Ten artykuł jest trzecim z serii o progach optymalizacji grupowania i agregowania danych. W części 1 omówiłem wcześniej zamówiony algorytm Stream Aggregate. W części 2 omówiłem niezamówiony w przedsprzedaży algorytm Sort + Stream Aggregate. W tej części omówię algorytm Hash Match (Aggregate), który będę nazywał po prostu Hash Aggregate. Przedstawiam również podsumowanie i porównanie algorytmów, które omawiam w części 1, części 2 i części 3.
Użyję tej samej przykładowej bazy danych o nazwie PerformanceV3, z której korzystałem w poprzednich artykułach z serii. Tylko upewnij się, że zanim uruchomisz przykłady w artykule, najpierw uruchom następujący kod, aby usunąć kilka niepotrzebnych indeksów:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Jedyne dwa indeksy, które powinny pozostać w tej tabeli, to idx_cl_od (z klastrem z orderdate jako kluczem) i PK_Orders (bez klastra z orderid jako kluczem).
Agregacja skrótu
Algorytm Hash Aggregate organizuje grupy w tabeli mieszającej w oparciu o wybraną wewnętrznie funkcję mieszającą. W przeciwieństwie do algorytmu Stream Aggregate nie musi on wykorzystywać wierszy w kolejności grupowej. Rozważ następujące zapytanie (nazwiemy je Zapytanie 1) jako przykład (wymuszanie agregacji skrótu i planu szeregowego):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
Rysunek 1 przedstawia plan dla zapytania 1.
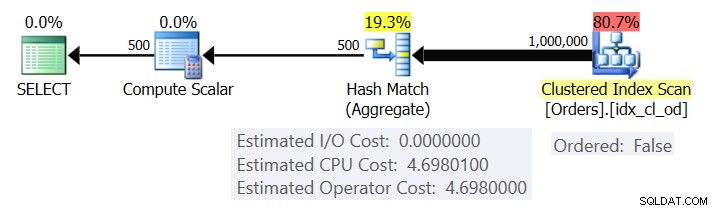
Rysunek 1:Plan dla zapytania 1
Plan skanuje wiersze z indeksu klastrowego przy użyciu właściwości Ordered:False (skanowanie nie jest wymagane w celu dostarczenia wierszy uporządkowanych według klucza indeksu). Zazwyczaj optymalizator woli skanować najwęższy indeks pokrywający, który w naszym przypadku jest indeksem klastrowym. Plan buduje tablicę mieszającą z pogrupowanymi kolumnami i agregatami. Nasze zapytanie żąda agregatu COUNT typu INT. Plan faktycznie oblicza ją jako wartość typu BIGINT, stąd operator Compute Scalar, stosujący niejawną konwersję do INT.
Firma Microsoft nie udostępnia publicznie używanych przez siebie algorytmów mieszających. To bardzo zastrzeżona technologia. Mimo to, aby zilustrować tę koncepcję, załóżmy, że SQL Server używa funkcji skrótu % 250 (modulo 250) dla naszego powyższego zapytania. Przed przetworzeniem jakichkolwiek wierszy nasza tabela mieszająca ma 250 segmentów reprezentujących 250 możliwych wyników funkcji mieszającej (od 0 do 249). Gdy SQL Server przetwarza każdy wiersz, stosuje funkcję skrótu
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
Rysunek 2 przedstawia trzy stany tablicy mieszającej:przed przetworzeniem dowolnych wierszy, po przetworzeniu pierwszych 5 wierszy i po przetworzeniu pierwszych 10 wierszy. Każdy element na połączonej liście zawiera krotkę (empid, COUNT(*)).
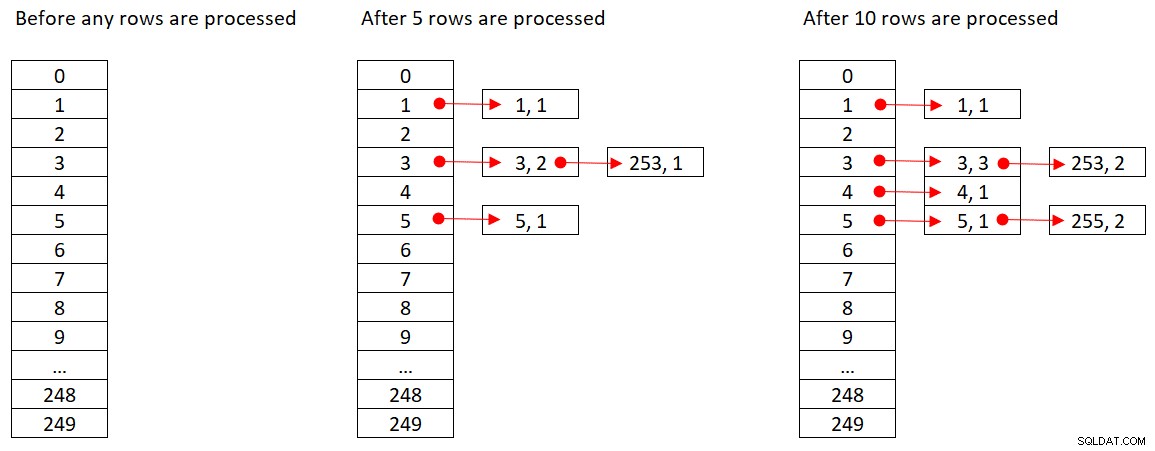
Rysunek 2:Stany tablicy skrótów
Gdy operator Hash Aggregate zakończy zajmowanie wszystkich wierszy wejściowych, tabela mieszania zawiera wszystkie grupy z końcowym stanem agregatu.
Podobnie jak operator Sort, operator Hash Aggregate wymaga przyznania pamięci, a jeśli zabraknie mu pamięci, musi rozlać się do tempdb; jednak podczas gdy sortowanie wymaga przydziału pamięci proporcjonalnego do liczby wierszy do posortowania, mieszanie wymaga przydziału pamięci proporcjonalnego do liczby grup. Tak więc, zwłaszcza gdy zestaw grupujący ma dużą gęstość (mała liczba grup), ten algorytm wymaga znacznie mniej pamięci niż w przypadku, gdy wymagane jest jawne sortowanie.
Rozważ następujące dwa zapytania (nazwij je Zapytanie 1 i Zapytanie 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
Rysunek 3 porównuje przydziały pamięci dla tych zapytań.

Rysunek 3:Plany dla zapytania 1 i zapytania 2
Zwróć uwagę na dużą różnicę między przydziałami pamięci w obu przypadkach.
Jeśli chodzi o koszt operatora Hash Aggregate, wracając do rysunku 1, zauważ, że nie ma żadnych kosztów I/O, a jedynie koszt procesora. Następnie spróbuj odtworzyć formułę kosztorysowania procesora, używając technik podobnych do tych, które omówiłem w poprzednich częściach serii. Czynnikami, które mogą potencjalnie wpłynąć na koszt operatora, są liczba wierszy wejściowych, liczba grup wyjściowych, używana funkcja agregująca i rodzaj grupowania (liczność zestawu grupującego, używane typy danych).
Można by oczekiwać, że ten operator będzie miał koszt uruchomienia w ramach przygotowań do zbudowania tablicy mieszającej. Można by się również spodziewać, że skaluje się liniowo w odniesieniu do liczby wierszy i grup. To właśnie znalazłem. Jednak podczas gdy na koszty operatorów Stream Aggregate i Sort nie ma wpływu sposób grupowania, wydaje się, że koszt operatora Hash Aggregate jest — zarówno pod względem liczności zestawu grupowania, jak i używanych typów danych.
Aby zauważyć, że liczność zbioru grupującego wpływa na koszt operatora, sprawdź koszty procesora operatorów Hash Aggregate w planach dla następujących zapytań (nazwij je Query 3 i Query 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
Oczywiście chcesz się upewnić, że szacowana liczba wierszy wejściowych i grup wyjściowych jest taka sama w obu przypadkach. Szacunkowe plany dla tych zapytań pokazano na rysunku 4.
Rysunek 4:Plany dla zapytania 3 i zapytania 4
Jak widać, koszt procesora operatora Hash Aggregate wynosi 0,16903 przy grupowaniu według jednej kolumny całkowitej i 0,174016 przy grupowaniu według dwóch kolumn całkowitych, przy czym wszystkie inne są równe. Oznacza to, że kardynalność zestawu grupującego rzeczywiście wpływa na koszt.
Co do tego, czy typ danych zgrupowanego elementu ma wpływ na koszt, użyłem następujących zapytań, aby to sprawdzić (nazwijmy je Zapytanie 5, Zapytanie 6 i Zapytanie 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); Plany dla wszystkich trzech zapytań mają tę samą szacowaną liczbę wierszy wejściowych i grup wyjściowych, ale wszystkie mają różne szacowane koszty procesora (0,121766, 0,16903 i 0,171716), dlatego używany typ danych ma wpływ na koszt.
Wydaje się, że rodzaj funkcji agregatu również ma wpływ na koszt. Rozważmy na przykład następujące dwa zapytania (nazwijmy je Zapytanie 8 i Zapytanie 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Szacowany koszt procesora dla Hash Aggregate w planie dla zapytania 8 to 0,166344, a w zapytaniu 9 to 0,16903.
Może to być interesujące ćwiczenie, aby spróbować dokładnie określić, w jaki sposób kardynalność zbioru grupującego, typy danych i używana funkcja agregująca wpływają na koszt; Po prostu nie zajmowałem się tym aspektem kosztów. Tak więc, po dokonaniu wyboru zestawu grupującego i funkcji agregującej dla zapytania, można przeprowadzić inżynierię wsteczną formuły wyceny. Na przykład przeprowadźmy inżynierię wsteczną formuły kalkulacji kosztów procesora dla operatora Hash Aggregate podczas grupowania według pojedynczej kolumny liczb całkowitych i zwracania agregacji MAX(orderdate). Wzór powinien wyglądać następująco:
Koszt procesora operatora =Korzystając z technik, które zademonstrowałem w poprzednich artykułach z tej serii, uzyskałem następującą formułę inżynierii wstecznej:
Koszt procesora operatora =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Możesz sprawdzić dokładność formuły za pomocą następujących zapytań:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Otrzymuję następujące wyniki:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412
Formuła wydaje się być na miejscu.
Podsumowanie i porównanie kosztów
Teraz mamy formuły wyceny dla trzech dostępnych strategii:zamówionych w przedsprzedaży Stream Aggregate, Sort + Stream Aggregate i Hash Aggregate. Poniższa tabela podsumowuje i porównuje charakterystykę kosztów trzech algorytmów:
| Zamówione w przedsprzedaży zagregowane strumienie | Sortuj + agregacja strumienia | Agregacja haszująca | |
| Formuła | @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,0112613 + Mała liczba rzędów: 9.99127891201865E-05 + @numrows * DZIENNIK(@numrows) * 2.25061348918698E-06 Duża liczba rzędów: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
* Grupowanie według pojedynczej kolumny liczb całkowitych, zwracanie MAX( |
| Skalowanie | liniowy | n log n | liniowy |
| Koszt we/wy rozruchu | brak | 0,0112613 | brak |
| Koszt procesora podczas uruchamiania | brak | ~ 0,0001 | 0,017749 |
Zgodnie z tymi wzorami, Rysunek 5 pokazuje, w jaki sposób każda ze strategii skaluje się dla różnej liczby wierszy wejściowych, na przykładzie stałej liczby grup 500.
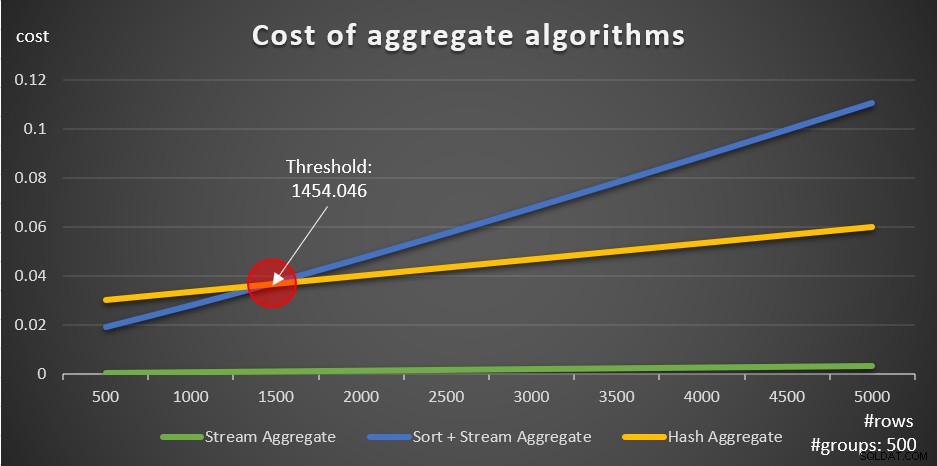
Rysunek 5:Koszt algorytmów agregujących
Widać wyraźnie, że jeśli dane są uporządkowane w przedsprzedaży, np. w indeksie pokrywającym, zamówiona w przedsprzedaży strategia Stream Aggregate jest najlepszą opcją, niezależnie od liczby zaangażowanych wierszy. Załóżmy na przykład, że musisz wykonać zapytanie do tabeli Zamówienia i obliczyć maksymalną datę zamówienia dla każdego pracownika. Tworzysz następujący indeks pokrycia:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Oto pięć zapytań emulujących tabelę Zamówienia z różną liczbą wierszy (10 000, 20 000, 30 000, 40 000 i 50 000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Rysunek 6 przedstawia plany dla tych zapytań.
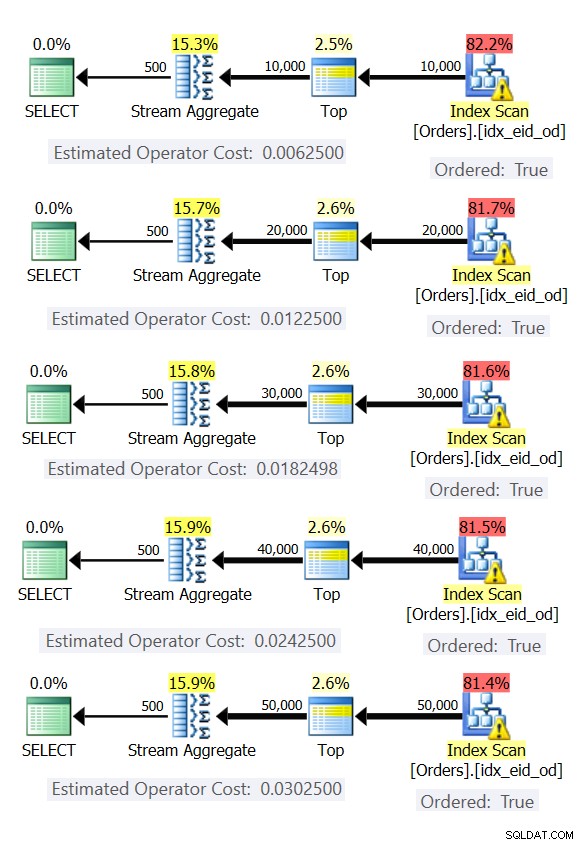
Rysunek 6:Plany ze strategią Stream Aggregate zamówioną w przedsprzedaży
We wszystkich przypadkach plany wykonują uporządkowane skanowanie indeksu pokrycia i stosują operator Stream Aggregate bez potrzeby jawnego sortowania.
Użyj następującego kodu, aby usunąć indeks utworzony dla tego przykładu:
DROP INDEX idx_eid_od ON dbo.Orders;
Inną ważną rzeczą, na którą należy zwrócić uwagę w przypadku wykresów na rysunku 5, jest to, co dzieje się, gdy dane nie są uporządkowane w przedsprzedaży. Dzieje się tak, gdy nie ma indeksu pokrywającego, a także gdy grupujesz według manipulowanych wyrażeń, w przeciwieństwie do kolumn podstawowych. Istnieje próg optymalizacji — w naszym przypadku 1454.046 wierszy — poniżej którego strategia Sort + Stream Aggregate ma niższy koszt i powyżej którego strategia Hash Aggregate ma niższy koszt. Ma to związek z faktem, że pierwszy ma niższy koszt uruchomienia, ale skaluje się w sposób n log n, podczas gdy drugi ma wyższy koszt uruchomienia, ale skaluje się liniowo. To sprawia, że ta pierwsza jest preferowana przy małej liczbie wierszy wejściowych. Jeśli nasze formuły inżynierii wstecznej są dokładne, następujące dwa zapytania (nazwij je Zapytanie 10 i Zapytanie 11) powinny otrzymać różne plany:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Plany dla tych zapytań pokazano na rysunku 7.
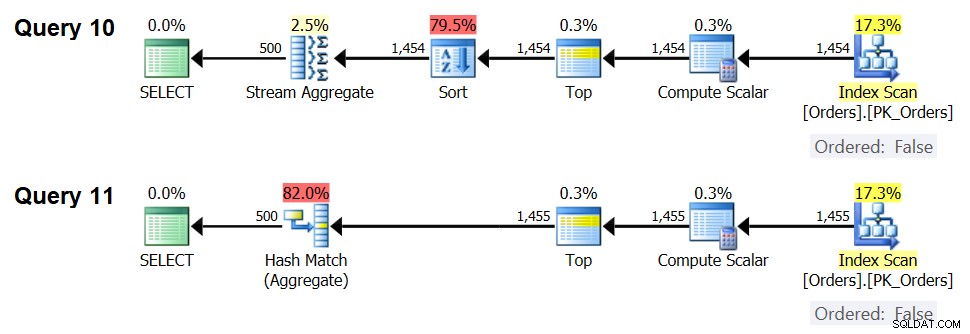
Rysunek 7:Plany dla zapytania 10 i zapytania 11
Rzeczywiście, przy 1454 wierszach wejściowych (poniżej progu optymalizacji) optymalizator naturalnie preferuje algorytm Sort + Stream Aggregate dla Zapytania 10, a przy 1455 wierszach wejściowych (powyżej progu optymalizacji) optymalizator naturalnie preferuje algorytm Hash Aggregate dla Zapytania 11. .
Potencjał operatora Adaptive Aggregate
Jednym z trudnych aspektów progów optymalizacji są problemy z wykrywaniem parametrów podczas używania zapytań wrażliwych na parametry w procedurach składowanych. Rozważ następującą procedurę składowaną jako przykład:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
Tworzysz następujący optymalny indeks do obsługi zapytania procedury składowanej:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Utworzyłeś indeks z identyfikatorem zamówienia jako kluczem do obsługi filtra zakresu zapytania i uwzględniłeś empid dla pokrycia. Jest to sytuacja, w której nie można tak naprawdę utworzyć indeksu, który będzie zarówno obsługiwał filtr zakresu, jak i przefiltrowane wiersze wstępnie uporządkowane według zestawu grupującego. Oznacza to, że optymalizator będzie musiał dokonać wyboru między algorytmem Sort + stream Aggregate a algorytmem Hash Aggregate. W oparciu o nasze formuły wyceny, próg optymalizacji wynosi od 937 do 938 wierszy wejściowych (powiedzmy, 937,5 wierszy).
Załóżmy, że wykonujesz procedurę składowaną po raz pierwszy z wejściowym identyfikatorem zamówienia początkowego, który daje niewielką liczbę dopasowań (poniżej progu):
EXEC dbo.EmpOrders @initialorderid = 999991;
SQL Server tworzy plan korzystający z algorytmu Sort + Stream Aggregate i buforuje plan. Kolejne wykonania ponownie wykorzystują buforowany plan, niezależnie od liczby zaangażowanych wierszy. Na przykład następujące wykonanie ma liczbę dopasowań powyżej progu optymalizacji:
EXEC dbo.EmpOrders @initialorderid = 990001;
Mimo to ponownie wykorzystuje buforowany plan, mimo że nie jest optymalny do tego wykonania. To klasyczny problem z wąchaniem parametrów.
SQL Server 2017 wprowadza możliwości adaptacyjnego przetwarzania zapytań, które są zaprojektowane tak, aby radzić sobie w takich sytuacjach, określając podczas wykonywania zapytania, którą strategię zastosować. Wśród tych ulepszeń znajduje się operator Adaptive Join, który podczas wykonywania określa, czy aktywować algorytm Loop, czy Hash w oparciu o obliczony próg optymalizacji. Nasza zagregowana historia błaga o podobny operator Adaptive Aggregate, który podczas wykonywania dokonywałby wyboru między strategią Sort + Stream Aggregate a strategią Hash Aggregate na podstawie obliczonego progu optymalizacji. Rysunek 8 ilustruje pseudo plan oparty na tym pomyśle.
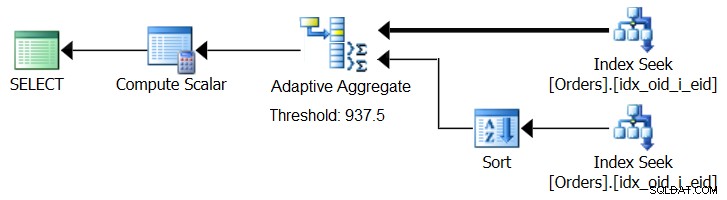
Rysunek 8:Pseudo plan z operatorem Adaptive Aggregate
Na razie, aby uzyskać taki plan, trzeba skorzystać z Microsoft Paint. Ale ponieważ koncepcja adaptacyjnego przetwarzania zapytań jest tak inteligentna i działa tak dobrze, rozsądnie jest oczekiwać dalszych ulepszeń w tym obszarze w przyszłości.
Uruchom następujący kod, aby usunąć indeks utworzony dla tego przykładu:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Wniosek
W tym artykule omówiłem kosztorysowanie i skalowanie algorytmu Hash Aggregate i porównałem je ze strategiami Stream Aggregate i Sort + Stream Aggregate. Opisałem próg optymalizacji, który istnieje między strategiami Sort + Stream Aggregate i Hash Aggregate. W przypadku małej liczby wierszy wejściowych preferowany jest pierwszy, a przy dużych liczbach drugi. Opisałem również możliwość dodania operatora Adaptive Aggregate, podobnego do już zaimplementowanego operatora Adaptive Join, aby pomóc w radzeniu sobie z problemami związanymi z wąchaniem parametrów podczas korzystania z zapytań wrażliwych na parametry. W przyszłym miesiącu będę kontynuować dyskusję, omawiając zagadnienia dotyczące paralelizmu i przypadki, które wymagają przepisania zapytań.