Porównanie danych z dwóch różnych źródeł danych to coś, co normalnie wymagałoby wielu różnych ruchomych części, szczególnie jeśli jesteś zainteresowany tworzeniem wizualizacji na tych nowych danych.
W trybie SQL Chartio, tak jak w większości edytorów SQL, możesz napisać ten typ złączenia i połączyć te dwie tabele, JEŚLI znajdują się one w tym samym źródle danych. Za pomocą edytora schematów można dyktować sposób łączenia dwóch takich tabel w trybie interaktywnym, czyli JEŚLI znajdują się one w tym samym źródle danych. Nie możesz tego zrobić z dwoma różnymi i oddzielnymi źródłami danych. W tym miejscu pojawia się warstwowanie Chartio.
Jak SQL może utworzyć połączenie
W składni SQL łączenie dwóch tabel odbywa się w klauzuli FROM, a polecenie to po prostu JOIN. Syntaktycznie wygląda to mniej więcej tak:
_SELECT p.id, p.name, p.city, p.state, s.score_
_FROM public.person_info as p_
_INNER JOIN public.score_info as s ON p.id = s.id_
- To, co tutaj zrobiliśmy, to te dwie tabele:
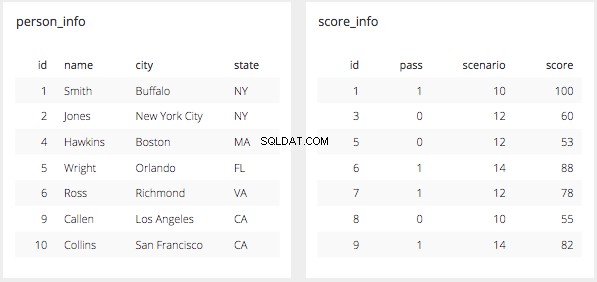
- I dosłownie połączył je ze sobą, tworząc jedną tabelę z wynikami przecięcia tych dwóch tabel w kolumnie „id”.
- Połączenie można wyjaśnić za pomocą tej animacji

- Tabela wynikowa jest kombinacją tych dwóch i wygląda tak:
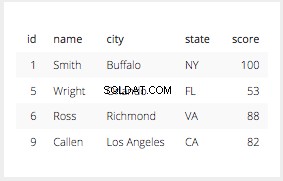
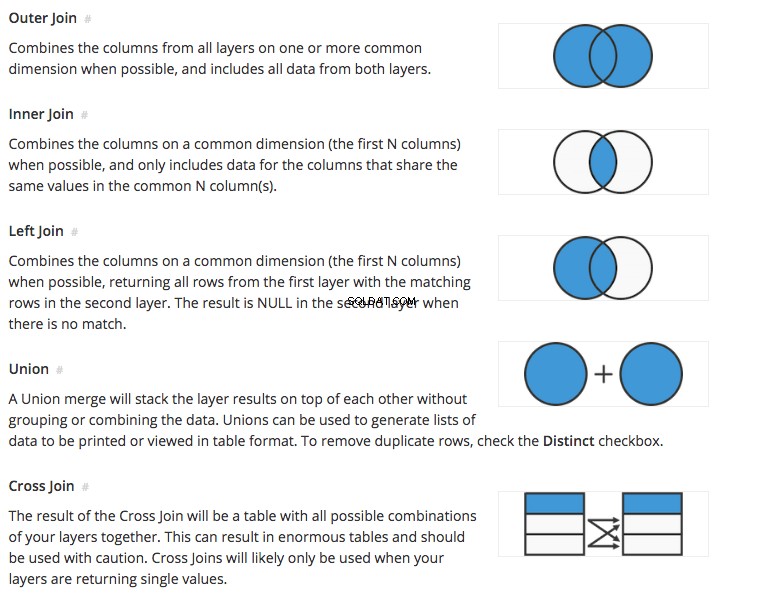
Jak widać z animacji, a wynikowa tabela powyżej elementów zwracanych przez INNER JOIN pokazuje TYLKO wiersze, w których ID znajduje się w obu tabelach z określonymi kolumnami wymienionymi w klauzuli SELECT. To jest sedno JOINS w SQL:przynieś mi dane z wielu tabel, w których przecinają się kolumny występujące w obu tabelach. Jest to najbardziej podstawowa forma JOIN the INNER JOIN. Istnieją różne sposoby łączenia tych tabel lub różne typy łączenia, które można wyjaśnić za pomocą diagramów Venna, takich jak te, które pokazano poniżej.
Jak warstwy Chartio tworzą połączenia
W trybie interaktywnym Chartio możesz połączyć dwa źródła razem z warstwami. Podstawy są tutaj dość proste, wystarczy wykonać kilka kroków, aby skonfigurować podstawowe zapytania w celu ustalenia dwóch tabel, które mają zostać połączone. Sposób łączenia warstw jest podobny do tego, w jaki sposób program Excel może używać funkcji WYSZUKAJ.PIONOWO. Wybierając krok potoku danych scalania warstw (w trybie interaktywnym odbywa się to poprzez dodanie nowej warstwy przez kliknięcie znaku plusa „+” pod eksploratorem danych) informujesz Chartio, aby wziął tabele, które są wynikiem początkowych zapytań w określoną składnię określonych źródeł danych i połącz je w przecinających się wierszach w wybranych kolumnach.
Różnica polega na tym, że w trybie interaktywnym w Chartio dyktujesz, że te kolumny mają się połączyć w pierwszych 1, 2, 3 itd. kolumnach po lewej stronie obu tabel, podobnie jak w programie Excel VLOOKUP. W przeciwieństwie do łączenia w trybie SQL, w którym możesz dyktować kolumnę we wpisanej składni.
W Chartio opcja warstw może łączyć dwa różne źródła danych, z dwóch różnych połączeń Amazon Redshift lub połączeń PostgreSQL, a nawet łączyć i porównywać Google Analytics ze źródłem Amazon Redshift lub innym typem źródła danych. W tym przykładzie porównamy źródło Amazon Redshift w Chartio ze źródłem Google Analytics, którego używamy do monitorowania sesji odsłon. Porównajmy więc sesje z leadami z tabeli leadów Salesforce.
- Krok 1:Utwórz zapytanie dla źródła Amazon Redshift.
- REDSHIFT — warstwa Salesforce
- Tabela – prowadzący SF
- Kolumny
- Liczba odrębnych identyfikatorów
- Dzień utworzeniadata
- Data utworzenia w ciągu ostatnich N tygodni 1
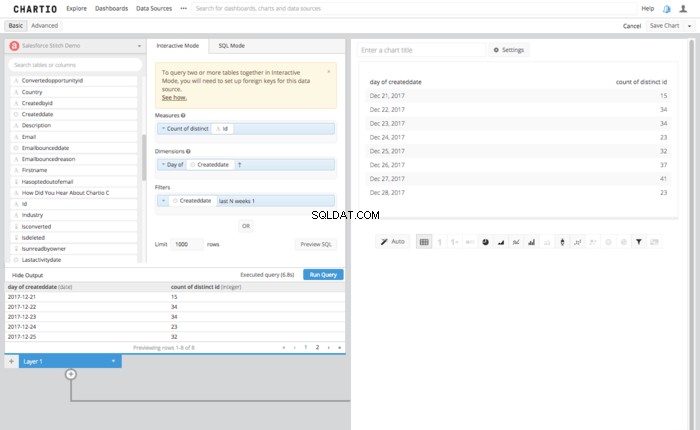
- REDSHIFT — warstwa Salesforce
-
Krok 2:Skonfiguruj etap łączenia, dodając nową warstwę.
- Krok 3:Utwórz zapytanie dla źródła Google Analytics.
- GOOGLE ANALYTICS — Chartio Web Analytics
- Tabela - Sesja
- Kolumny
- # sesje
- Dzień wizyty
- Czas ostatnich N tygodni 1
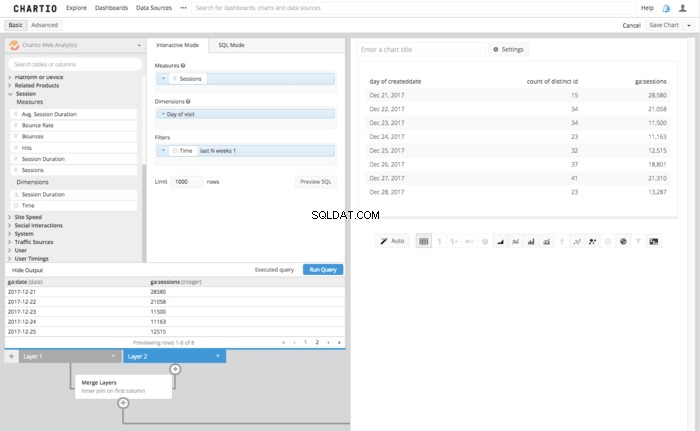
- GOOGLE ANALYTICS — Chartio Web Analytics
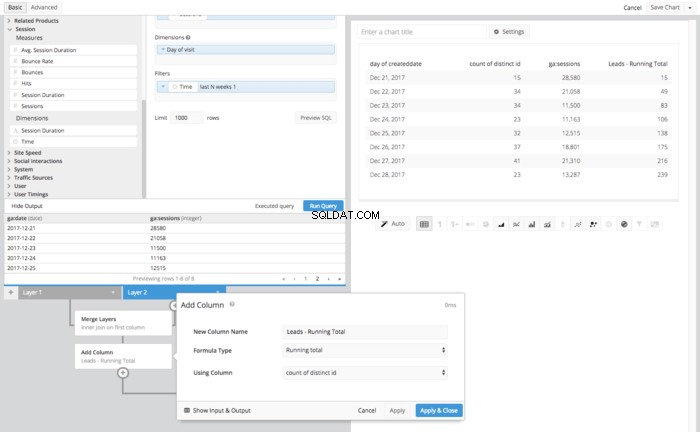
- Krok 4:Użyj kroków potoku danych, aby manipulować wynikową tabelą połączoną
- Dodaj kolumnę
- Nowy typ kolumny
- Potencjalni klienci — suma bieżąca
- Typ formuły
- Suma bieżąca
- Korzystanie z kolumny
- Liczba odrębnych identyfikatorów
- Nowy typ kolumny
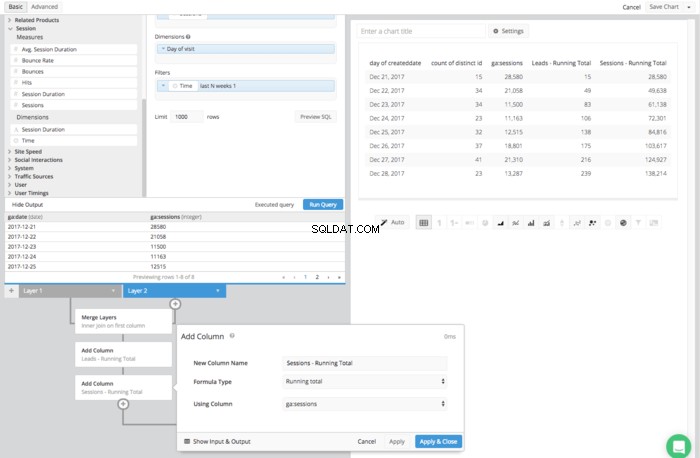
- Dodaj kolumnę
- Nowy typ kolumny
- Sesje — suma bieżąca
- Typ formuły
- Suma bieżąca
- Korzystanie z kolumny
- Ga:sesje
- Nowy typ kolumny
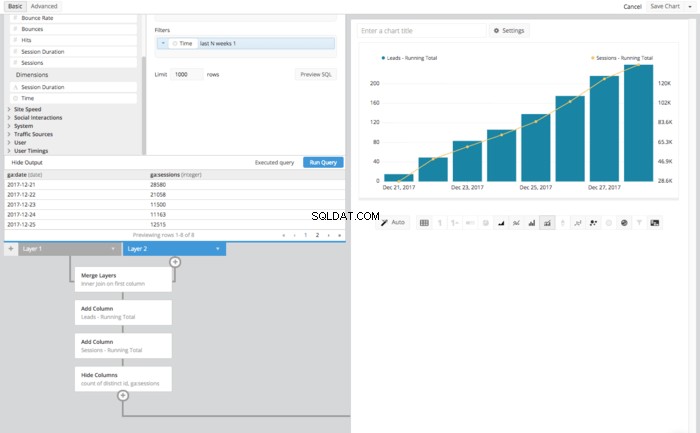
- Ukryj kolumny
- Liczba odrębnych identyfikatorów
- Ga:sesje
- Dodaj kolumnę