Do czego służy indeksowanie?
Indeksowanie to sposób na uporządkowanie tabeli nieuporządkowanej, która zmaksymalizuje wydajność zapytania podczas wyszukiwania.
Gdy tabela nie jest indeksowana, kolejność wierszy prawdopodobnie nie będzie rozpoznawalna przez zapytanie jako zoptymalizowane w jakikolwiek sposób, a zatem zapytanie będzie musiało przeszukiwać wiersze liniowo. Innymi słowy, zapytania będą musiały przeszukać każdy wiersz, aby znaleźć wiersze spełniające warunki. Jak możesz sobie wyobrazić, może to zająć dużo czasu. Przeglądanie każdego wiersza nie jest zbyt wydajne.
Na przykład poniższa tabela przedstawia tabelę w fikcyjnym źródle danych, które jest całkowicie nieuporządkowane.
| identyfikator_firmy | jednostka | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1,05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1,05 |
Gdybyśmy mieli uruchomić następujące zapytanie:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
Baza danych musiałaby przeszukiwać wszystkie 17 wierszy w kolejności, w jakiej pojawiają się w tabeli, od góry do dołu, po jednym na raz. Aby wyszukać wszystkie potencjalne wystąpienia company_id numer 18, baza danych musi przeszukać całą tabelę pod kątem wszystkich wystąpień 18 w company_id kolumna.
Stanie się to coraz bardziej czasochłonne wraz ze wzrostem rozmiaru stołu. Wraz ze wzrostem złożoności danych może się zdarzyć, że tabela z miliardem wierszy zostanie połączona z inną tabelą z miliardem wierszy; zapytanie musi teraz przeszukać dwa razy więcej wierszy kosztujących dwa razy więcej czasu.
Możesz zobaczyć, jak staje się to problematyczne w naszym stale nasyconym danymi świecie. Tabele powiększają się, a czas wyszukiwania wydłuża się.
Zapytanie o niezindeksowaną tabelę, jeśli jest przedstawione wizualnie, wyglądałoby tak:
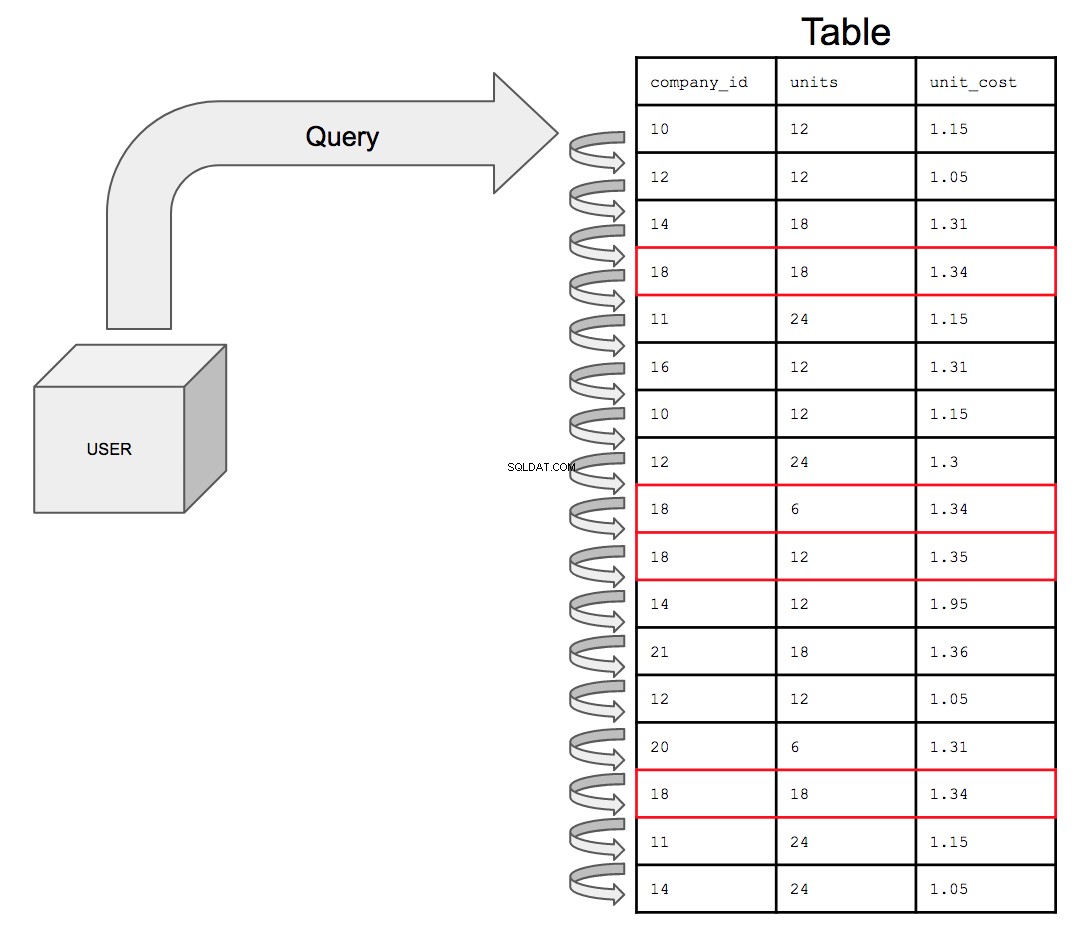
To, co robi indeksowanie, to ustawia kolumnę, w której znajdują się warunki wyszukiwania, w posortowanej kolejności, aby pomóc w optymalizacji wydajności zapytań.
Z indeksem w company_id kolumna, tabela zasadniczo „wyglądałaby” tak:
| identyfikator_firmy | jednostka | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1,05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1,05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1,36 |
Teraz baza danych może wyszukać company_id numer 18 i zwróć wszystkie żądane kolumny dla tego wiersza, a następnie przejdź do następnego wiersza. Jeśli comapny_id w następnym wierszu liczba to również 18, to zwróci wszystkie kolumny wymagane w zapytaniu. Jeśli company_id w następnym wierszu wynosi 20, zapytanie wie, że należy zatrzymać wyszukiwanie, a zapytanie się zakończy.
Jak działa indeksowanie?
W rzeczywistości tabela bazy danych nie zmienia swojej kolejności za każdym razem, gdy zmieniają się warunki zapytania, aby zoptymalizować wydajność zapytania:byłoby to nierealne. W rzeczywistości indeks powoduje, że baza danych tworzy strukturę danych. Typ struktury danych to najprawdopodobniej B-Tree. Chociaż zalety B-Tree są liczne, główną zaletą dla naszych celów jest to, że można je sortować. Kiedy struktura danych jest posortowana w kolejności, nasze wyszukiwanie jest bardziej wydajne z oczywistych powodów, które wskazaliśmy powyżej.
Gdy indeks tworzy strukturę danych w określonej kolumnie, należy pamiętać, że żadna inna kolumna nie jest przechowywana w strukturze danych. Nasza struktura danych dla powyższej tabeli będzie zawierać tylko company_id liczby. Jednostki i unit_cost nie będą przechowywane w strukturze danych.
Skąd baza danych wie, jakie inne pola w tabeli mają zostać zwrócone?
Indeksy bazy danych będą również przechowywać wskaźniki, które są po prostu informacjami referencyjnymi dotyczącymi lokalizacji dodatkowych informacji w pamięci. Zasadniczo indeks zawiera company_id i adres domowy tego konkretnego wiersza na dysku pamięci. Indeks będzie wyglądał tak:
| identyfikator_firmy | wskaźnik |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
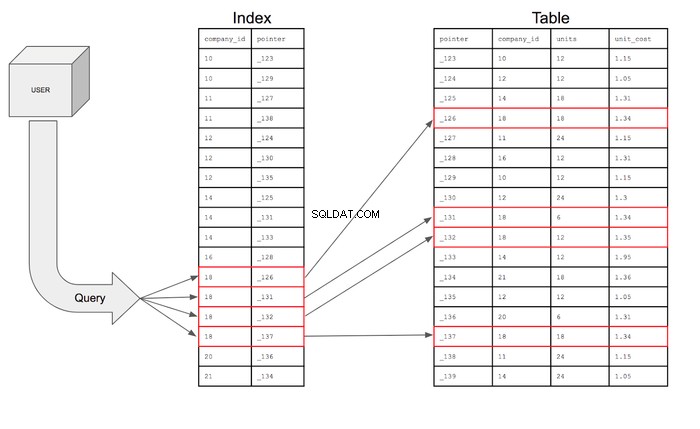
Za pomocą tego indeksu zapytanie może wyszukiwać tylko wiersze w company_id kolumna, która ma 18, a następnie za pomocą wskaźnika może przejść do tabeli, aby znaleźć konkretny wiersz, w którym znajduje się ten wskaźnik. Zapytanie może następnie przejść do tabeli, aby pobrać pola dla żądanych kolumn dla wierszy, które spełniają warunki.
Gdyby wyszukiwanie zostało przedstawione wizualnie, wyglądałoby to tak:
Podsumowanie
- Indeksowanie dodaje strukturę danych z kolumnami dla warunków wyszukiwania i wskaźnikiem
- Wskaźnik to adres na dysku pamięci wiersza z resztą informacji
- Struktura danych indeksu jest sortowana w celu optymalizacji wydajności zapytań
- Zapytanie szuka określonego wiersza w indeksie; indeks odnosi się do wskaźnika, który znajdzie resztę informacji.
- Indeks zmniejsza liczbę wierszy, które zapytanie musi przeszukać, z 17 do 4.