Typ danych ciąg jest jednym z najważniejszych typów danych w dowolnym języku programowania. Bez tego trudno napisać użyteczny program. Mimo to wielu programistów nie zna pewnych aspektów tego typu. Dlatego rozważmy te aspekty.
Reprezentacja ciągów w pamięci
W .Net ciągi są lokalizowane zgodnie z regułą BSTR (podstawowy ciąg lub ciąg binarny). Ta metoda reprezentacji danych ciągów jest używana w modelu COM (słowo „podstawowy” pochodzi z języka programowania Visual Basic, w którym było pierwotnie używane). Jak wiemy, PWSZ (Pointer to Wide-Character String, Zero-terminated) jest używany w C/C++ do reprezentacji łańcuchów. Przy takiej lokalizacji w pamięci znak zakończony znakiem NUL znajduje się na końcu łańcucha. Ten terminator pozwala określić koniec ciągu. Długość łańcucha w PWSZ jest ograniczona jedynie ilością wolnego miejsca.
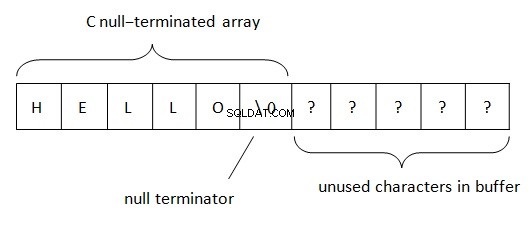
W BSTR sytuacja jest nieco inna.
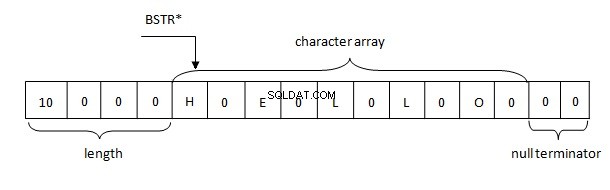
Podstawowe aspekty reprezentacji ciągu BSTR w pamięci są następujące:
- Długość ciągu jest ograniczona przez określoną liczbę. W PWSZ długość ciągu jest ograniczona dostępnością wolnej pamięci.
- Ciąg BSTR zawsze wskazuje na pierwszy znak w buforze. PWSZ może wskazywać na dowolny znak w buforze.
- W BSTR, podobnie jak w PWSZ, znak null zawsze znajduje się na końcu. W BSTR znak null jest prawidłowym znakiem i można go znaleźć w dowolnym miejscu ciągu.
- Ponieważ terminator zerowy znajduje się na końcu, BSTR jest kompatybilny z PWSZ, ale nie odwrotnie.
Dlatego ciągi w .NET są reprezentowane w pamięci zgodnie z regułą BSTR. Bufor zawiera 4-bajtową długość ciągu, po której następują dwubajtowe znaki ciągu w formacie UTF-16, po którym z kolei następują dwa bajty null (\u0000).
Korzystanie z tej implementacji ma wiele zalet:długość łańcucha nie może być przeliczana, ponieważ jest przechowywana w nagłówku, łańcuch może zawierać znaki null w dowolnym miejscu. A najważniejsze jest to, że adres ciągu (przypięty) można łatwo przekazać w kodzie natywnym, gdzie WCHAR* jest oczekiwany.
Ile pamięci zajmuje obiekt tekstowy?
Natknąłem się na artykuły stwierdzające, że rozmiar obiektu napisowego jest równy size=20 + (długość/2)*4, ale ta formuła nie jest do końca poprawna.
Po pierwsze, ciąg jest typem łącza, więc pierwsze cztery bajty zawierają SyncBlockIndex a następne cztery bajty zawierają wskaźnik typu.
Rozmiar sznurka =4 + 4 + …
Jak wspomniałem powyżej, długość łańcucha jest przechowywana w buforze. Jest to pole typu int, dlatego musimy dodać kolejne 4 bajty.
Rozmiar sznurka =4 + 4 + 4 + …
Aby szybko przekazać ciąg do kodu natywnego (bez kopiowania), terminator null znajduje się na końcu każdego ciągu, który zajmuje 2 bajty. Dlatego
Rozmiar sznurka =4 + 4 + 4 + 2 + …
Pozostaje tylko przypomnieć, że każdy znak w łańcuchu jest w kodowaniu UTF-16 i zajmuje 2 bajty. Dlatego:
Rozmiar sznurka =4 + 4 + 4 + 2 + 2 * długość =14 + 2 * długość
Jeszcze jedno i gotowe. Pamięć przydzielona przez menedżera pamięci w CLR jest wielokrotnością 4 bajtów (4, 8, 12, 16, 20, 24, …). Tak więc, jeśli długość łańcucha zajmie łącznie 34 bajty, zostanie przydzielonych 36 bajtów. Musimy zaokrąglić naszą wartość do najbliższej większej liczby, która jest wielokrotnością czterech. W tym celu potrzebujemy:
Rozmiar ciągu =4 * ((14 + 2 * długość + 3) / 4) (dzielenie liczb całkowitych)
Problem wersji :do .NET v4 istniał dodatkowy m_arrayLength pole typu int w klasie String, które zajmowało 4 bajty. To pole jest rzeczywistą długością bufora zaalokowanego na łańcuch, łącznie z terminatorem zerowym, czyli jest to długość + 1. W .NET 4.0 to pole zostało usunięte z klasy. W rezultacie obiekt typu string zajmuje 4 bajty mniej.
Rozmiar pustego ciągu bez m_arrayLength pole (tj. w .Net 4.0 i wyższych) wynosi =4 + 4 + 4 + 2 =14 bajtów i przy tym polu (tj. mniejszym niż .Net 4.0) jego rozmiar wynosi =4 + 4 + 4 + 4 + 2 =18 bajtów. Jeśli zaokrąglimy 4 bajty, rozmiar będzie wynosił odpowiednio 16 i 20 bajtów.
Aspekty ciągów
Rozważaliśmy więc reprezentację ciągów i rozmiar, jaki przyjmują w pamięci. Porozmawiajmy teraz o ich osobliwościach.
Podstawowe aspekty łańcuchów w .NET są następujące:
- Ciągi są typami referencyjnymi.
- Ciągi są niezmienne. Raz utworzony ciąg nie może być modyfikowany (w uczciwy sposób). Każde wywołanie metody tej klasy zwraca nowy ciąg, podczas gdy poprzedni ciąg staje się łupem dla odśmiecacza.
- Strings redefiniują metodę Object.Equals. W rezultacie metoda porównuje wartości znaków w ciągach, a nie wartości linków.
Rozważmy szczegółowo każdy punkt.
Ciągi są typami referencyjnymi
Ciągi są prawdziwymi typami referencyjnymi. Oznacza to, że zawsze znajdują się na kupie. Wielu z nas myli je z typami wartości, ponieważ ty zachowujesz się w ten sam sposób. Na przykład są niezmienne, a ich porównanie odbywa się według wartości, a nie przez referencje, ale musimy pamiętać, że jest to typ referencyjny.
Ciągi są niezmienne
- Ciągi są niezmienne w określonym celu. Niezmienność ciągu ma wiele zalet:
- Typ ciągu jest bezpieczny dla wątków, ponieważ żaden wątek nie może modyfikować zawartości ciągu.
- Użycie niezmiennych ciągów prowadzi do zmniejszenia obciążenia pamięci, ponieważ nie ma potrzeby przechowywania 2 wystąpień tego samego ciągu. W rezultacie zużywa się mniej pamięci, a porównanie jest wykonywane szybciej, ponieważ porównywane są tylko odwołania. W .NET mechanizm ten nazywa się interningiem ciągów (pula ciągów). Porozmawiamy o tym nieco później.
- Przekazując niezmienny parametr do metody, możemy przestać się martwić, że zostanie on zmodyfikowany (oczywiście, jeśli nie został przekazany jako ref lub out).
Struktury danych można podzielić na dwa typy:efemeryczne i trwałe. Efemeryczne struktury danych przechowują tylko ich ostatnie wersje. Trwałe struktury danych zapisują wszystkie swoje poprzednie wersje podczas modyfikacji. Te ostatnie są w rzeczywistości niezmienne, ponieważ ich działania nie modyfikują struktury na miejscu. Zamiast tego zwracają nową strukturę opartą na poprzedniej.
Biorąc pod uwagę fakt, że łańcuchy są niezmienne, mogą być trwałe, ale tak nie jest. Ciągi znaków są efemeryczne w .Net.
Dla porównania weźmy stringi w Javie. Są niezmienne, podobnie jak w .NET, ale dodatkowo są trwałe. Implementacja klasy String w Javie wygląda następująco:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Oprócz 8 bajtów w nagłówku obiektu, w tym referencji do typu i referencji do obiektu synchronizacji, stringi zawierają następujące pola:
- Odwołanie do tablicy znaków;
- Indeks pierwszego znaku ciągu w tablicy znaków (przesunięcie od początku)
- Liczba znaków w ciągu;
- Kod skrótu obliczony po pierwszym wywołaniu funkcji HashCode() metoda.
Łańcuchy w Javie zajmują więcej pamięci niż w .NET, ponieważ zawierają dodatkowe pola, dzięki którym są trwałe. Dzięki trwałości wykonanie String.substring() metoda w Javie przyjmuje O(1) , ponieważ nie wymaga kopiowania ciągów jak w .NET, gdzie wykonanie tej metody zajmuje O(n) .
Implementacja metody String.substring() w Javie:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Jeśli jednak ciąg źródłowy jest wystarczająco duży, a podciąg wycinany ma długość kilku znaków, cała tablica znaków początkowego ciągu będzie oczekująca w pamięci, dopóki nie pojawi się odwołanie do podciągu. Lub, jeśli zserializujesz odebrany podciąg w sposób standardowy i przekażesz go przez sieć, cała oryginalna tablica zostanie zserializowana, a liczba bajtów przesyłanych przez sieć będzie duża. Dlatego zamiast kodu
s =ss.podciąg(3)
można użyć następującego kodu:
s =nowy ciąg(ss.substring(3)),
Ten kod nie przechowuje odniesienia do tablicy znaków ciągu źródłowego. Zamiast tego skopiuje tylko faktycznie używaną część tablicy. Nawiasem mówiąc, jeśli wywołamy ten konstruktor na łańcuchu, którego długość jest równa długości tablicy znaków, kopiowanie nie nastąpi. Zamiast tego zostanie użyte odniesienie do oryginalnej tablicy.
Jak się okazało, w ostatniej wersji Javy zmieniono implementację typu string. Teraz w klasie nie ma pól przesunięcia i długości. Nowy hash32 (z innym algorytmem haszującym) został wprowadzony. Oznacza to, że ciągi nie są już trwałe. Teraz String.substring metoda utworzy nowy ciąg za każdym razem.
Ciąg przedefiniuj Onbject.Equals
Klasa ciągu ponownie definiuje metodę Object.Equals. W rezultacie następuje porównanie, ale nie przez odniesienie, ale przez wartość. Przypuszczam, że programiści są wdzięczni twórcom klasy String za przedefiniowanie operatora ==, ponieważ kod, który używa ==do porównywania ciągów, wygląda bardziej szczegółowo niż wywołanie metody.
if (s1 == s2)
W porównaniu z
if (s1.Equals(s2))
Nawiasem mówiąc, w Javie operator ==porównuje przez odwołanie. Jeśli chcesz porównać ciągi znaków według znaków, musimy użyć metody string.equals().
String Interning
Na koniec rozważmy internowanie strunowe. Rzućmy okiem na prosty przykład – kod, który odwraca ciąg znaków.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Oczywiście tego kodu nie można skompilować. Kompilator wyrzuci błędy dla tych ciągów, ponieważ próbujemy zmodyfikować zawartość ciągu. Każda metoda klasy String zwraca nową instancję ciągu, zamiast modyfikacji jego zawartości.
Ciąg można modyfikować, ale będziemy musieli użyć niebezpiecznego kodu. Rozważmy następujący przykład:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Po wykonaniu tego kodu elbatummi era sgnirtS zgodnie z oczekiwaniami zostanie zapisany w ciągu. Zmienność ciągów prowadzi do fantazyjnego przypadku związanego z internowaniem ciągów.
Trening na sznurku to mechanizm, w którym podobne literały są reprezentowane w pamięci jako pojedynczy obiekt.
W skrócie, punkt interningu ciągów jest następujący:istnieje pojedyncza zaszyfrowana tabela wewnętrzna w procesie (nie w domenie aplikacji), w której ciągi są jego kluczami, a wartości są odniesieniami do nich. Podczas kompilacji JIT ciągi literałów są umieszczane w tabeli sekwencyjnie (każdy ciąg w tabeli można znaleźć tylko raz). Podczas wykonywania z tej tabeli przypisywane są odwołania do łańcuchów literału. Podczas wykonywania możemy umieścić ciąg w wewnętrznej tabeli za pomocą String.Intern metoda. Ponadto możemy sprawdzić dostępność ciągu w wewnętrznej tabeli za pomocą String.IsInterned metoda.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Zauważ, że domyślnie internowane są tylko literały łańcuchowe. Ponieważ zaszyfrowana tabela wewnętrzna jest używana do implementacji interningu, wyszukiwanie w tej tabeli jest wykonywane podczas kompilacji JIT. Ten proces zajmuje trochę czasu. Tak więc, jeśli wszystkie ciągi są internowane, zmniejszy to optymalizację do zera. Podczas kompilacji do kodu IL kompilator łączy wszystkie dosłowne łańcuchy, ponieważ nie ma potrzeby przechowywania ich w częściach. Dlatego druga równość zwraca prawdę .
Wróćmy teraz do naszej sprawy. Rozważ następujący kod:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Wygląda na to, że wszystko jest dość oczywiste i kod powinien zwrócić Ciągi są niezmienne . Jednak tak nie jest! Kod zwraca elbatummi era sgnirtS . Dzieje się tak właśnie z powodu stażu. Kiedy modyfikujemy łańcuchy, modyfikujemy jego zawartość, a ponieważ jest on dosłowny, jest on umieszczany i reprezentowany przez pojedynczą instancję łańcucha.
Możemy zrezygnować z przeplatania ciągów, jeśli zastosujemy CompilationRelaxationsAttribute atrybut do zestawu. Ten atrybut kontroluje dokładność kodu, który jest tworzony przez kompilator JIT środowiska CLR. Konstruktor tego atrybutu akceptuje CompilationRelaxations wyliczenie, które obecnie obejmuje tylko CompilationRelaxations.NoStringInterning . W rezultacie zespół jest oznaczony jako ten, który nie wymaga internowania.
Nawiasem mówiąc, ten atrybut nie jest przetwarzany w .NET Framework v1.0. Dlatego nie można było wyłączyć stażu. Od wersji 2 mscorlib zespół jest oznaczony tym atrybutem. Okazuje się więc, że ciągi w .NET można modyfikować za pomocą niebezpiecznego kodu.
Co jeśli zapomnimy o zagrożeniach?
Tak się składa, że możemy modyfikować treść ciągu bez niebezpiecznego kodu. Zamiast tego możemy użyć mechanizmu odbicia. Ta sztuczka odniosła sukces w .NET do wersji 2.0. Później twórcy klasy String pozbawili nas tej możliwości. W .NET 2.0 klasa String ma dwie metody wewnętrzne:SetChar do sprawdzania granic i InternalSetCharNoBoundsCheck to nie powoduje sprawdzania granic. Te metody ustawiają określony znak przez określony indeks. Implementacja metod wygląda następująco:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Dlatego możemy modyfikować treść ciągu bez niebezpiecznego kodu za pomocą następującego kodu:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Zgodnie z oczekiwaniami kod zwraca elbatummi era sgnirtS .
Problem wersji :w różnych wersjach .NET Framework, string.Empty może być zintegrowany lub nie. Rozważmy następujący kod:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); W .NET Framework 1.0, .NET Framework 1.1 i .NET Framework 3.5 z dodatkiem Service Pack 1 (SP1), str1 i str2 nie są równe. Obecnie string.Pusty nie jest internowany.
Aspekty wydajności
Jest jeden negatywny efekt uboczny stażu. Rzecz w tym, że odwołanie do obiektu internowanego typu String przechowywanego przez CLR można zapisać nawet po zakończeniu pracy aplikacji, a nawet po zakończeniu pracy domeny aplikacji. Dlatego lepiej jest zrezygnować z używania dużych ciągów dosłownych. Jeśli nadal jest to wymagane, należy wyłączyć staż, stosując CompilationRelaxations atrybut do zestawu.