następujące zapytanie (nazwiemy je Zapytanie 1) wykorzystuje wiele zagnieżdżonych warstw tabel pochodnych, w których każde z wyrażeń tabel stosuje podstawową logikę filtrowania opartą na stałych:
SELECT id zamówienia, datazamowieniaFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sprzedaż.Zamówienia WHERE datazam AS D3WHERE data zamówienia>='20180401';
Jak widać, każde z wyrażeń tabelowych filtruje zakres dat zamówień rozpoczynający się od innej daty. SQL Server rozpakowuje tę wielowarstwową logikę zapytań, co umożliwia mu następnie scalanie czterech predykatów filtrowania w jeden reprezentujący przecięcie wszystkich czterech predykatów.
Sprawdź plan dla Zapytania 1 pokazany na rysunku 1.
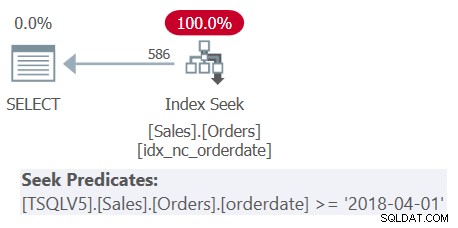 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Zauważ, że wszystkie cztery predykaty filtrujące zostały połączone w jeden predykat reprezentujący przecięcie tych czterech. Plan stosuje wyszukiwanie w indeksie idx_nc_orderdate w oparciu o pojedynczy scalony predykat jako predykat seek. Ten indeks jest zdefiniowany w orderdate (jawnie), orderid (niejawnie ze względu na obecność indeksu klastrowego w orderid) jako klucze indeksu.
Zauważ również, że chociaż wszystkie wyrażenia tabelowe używają SELECT * i tylko najbardziej zewnętrzne zapytanie rzutuje dwie interesujące kolumny:orderdate i orderid, wyżej wymieniony indeks jest uważany za obejmujący. Jak wyjaśniłem w części 3, dla celów optymalizacji, takich jak wybór indeksu, SQL Server ignoruje kolumny z wyrażeń tabelowych, które ostatecznie nie są istotne. Pamiętaj jednak, że musisz mieć uprawnienia do wysyłania zapytań do tych kolumn.
Jak wspomniano, SQL Server podejmie próbę rozgnieżdżenia wyrażeń tabelowych, ale uniknie rozgnieżdżania, jeśli natknie się na inhibitor rozgnieżdżania. Z pewnym wyjątkiem, który opiszę później, użycie TOP lub OFFSET FETCH zapobiegnie rozgnieżdżaniu. Powodem jest to, że próba rozpakowania wyrażenia tabelowego za pomocą funkcji TOP lub OFFSET FETCH może spowodować zmianę znaczenia oryginalnego zapytania.
Jako przykład rozważ następujące zapytanie (nazwiemy je Zapytanie 2):
SELECT identyfikator zamówienia, datazam ' ) AS D2 WHERE data zamówienia>='20180301' ) AS D3WHERE data zamówienia>='20180401';
Wprowadzona liczba wierszy do filtru TOP jest wartością typu BIGINT. W tym przykładzie używam maksymalnej wartości BIGINT (2^63 – 1, oblicz w T-SQL za pomocą SELECT POWER(2., 63) – 1). Mimo że Ty i ja wiemy, że nasza tabela Orders nigdy nie będzie miała tylu wierszy, a zatem filtr TOP jest naprawdę bez znaczenia, SQL Server musi brać pod uwagę teoretyczną możliwość, aby filtr miał sens. W związku z tym SQL Server nie rozpakowuje wyrażeń tabel w tym zapytaniu. Plan dla zapytania 2 pokazano na rysunku 2.
 Rysunek 2:Plan dla zapytania 2
Rysunek 2:Plan dla zapytania 2
Inhibitory rozmieszczania uniemożliwiały SQL Serverowi scalanie predykatów filtrujących, przez co kształt planu bardziej przypominał zapytanie koncepcyjne. Jednak warto zauważyć, że SQL Server nadal ignorował kolumny, które ostatecznie nie były istotne dla najbardziej zewnętrznego zapytania i dlatego był w stanie użyć indeksu pokrywającego w orderdate, orderid.
Aby zilustrować, dlaczego TOP i OFFSET-FETCH są inhibitorami rozmieszczania, weźmy prostą technikę optymalizacji predykatów pushdown. Przesuwanie predykatu oznacza, że optymalizator wypycha predykat filtru do wcześniejszego punktu w porównaniu z punktem początkowym, który pojawia się w logicznym przetwarzaniu zapytania. Załóżmy na przykład, że masz zapytanie z zarówno sprzężeniem wewnętrznym, jak i filtrem WHERE opartym na kolumnie z jednej ze stron sprzężenia. Jeśli chodzi o logiczne przetwarzanie zapytań, filtr WHERE powinien być oceniany po złączeniu. Często jednak optymalizator przesuwa predykat filtra do kroku przed sprzężeniem, ponieważ pozostawia to sprzężenie z mniejszą liczbą wierszy do pracy, co zwykle skutkuje bardziej optymalnym planem. Pamiętaj jednak, że takie przekształcenia są dozwolone tylko w przypadkach, gdy znaczenie oryginalnego zapytania jest zachowane, w tym sensie, że masz gwarancję uzyskania prawidłowego zestawu wyników.
Rozważmy następujący kod, który zawiera zapytanie zewnętrzne z filtrem WHERE względem tabeli pochodnej, która z kolei jest oparta na wyrażeniu tabeli z filtrem TOP:
SELECT identyfikator zamówienia, datazamowieniaFROM ( SELECT TOP (3) * FROM Sprzedaż.Zamówienia ) AS DWHERE datazamoTo zapytanie jest oczywiście niedeterministyczne ze względu na brak klauzuli ORDER BY w wyrażeniu tabelowym. Kiedy go uruchomiłem, SQL Server uzyskał dostęp do pierwszych trzech wierszy z datami zamówień wcześniejszymi niż 2018, więc otrzymałem pusty zestaw jako wynik:
identyfikator zamówienia data zamówienia----------- ---------- (0 wierszy dotyczy)Jak wspomniano, użycie TOP w wyrażeniu tabeli zapobiegło rozgnieżdżeniu/podstawieniu wyrażenia tabeli w tym miejscu. Gdyby SQL Server rozpakował wyrażenie tabeli, proces podstawienia dałby odpowiednik następującej kwerendy:
SELECT TOP (3) identyfikator zamówienia, data zamówieniaFROM Sales.OrdersWHERE data zamówienia>='20180101';To zapytanie jest również niedeterministyczne ze względu na brak klauzuli ORDER BY, ale oczywiście ma inne znaczenie niż oryginalne zapytanie. Jeśli tabela Sales.Orders zawiera co najmniej trzy zamówienia złożone w 2018 r. lub później — i tak jest — to zapytanie koniecznie zwróci trzy wiersze, w przeciwieństwie do oryginalnego zapytania. Oto wynik, który otrzymałem po uruchomieniu tego zapytania:
data zamówienia----------- ----------10400 2018-01-0110401 2018-01-0110402 2018-01-02 (dotyczy 3 wierszy)W przypadku, gdy niedeterministyczny charakter powyższych dwóch zapytań myli Cię, oto przykład z zapytaniem deterministycznym:
SELECT identyfikator zamówienia, datazamówieniaFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY id zamówienia ) AS DWHERE datazamoWyrażenie tabeli filtruje trzy zamówienia o najniższych identyfikatorach zamówień. Zewnętrzne zapytanie następnie filtruje z tych trzech zamówień tylko te, które zostały złożone 8 lipca 2017 r. lub później. Okazuje się, że jest tylko jedno kwalifikujące się zamówienie. To zapytanie generuje następujące dane wyjściowe:
data zamówienia----------- ----------10250 2017-07-08(1 wiersz dotyczy)Załóżmy, że SQL Server rozpakował wyrażenie tabeli w oryginalnym zapytaniu, a proces podstawienia dał w wyniku następujący odpowiednik zapytania:
SELECT TOP (3) identyfikator zamówienia, data zamówieniaFROM Sales.OrdersWHERE data zamówienia>='20170708'ORDER BY identyfikator zamówienia;Znaczenie tego zapytania jest inne niż oryginalnego zapytania. To zapytanie najpierw filtruje zamówienia złożone w dniu 8 lipca 2017 r. lub później, a następnie filtruje trzy pierwsze spośród tych o najniższych identyfikatorach zamówień. To zapytanie generuje następujące dane wyjściowe:
data zamówienia----------- ----------10250 2017-07-0810251 2017-07-0810252 2017-07-09(3 wiersze, których dotyczy)Aby uniknąć zmiany znaczenia oryginalnego zapytania, SQL Server nie stosuje tutaj rozmieszczania/podstawiania.
Ostatnie dwa przykłady obejmowały prostą mieszankę filtrowania WHERE i TOP, ale mogą istnieć dodatkowe sprzeczne elementy wynikające z rozgnieżdżania. Na przykład, co zrobić, jeśli masz różne specyfikacje porządkowania w wyrażeniu tabeli i zapytaniu zewnętrznym, jak w poniższym przykładzie:
SELECT idzamowienia, datazamowieniaFROM ( SELECT TOP (3) * FROM Sprzedaż.Zamówienia ORDER BY datazamZdajesz sobie sprawę, że gdyby SQL Server rozpakował wyrażenie tabeli, zwijając dwie różne specyfikacje porządkowania w jedną, wynikowe zapytanie miałoby inne znaczenie niż zapytanie oryginalne. Spowodowałoby to odfiltrowanie niewłaściwych wierszy lub przedstawienie wierszy wyników w niewłaściwej kolejności prezentacji. Krótko mówiąc, zdajesz sobie sprawę, dlaczego bezpieczną rzeczą dla SQL Server jest unikanie rozmieszczania/podstawiania wyrażeń tabelowych, które są oparte na zapytaniach TOP i OFFSET-FETCH.
Wspomniałem wcześniej, że istnieje wyjątek od reguły, że użycie TOP i OFFSET-FETCH zapobiega rozgnieżdżaniu. Dzieje się tak, gdy używasz TOP (100) PERCENT w zagnieżdżonym wyrażeniu tabelowym, z klauzulą ORDER BY lub bez niej. SQL Server zdaje sobie sprawę, że nie ma prawdziwego filtrowania i optymalizuje opcję. Oto przykład ilustrujący to:
SELECT id zamówienia, datazamowieniaFROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM Sprzedaż.Zamówienia WHERE datazamo ='20180201' ) AS D2 WHERE datazamowienia>='20180301' ) AS D3WHERE datazamowienia>='20180401';Filtr TOP jest ignorowany, następuje rozgnieżdżanie i otrzymujesz taki sam plan, jak ten pokazany wcześniej dla Zapytania 1 na Rysunku 1.
W przypadku używania OFFSET 0 ROWS bez klauzuli FETCH w zagnieżdżonym wyrażeniu tabelowym, nie ma również rzeczywistego filtrowania. Tak więc teoretycznie SQL Server mógł również zoptymalizować tę opcję i włączyć rozgnieżdżanie, ale w chwili pisania tego tekstu tak nie jest. Oto przykład ilustrujący to:
SELECT id zamówienia, datazamowieniaFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sprzedaż. Zamówienia WHERE datazamo (SELECT NULL) OFFSET 0 ROWS ) AS D2 WHERE datazamowienia>='20180301' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3WHERE datazamowienia>='20180401';Otrzymujesz taki sam plan, jak ten pokazany wcześniej dla Zapytania 2 na Rysunku 2, pokazując, że nie miało miejsca rozgnieżdżanie.
Wcześniej wyjaśniłem, że proces rozmieszczania/podstawiania tak naprawdę nie generuje nowego ciągu zapytania, który jest następnie optymalizowany, a raczej ma związek z przekształceniami, które SQL Server stosuje do drzewa operatorów logicznych. Istnieje różnica między sposobem, w jaki SQL Server optymalizuje zapytanie z zagnieżdżonymi wyrażeniami tabelowymi, a rzeczywistym logicznie równoważnym zapytaniem bez zagnieżdżania. Użycie wyrażeń tabelowych, takich jak tabele pochodne, a także podzapytań uniemożliwia prostą parametryzację. Przypomnij sobie zapytanie 1 pokazane wcześniej w artykule:
SELECT id zamówienia, datazamowieniaFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sprzedaż.Zamówienia WHERE datazam AS D3WHERE data zamówienia>='20180401';Ponieważ zapytanie korzysta z tabel pochodnych, prosta parametryzacja nie ma miejsca. Oznacza to, że SQL Server nie zastępuje stałych parametrami, a następnie optymalizuje zapytanie, a raczej optymalizuje zapytanie za pomocą stałych. Dzięki predykatom opartym na stałych SQL Server może scalać przecinające się okresy, co w naszym przypadku skutkowało pojedynczym predykatem w planie, jak pokazano wcześniej na rysunku 1.
Następnie rozważ następujące zapytanie (nazwiemy je Zapytanie 3), które jest logicznym odpowiednikiem Zapytania 1, ale w którym samodzielnie stosujesz rozgnieżdżanie:
SELECT identyfikator zamówienia, datazamówieniaFROM Sales.OrdersWHERE datazamoPlan dla tego zapytania pokazano na rysunku 3.
Rysunek 3:Plan dla zapytania 3
Plan ten jest uważany za bezpieczny dla prostej parametryzacji, więc stałe są zastępowane parametrami, a w konsekwencji predykaty nie są scalane. Motywacją do parametryzacji jest oczywiście zwiększenie prawdopodobieństwa ponownego wykorzystania planu podczas wykonywania podobnych zapytań, które różnią się tylko używanymi stałymi.
Jak wspomniano, użycie tabel pochodnych w zapytaniu 1 uniemożliwiło prostą parametryzację. Podobnie użycie podzapytań uniemożliwiłoby prostą parametryzację. Na przykład, oto nasze poprzednie Zapytanie 3 z bezsensownym predykatem opartym na podzapytaniu dodanym do klauzuli WHERE:
SELECT identyfikator zamówienia, datazamówieniaFROM Sales.OrdersWHERE datazamoTym razem prosta parametryzacja nie ma miejsca, umożliwiając SQL Serverowi łączenie przecinających się okresów reprezentowanych przez predykaty ze stałymi, co skutkuje tym samym planem, jak pokazano wcześniej na rysunku 1.
Jeśli masz zapytania z wyrażeniami tabelowymi, które używają stałych i ważne jest, aby program SQL Server sparametryzował kod, i z jakiegoś powodu nie możesz go sparametryzować samodzielnie, pamiętaj, że masz możliwość użycia wymuszonej parametryzacji za pomocą przewodnika dotyczącego planu. Jako przykład, poniższy kod tworzy taki przewodnik po planie dla zapytania 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX); EXEC sys.sp_get_query_template @querytext =N'SELECT identyfikatorzamowienia, datazamowieniaFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE datazamowienia>=''20180101'' ) AS D1 WHERE datazamowienia>=''20180201'' ) AS D2 WHERE datazamowienia>=''20180301'' ) AS D3WHERE datazamowienia>=''20180401'';', @templatetext =@stmt OUTPUT, @parameters =@params OUTPUT; EXEC sys.sp_create_plan_guide @name =N'TG1', @stmt =@stmt, @type =N'SZABLON', @module_or_batch =NULL, @params =@params, @wskazówki =N'OPCJA(PARAMETRYZACJA WYMUSZONA)';Uruchom ponownie zapytanie 3 po utworzeniu przewodnika po planie:
SELECT id zamówienia, datazamowieniaFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sprzedaż.Zamówienia WHERE datazam AS D3WHERE data zamówienia>='20180401';Otrzymujesz taki sam plan, jak ten pokazany wcześniej na Rysunku 3 ze sparametryzowanymi predykatami.
Kiedy skończysz, uruchom następujący kod, aby usunąć przewodnik po planie:
EXEC sys.sp_control_plan_guide @operation =N'DROP', @name =N'TG1';Zapobieganie rozgnieżdżaniu
Pamiętaj, że SQL Server rozpakowuje wyrażenia tabelowe w celu optymalizacji. Celem jest zwiększenie prawdopodobieństwa znalezienia planu o niższym koszcie w porównaniu z planem bez rozgnieżdżania. Dotyczy to większości reguł transformacji stosowanych przez optymalizator. Mogą jednak wystąpić pewne nietypowe przypadki, w których chciałbyś zapobiec rozgnieżdżaniu. Może to mieć na celu uniknięcie błędów (tak, w niektórych nietypowych przypadkach rozgnieżdżenie może skutkować błędami) lub ze względów wydajnościowych wymuszenie określonego kształtu planu, podobnie jak przy użyciu innych wskazówek dotyczących wydajności. Pamiętaj, że masz prosty sposób na powstrzymanie rozmieszczania za pomocą TOP z bardzo dużą liczbą.
Przykład unikania błędów
Zacznę od przypadku, w którym rozgnieżdżanie wyrażeń tabelowych może skutkować błędami.
Rozważ następujące zapytanie (nazwiemy je Zapytanie 4):
SELECT identyfikator zamówienia, identyfikator produktu, rabatFROM Sprzedaż.SzczegółyZamówieniaWHERE rabat> (SELECT MIN(rabat) FROM Sprzedaż.SzczegółyZamówienia) AND 1,0 / rabat> 10,0;Ten przykład jest nieco wymyślony w tym sensie, że łatwo jest przepisać drugi predykat filtra, aby nigdy nie spowodował błędu (rabat <0,1), ale jest to dla mnie wygodny przykład do zilustrowania mojego punktu widzenia. Rabaty nie są ujemne. Więc nawet jeśli istnieją wiersze zamówienia z zerowym rabatem, zapytanie ma je odfiltrować (pierwszy predykat filtra mówi, że rabat musi być większy niż minimalny rabat w tabeli). Nie ma jednak pewności, że SQL Server oceni predykaty w kolejności pisemnej, więc nie można liczyć na zwarcie.
Sprawdź plan dla zapytania 4 pokazany na rysunku 4.
Rysunek 4:Plan dla zapytania 4
Zauważ, że w planie predykat 1.0 / rabat> 10.0 (drugi w klauzuli WHERE) jest oceniany przed rabatem predykatu>
(pierwszy w klauzuli WHERE). W rezultacie to zapytanie generuje błąd dzielenia przez zero: Msg 8134, Poziom 16, Stan 1 Wystąpił błąd dzielenia przez zero.Być może myślisz, że możesz uniknąć błędu, używając tabeli pochodnej, rozdzielając zadania filtrowania na wewnętrzne i zewnętrzne, na przykład:
SELECT identyfikator zamówienia, identyfikator produktu, rabatFROM ( SELECT * FROM Sprzedaż.SzczegółyZamówienia WHERE rabat> (SELECT MIN(rabat) FROM Sprzedaż.SzczegółyZamówienia) ) AS DWHERE 1.0 / rabat> 10.0;Jednak SQL Server stosuje rozgnieżdżanie tabeli pochodnej, co skutkuje tym samym planem przedstawionym wcześniej na rysunku 4, a w konsekwencji ten kod również kończy się niepowodzeniem z błędem dzielenia przez zero:
Msg 8134, Poziom 16, Stan 1 Wystąpił błąd dzielenia przez zero.Prostą poprawką jest tutaj wprowadzenie inhibitora rozmieszczania, tak jak to (nazwiemy to rozwiązanie Zapytanie 5):
SELECT identyfikator zamówienia, identyfikator produktu, rabatFROM ( SELECT TOP (9223372036854775807) * FROM Sprzedaż. Szczegóły zamówienia WHERE rabat> (SELECT MIN (rabat) FROM Sprzedaż. Szczegóły zamówienia) ) AS DWHERE 1.0 / rabat> 10.0;Plan dla zapytania 5 pokazano na rysunku 5.
Rysunek 5:Plan dla zapytania 5
Nie dajcie się zmylić tym, że wyrażenie 1.0 / rabat pojawia się w wewnętrznej części operatora zagnieżdżonych pętli, jakby było oceniane jako pierwsze. To tylko definicja elementu Expr1006. Rzeczywista ocena predykatu Wyr1006> 10,0 jest stosowana przez operator filtru jako ostatni krok w planie po wcześniejszym odfiltrowaniu wierszy z minimalnym rabatem przez operatora zagnieżdżonych pętli. To rozwiązanie działa pomyślnie bez błędów.
Przykład ze względu na wydajność
Będę kontynuował przypadek, w którym rozgnieżdżanie wyrażeń tabel może obniżyć wydajność.
Zacznij od uruchomienia następującego kodu, aby przełączyć kontekst do bazy danych PerformanceV5 i włączyć STATISTICS IO i TIME:
UŻYJ PerformanceV5; USTAW STATYSTYKI IO, CZAS WŁĄCZONY;Rozważ następujące zapytanie (nazwiemy je Zapytanie 6):
SELECT identyfikator wysyłki, MAX(data zamówienia) AS maxodFROM dbo.OrdersGROUP BY identyfikator wysyłki;Optymalizator identyfikuje pomocniczy indeks pokrycia z identyfikatorem dostawcy i datą zamówienia jako kluczami wiodącymi. Tworzy więc plan z uporządkowanym skanowaniem indeksu, po którym następuje oparty na kolejności operator Stream Aggregate, jak pokazano w planie dla zapytania 6 na rysunku 6.
Rysunek 6:Plan dla zapytania 6
Tabela Zamówienia zawiera 1 000 000 wierszy, a kolumna grupująca nadawcy jest bardzo gęsta — istnieje tylko 5 odrębnych identyfikatorów nadawcy, co daje gęstość 20% (średni procent na odrębną wartość). Zastosowanie pełnego skanowania liścia indeksu wiąże się z odczytaniem kilku tysięcy stron, co w moim systemie daje czas działania około jednej trzeciej sekundy. Oto statystyki wydajności, które uzyskałem za wykonanie tego zapytania:
Czas procesora =344 ms, upływ czasu =346 ms, odczyty logiczne =3854Drzewo indeksów ma obecnie trzy poziomy głębokości.
Przeskalujmy liczbę zamówień przez współczynnik od 1000 do 1 000 000 000, ale nadal z tylko 5 różnymi dostawcami. Liczba stron w liściu indeksu wzrosłaby 1000 razy, a drzewo indeksu prawdopodobnie dałoby jeden dodatkowy poziom (głębokość czterech poziomów). Ten plan ma skalowanie liniowe. Otrzymasz prawie 4 000 000 odczytów logicznych i czas działania wynoszący kilka minut.
Kiedy trzeba obliczyć agregację MIN lub MAX względem dużej tabeli, z bardzo dużą gęstością w kolumnie grupującej (ważne!) i wspierającym indeksem B-drzewa z kluczem w kolumnie grupującej i kolumnie agregacji, istnieje znacznie bardziej optymalny kształt planu niż ten na Rysunku 6. Wyobraź sobie kształt planu, który skanuje mały zestaw identyfikatorów nadawcy z pewnego indeksu w tabeli Nadawcy i w pętli stosuje się do każdego nadawcy wyszukiwanie względem pomocniczego indeksu w Zamówieniach w celu uzyskania całości. Przy 1 000 000 wierszy w tabeli 5 wyszukiwań wymagałoby 15 odczytów. Przy 1 000 000 000 wierszy 5 wyszukiwań wymagałoby 20 odczytów. Z bilionem wierszy, łącznie 25 odczytów. Oczywiście o wiele bardziej optymalny plan. W rzeczywistości możesz osiągnąć taki plan, wysyłając zapytanie do tabeli Shippers i uzyskując agregację za pomocą podzapytania agregacji skalarnej dla zamówień, tak jak w ten sposób (nazwiemy to rozwiązanie Zapytanie 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxodFROM dbo.Shippers AS S;Plan dla tego zapytania pokazano na rysunku 7.
Rysunek 7:Plan dla zapytania 7
Pożądany kształt planu został osiągnięty, a dane dotyczące wydajności wykonania tego zapytania są nieistotne zgodnie z oczekiwaniami:
Czas procesora =0 ms, upływ czasu =0 ms, odczyty logiczne =15Dopóki kolumna grupująca jest bardzo gęsta, rozmiar tabeli Zamówienia staje się praktycznie nieistotny.
Ale poczekaj chwilę, zanim zaczniesz świętować. Istnieje wymóg, aby zachować tylko tych nadawców, których maksymalna data zamówienia w tabeli Zamówienia przypada na rok 2018 lub później. Brzmi jak dość prosty dodatek. Zdefiniuj tabelę pochodną opartą na zapytaniu 7 i zastosuj filtr w zapytaniu zewnętrznym, tak jak to (nazwiemy to rozwiązanie zapytaniem 8):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>=„20180101”;Niestety, SQL Server rozpakowuje zapytanie dotyczące tabeli pochodnej, a także podzapytanie, konwertując logikę agregacji na równoważną logikę zapytania zgrupowanego, z kolumną grupującą shipperid. A sposób, w jaki SQL Server wie, jak zoptymalizować zapytanie grupowe, opiera się na pojedynczym przejściu przez dane wejściowe, co skutkuje planem bardzo podobnym do tego pokazanego na rysunku 6, tylko z dodatkowym filtrem. Plan dla zapytania 8 pokazano na rysunku 8.
Rysunek 8:Plan dla zapytania 8
W rezultacie skalowanie jest liniowe, a wskaźniki wydajności są podobne do tych z Zapytania 6:
Czas procesora =328 ms, upływ czasu =325 ms, odczyty logiczne =3854Poprawka polega na wprowadzeniu inhibitora rozmieszczania. Można to zrobić, dodając filtr TOP do wyrażenia tabeli, na którym oparta jest tabela pochodna, w ten sposób (nazwiemy to rozwiązanie Zapytanie 9):
SELECT shipperid, maxodFROM ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Plan dla tego zapytania jest pokazany na rysunku 9 i ma żądany kształt planu z zapytaniami:
Rysunek 9:Plan dla zapytania 9
Liczby wydajności dla tego wykonania są wtedy oczywiście pomijalne:
Czas procesora =0 ms, upływ czasu =0 ms, odczyty logiczne =15Jeszcze inną opcją jest zapobieganie rozgnieżdżaniu podzapytania poprzez zastąpienie agregatu MAX równoważnym filtrem TOP (1), tak jak w ten sposób (nazwiemy to rozwiązanie Zapytanie 10):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Plan dla tego zapytania jest pokazany na rysunku 10 i ponownie ma pożądany kształt z wyszukiwaniami.
Rysunek 10:Plan dla zapytania 10
Otrzymałem znane, nieistotne dane dotyczące wydajności dla tego wykonania:
Czas procesora =0 ms, upływ czasu =0 ms, odczyty logiczne =15Gdy skończysz, uruchom następujący kod, aby zatrzymać raportowanie statystyk wydajności:
USTAW STATYSTYKI IO, CZAS WYŁĄCZONY;Podsumowanie
W tym artykule kontynuowałem dyskusję, którą rozpocząłem w zeszłym miesiącu na temat optymalizacji tabel pochodnych. W tym miesiącu skupiłem się na rozgnieżdżaniu tabel pochodnych. Wyjaśniłem, że zazwyczaj rozgnieżdżanie skutkuje bardziej optymalnym planem w porównaniu do bez rozmieszczania, ale omówiłem również przykłady, w których jest to niepożądane. Pokazałem przykład, w którym rozgnieżdżenie skutkowało błędem, a także przykład skutkujący pogorszeniem wydajności. Pokazałem, jak zapobiegać rozgnieżdżaniu, stosując inhibitor rozgnieżdżania, taki jak TOP.
W przyszłym miesiącu będę kontynuować eksplorację nazwanych wyrażeń tabelowych, przenosząc nacisk na CTE.