Dyskusja na temat różnicy preferencji między FOREACH i FOR nie jest nowa. Wszyscy wiemy, że FOREACH jest wolniejsze, ale nie wszyscy wiemy dlaczego.
Kiedy zacząłem uczyć się .NET, jedna osoba powiedziała mi, że FOREACH jest dwa razy wolniejsze niż FOR. Powiedział to bez żadnych podstaw. Wziąłem to za pewnik.
W końcu postanowiłem zbadać różnice w wydajności pętli FOREACH i FOR i napisać ten artykuł, aby omówić niuanse.
Rzućmy okiem na następujący kod:
foreach (var item in Enumerable.Range(0, 128))
{
Console.WriteLine(item);
}FOREACH jest cukrem składni. W tym konkretnym przypadku kompilator przekształca go w następujący kod:
IEnumerator<int> enumerator = Enumerable.Range(0, 128).GetEnumerator();
try
{
while (enumerator.MoveNext())
{
int item = enumerator.Current;
Console.WriteLine(item);
}
}
finally
{
if (enumerator != null)
{
enumerator.Dispose();
}
}Wiedząc o tym, możemy założyć, że FOREACH jest wolniejsze niż FOR:
- Tworzenie nowego obiektu. Nazywa się Stwórcą.
- Metoda MoveNext jest wywoływana w każdej iteracji.
- Każda iteracja uzyskuje dostęp do właściwości Current.
Otóż to! Jednak nie jest to takie proste, jak się wydaje.
Na szczęście (lub niestety) C#/CLR może wykonywać optymalizacje w czasie wykonywania. Zaletą jest to, że kod działa szybciej. Wada – programiści powinni być świadomi tych optymalizacji.
Tablica jest typem głęboko zintegrowanym z CLR, a CLR zapewnia szereg optymalizacji dla tego typu. Pętla FOREACH to iterowalna jednostka, która jest kluczowym aspektem wykonania. W dalszej części artykułu omówimy, jak iterować przez tablice i listy za pomocą metody statycznej Array.ForEach i metody List.ForEach.
Metody testowe
static double ArrayForWithoutOptimization(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < array.Length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForWithOptimization(int[] array)
{
int length = array.Length;
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForeach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
foreach (var item in array)
sum += item;
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForEach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
Array.ForEach(array, i => { sum += i; });
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}Warunki testowe:
- Opcja „Optymalizuj kod” jest włączona.
- Liczba elementów jest równa 100 000 000 (zarówno w tablicy, jak i na liście).
- Specyfikacja komputera:Intel Core i-5 i 8 GB pamięci RAM.
Tablice
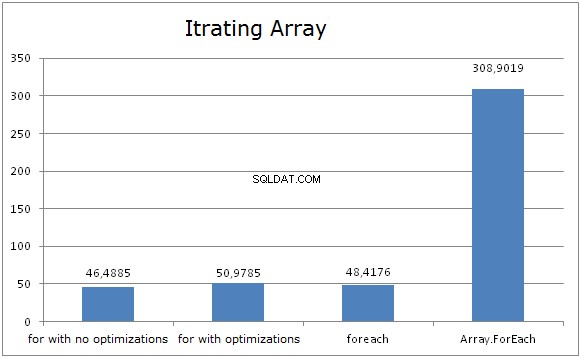
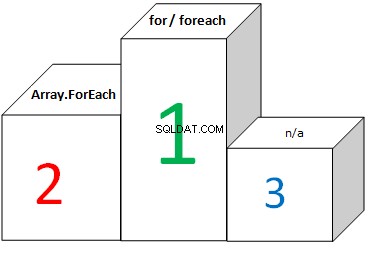
Diagram pokazuje, że FOR i FOREACH spędzają tyle samo czasu podczas iteracji przez tablice. A to dlatego, że optymalizacja CLR konwertuje FOREACH na FOR i używa długości tablicy jako maksymalnej granicy iteracji. Nie ma znaczenia, czy długość tablicy jest buforowana, czy nie (przy użyciu FOR), wynik jest prawie taki sam.
Może to zabrzmieć dziwnie, ale buforowanie długości tablicy może wpłynąć na wydajność. Podczas korzystania z tablicy .Długość jako granica iteracji, JIT testuje indeks, aby trafić w prawą granicę poza cyklem. Ta kontrola jest wykonywana tylko raz.
Bardzo łatwo jest zniszczyć tę optymalizację. Przypadek, w którym zmienna jest buforowana, nie jest zoptymalizowany.
Array.foreach wykazali najgorsze wyniki. Jego implementacja jest dość prosta:
public static void ForEach<T>(T[] array, Action<T> action)
{
for (int index = 0; index < array.Length; ++index)
action(array[index]);
}Dlaczego więc działa tak wolno? Używa FOR pod maską. Cóż, powodem jest wywołanie delegata ACTION. W rzeczywistości w każdej iteracji wywoływana jest metoda, co zmniejsza wydajność. Co więcej, delegaci są przywoływani nie tak szybko, jak byśmy chcieli.
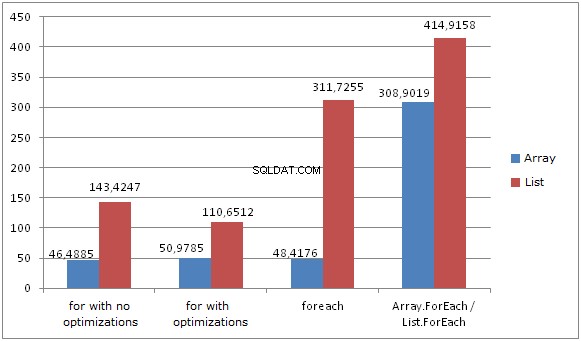
Listy

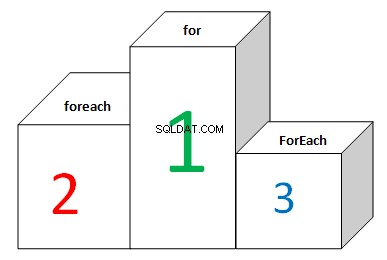
Wynik jest zupełnie inny. Podczas iteracji list, FOR i FOREACH pokazują różne wyniki. Nie ma optymalizacji. FOR (z buforowaniem długości listy) pokazuje najlepszy wynik, podczas gdy FOREACH jest ponad 2 razy wolniejsze. Dzieje się tak, ponieważ zajmuje się MoveNext i Current pod maską. List.ForEach oraz Array.ForEach pokazują najgorszy wynik. Delegaci są zawsze nazywani wirtualnie. Implementacja tej metody wygląda tak:
public void ForEach(Action<T> action)
{
int num = this._version;
for (int index = 0; index < this._size && num == this._version; ++index)
action(this._items[index]);
if (num == this._version)
return;
ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumFailedVersion);
}Każda iteracja wywołuje delegata akcji. Sprawdza również, czy lista została zmieniona, a jeśli tak, zgłaszany jest wyjątek.
List wewnętrznie używa modelu opartego na tablicy, a metoda ForEach używa indeksu tablicy do iteracji, co jest znacznie szybsze niż użycie indeksatora.
Konkretne liczby
- Pętla FOR bez buforowania długości i FOREACH działają nieco szybciej na tablicach niż FOR z buforowaniem długości.
- Tablica.Kierunek wydajność jest około 6 razy wolniejszy niż wydajność FOREACH.
- Pętla FOR bez buforowania długości działa 3 razy wolniej na listach w porównaniu do tablic.
- Pętla FOR z buforowaniem długości działa 2 razy wolniej na listach w porównaniu do tablic.
- Pętla FOREACH działa 6 razy wolniej na listach w porównaniu do tablic.
Oto tablica wyników z listami:
A dla tablic:
Wniosek
Naprawdę podobało mi się to śledztwo, zwłaszcza proces pisania, i mam nadzieję, że również Wam się podobało. Jak się okazało, FOREACH jest szybsze na tablicach niż FOR z pogonią za długością. W strukturach list FOREACH jest wolniejsze niż FOR.
Kod wygląda lepiej przy użyciu FOREACH, a nowoczesne procesory pozwalają na jego używanie. Jeśli jednak potrzebujesz wysoce zoptymalizować bazę kodu, lepiej jest użyć FOR.
Jak myślisz, która pętla działa szybciej, FOREACH czy FOREACH?