Pojęcie dobrego lub złego projektu jest względne. Jednocześnie istnieją pewne standardy programowania, które w większości przypadków gwarantują skuteczność, pielęgnowalność i testowalność. Na przykład w językach obiektowych jest to użycie enkapsulacji, dziedziczenia i polimorfizmu. Istnieje zestaw wzorców projektowych, które w wielu przypadkach mają pozytywny lub negatywny wpływ na projekt aplikacji w zależności od sytuacji. Z drugiej strony istnieją przeciwieństwa, które czasami prowadzą do zaprojektowania problemu.
Ten projekt ma zwykle następujące wskaźniki (jeden lub kilka naraz):
- Sztywność (trudno jest zmodyfikować kod, ponieważ prosta zmiana dotyczy wielu miejsc);
- Nieruchomość (skomplikowane jest dzielenie kodu na moduły, które można wykorzystać w innych programach);
- Lepkość (jest dość trudne do opracowania lub przetestowania kodu);
- Niepotrzebna złożoność (w kodzie jest niewykorzystana funkcjonalność);
- Niepotrzebne powtarzanie (kopiuj/wklej);
- Słaba czytelność (trudno zrozumieć, do czego przeznaczony jest kod i jak go utrzymywać);
- Kruchość (łatwo jest przerwać funkcjonalność nawet przy niewielkich zmianach).
Musisz być w stanie zrozumieć i rozróżnić te cechy, aby uniknąć problematycznego projektu lub przewidzieć możliwe konsekwencje jego użycia. Wskaźniki te zostały opisane w książce Roberta Martina „Zwinne zasady, wzorce i praktyki w C#”. Jednak w tym artykule, a także w innych artykułach przeglądowych, znajduje się krótki opis i brak przykładów kodu.
Zamierzamy wyeliminować tę wadę związaną z każdą funkcją.
Sztywność
Jak już wspomniano, sztywny kod jest trudny do modyfikacji, nawet najdrobniejszych rzeczy. Może to nie stanowić problemu, jeśli kod nie jest zmieniany często lub wcale. Tak więc kod okazuje się całkiem dobry. Jeśli jednak konieczna jest modyfikacja kodu i jest to trudne do zrobienia, staje się to problemem, nawet jeśli działa.
Jednym z popularnych przypadków sztywności jest jawne określenie typów klas zamiast używania abstrakcji (interfejsów, klas bazowych itp.). Poniżej przykładowy kod:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Tutaj klasa A bardzo zależy od klasy B. Tak więc, jeśli w przyszłości będziesz musiał użyć innej klasy zamiast klasy B, będzie to wymagało zmiany klasy A i doprowadzi do jej ponownego przetestowania. Ponadto, jeśli klasa B wpływa na inne klasy, sytuacja znacznie się komplikuje.
Obejście to jest abstrakcją, która polega na wprowadzeniu interfejsu IComponent za pośrednictwem konstruktora klasy A. W tym przypadku nie będzie już zależeć od konkretnej klasy В i będzie zależeć tylko od interfejsu IComponent. Klasa В z kolei musi implementować interfejs IComponent.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Podajmy konkretny przykład. Załóżmy, że istnieje zestaw klas, które rejestrują informacje – ProductManager i Consumer. Ich zadaniem jest przechowywanie produktu w bazie danych i odpowiednie zamówienie. Obie klasy rejestrują odpowiednie zdarzenia. Wyobraź sobie, że na początku do pliku był log. W tym celu wykorzystano klasę FileLogger. Ponadto klasy znajdowały się w różnych modułach (zespołach).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Jeśli na początku wystarczyło użyć samego pliku, a potem konieczne stanie się logowanie do innych repozytoriów, takich jak baza danych lub usługa gromadzenia i przechowywania danych w chmurze, to będziemy musieli zmienić wszystkie klasy w logice biznesowej moduł (moduł 2) korzystający z FileLogger. W końcu może się to okazać trudne. Aby rozwiązać ten problem, możemy wprowadzić abstrakcyjny interfejs do pracy z rejestratorem, jak pokazano poniżej.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} W takim przypadku przy zmianie typu rejestratora wystarczy zmodyfikować kod klienta (Main), który inicjuje rejestrator i dodaje go do konstruktora ProductManagera i Konsumenta. W ten sposób zamknęliśmy klasy logiki biznesowej przed modyfikacją typu rejestratora zgodnie z wymaganiami.
Oprócz bezpośrednich linków do używanych klas, możemy monitorować sztywność w innych wariantach, które mogą powodować trudności podczas modyfikacji kodu. Może być ich nieskończona ilość. Postaramy się jednak podać inny przykład. Załóżmy, że istnieje kod, który wyświetla na konsoli obszar wzoru geometrycznego.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Jak widać przy dodawaniu nowego wzorca będziemy musieli zmienić metody klasy ShapeHelper. Jedną z opcji jest przekazanie algorytmu renderowania w klasach wzorów geometrycznych (Prostokąt i Koło), jak pokazano poniżej. W ten sposób izolujemy odpowiednią logikę w odpowiednich klasach, zmniejszając w ten sposób odpowiedzialność klasy ShapeHelper przed wyświetleniem informacji na konsoli.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} W rezultacie faktycznie zamknęliśmy klasę ShapeHelper dla zmian, które dodają nowe typy wzorców za pomocą dziedziczenia i polimorfizmu.
Nieruchomość
Możemy monitorować bezruch podczas dzielenia kodu na moduły wielokrotnego użytku. W rezultacie projekt może przestać się rozwijać i być konkurencyjny.
Jako przykład rozważymy program desktopowy, którego cały kod jest zaimplementowany w wykonywalnym pliku aplikacji (.exe) i został zaprojektowany tak, aby logika biznesowa nie była zbudowana w osobnych modułach lub klasach. Później deweloper stanął przed następującymi wymaganiami biznesowymi:
- Aby zmienić interfejs użytkownika, zmieniając go w aplikację internetową;
- Opublikowanie funkcjonalności programu jako zestawu usług internetowych dostępnych dla klientów zewnętrznych do wykorzystania w ich własnych aplikacjach.
W tym przypadku te wymagania są trudne do spełnienia, ponieważ cały kod znajduje się w module wykonywalnym.
Poniższy rysunek przedstawia przykład konstrukcji nieruchomej w przeciwieństwie do tej, która nie ma tego wskaźnika. Są oddzielone linią kropkowaną. Jak widać rozmieszczenie kodu na modułach wielokrotnego użytku (Logic), a także publikacja funkcjonalności na poziomie usług internetowych, pozwalają na wykorzystanie go w różnych aplikacjach klienckich (App), co jest niewątpliwą korzyścią.
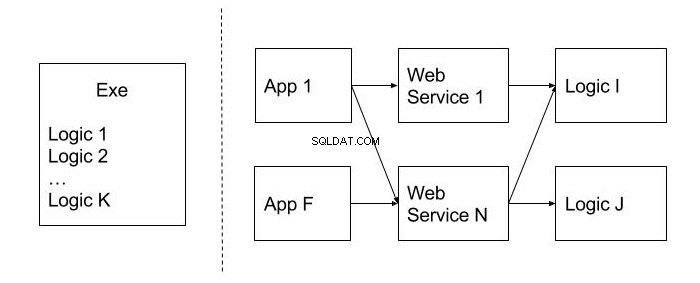
Nieruchomość można również nazwać konstrukcją monolityczną. Trudno podzielić go na mniejsze i przydatne jednostki kodu. Jak możemy uniknąć tego problemu? Na etapie projektowania lepiej zastanowić się, jakie jest prawdopodobieństwo wykorzystania tej lub innej funkcji w innych systemach. Kod, który ma zostać ponownie użyty, najlepiej umieścić w osobnych modułach i klasach.
Lepkość
Istnieją dwa typy:
- Lepkość rozwoju
- Lepkość środowiskowa
Widzimy lepkość rozwoju, starając się podążać za wybranym projektem aplikacji. Może się to zdarzyć, gdy programista musi spełnić zbyt wiele wymagań, gdy istnieje łatwiejszy sposób rozwoju. Ponadto lepkość programowania można zobaczyć, gdy proces montażu, wdrażania i testowania nie jest skuteczny.
Jako prosty przykład możemy rozważyć pracę ze stałymi, które mają być umieszczone (Według projektu) w oddzielnym module (Moduł 1), który ma być używany przez inne komponenty (Moduł 2 i Moduł 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Jeśli z jakiegoś powodu proces montażu zajmie dużo czasu, deweloperom będzie trudno czekać na jego zakończenie. Dodatkowo należy zauważyć, że moduł stały zawiera byty mieszane, należące do różnych części logiki biznesowej (moduły finansowe i marketingowe). Tak więc moduł stały może być dość często zmieniany z powodów, które są od siebie niezależne, co może prowadzić do dodatkowych problemów, takich jak synchronizacja zmian.
Wszystko to spowalnia proces rozwoju i może stresować programistów. Warianty mniej lepkiego projektu polegałyby albo na utworzeniu oddzielnych modułów stałych – po jednym dla odpowiedniego modułu logiki biznesowej – albo przekazaniu stałych we właściwe miejsce bez brania dla nich osobnego modułu.
Przykładem lepkości środowiska może być rozwój i testowanie aplikacji na zdalnej maszynie wirtualnej klienta. Czasami ten przepływ pracy staje się nie do zniesienia z powodu wolnego połączenia internetowego, więc programista może systematycznie ignorować testowanie integracji napisanego kodu, co może ostatecznie prowadzić do błędów po stronie klienta podczas korzystania z tej funkcji.
Niepotrzebna złożoność
W tym przypadku projekt ma właściwie niewykorzystaną funkcjonalność. Fakt ten może skomplikować wsparcie i utrzymanie programu, a także wydłużyć czas rozwoju i testowania. Rozważmy na przykład program, który wymaga odczytania niektórych danych z bazy danych. W tym celu został utworzony komponent DataManager, który jest używany w innym komponencie.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Jeśli programista doda nową metodę do DataManager do zapisywania danych w bazie danych (WriteData), która prawdopodobnie nie będzie używana w przyszłości, będzie to również niepotrzebna złożoność.
Innym przykładem jest interfejs do wszystkich celów. Na przykład rozważymy interfejs z pojedynczą metodą Process, która akceptuje obiekt typu string.
interface IProcessor
{
void Process(string message);
} Gdyby zadaniem było przetworzenie określonego typu wiadomości o dobrze zdefiniowanej strukturze, łatwiej byłoby stworzyć ściśle typizowany interfejs, niż zmuszać programistów do deserializacji tego ciągu za każdym razem do określonego typu wiadomości.
Nadużywanie wzorców projektowych w przypadkach, gdy nie jest to wcale konieczne, może również prowadzić do projektowania lepkości.
Po co marnować czas na pisanie potencjalnie niewykorzystanego kodu? Czasami kontrola jakości ma na celu przetestowanie tego kodu, ponieważ jest on faktycznie opublikowany i otwarty do użytku przez klientów zewnętrznych. To również opóźnia czas wydania. Uwzględnienie funkcji na przyszłość jest warte tylko wtedy, gdy jej potencjalne korzyści przewyższają koszty jej rozwoju i testowania.
Niepotrzebne powtórzenia
Być może większość programistów zetknęło się lub zetknie się z tą funkcją, która polega na wielokrotnym kopiowaniu tej samej logiki lub kodu. Głównym zagrożeniem jest podatność tego kodu na modyfikację – naprawiając coś w jednym miejscu, możesz zapomnieć zrobić to w innym. Ponadto wprowadzanie zmian zajmuje więcej czasu w porównaniu z sytuacją, gdy kod nie zawiera tej funkcji.
Niepotrzebne powtarzanie może wynikać z zaniedbań programistów, a także z powodu sztywności/kruchości projektu, gdy o wiele trudniej i bardziej ryzykownie jest nie powtarzać kodu niż to robić. Jednak w każdym przypadku powtarzalność nie jest dobrym pomysłem i konieczne jest ciągłe ulepszanie kodu, przekazywanie części wielokrotnego użytku do wspólnych metod i klas.
Słaba czytelność
Możesz monitorować tę funkcję, gdy trudno jest odczytać kod i zrozumieć, do czego jest stworzona. Przyczyną słabej czytelności może być niezgodność z wymaganiami dotyczącymi wykonania kodu (składnia, zmienne, klasy), skomplikowana logika implementacji itp.
Poniżej znajduje się przykład trudnego do odczytania kodu, który implementuje metodę ze zmienną Boolean.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Tutaj możemy nakreślić kilka kwestii. Po pierwsze, nazwy metod i zmiennych nie są zgodne z ogólnie przyjętymi konwencjami. Po drugie, implementacja metody nie jest najlepsza.
Być może warto wziąć wartość logiczną, a nie ciąg. Jednak lepiej jest przekonwertować ją na wartość logiczną na początku metody, zamiast używać metody określania długości łańcucha.
Po trzecie, tekst wyjątku nie odpowiada oficjalnemu stylowi. Czytając takie teksty, można odnieść wrażenie, że kod jest tworzony przez amatora (choć może być kwestia sporna). Metoda może zostać przepisana w następujący sposób, jeśli przyjmuje wartość logiczną:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Oto kolejny przykład refaktoryzacji, jeśli nadal musisz wziąć ciąg:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Zaleca się przeprowadzanie refaktoryzacji za pomocą trudnego do odczytania kodu, na przykład, gdy jego utrzymanie i klonowanie prowadzi do wielu błędów.
Kruchość
Kruchość programu oznacza, że można go łatwo zawiesić podczas modyfikacji. Istnieją dwa rodzaje awarii:błędy kompilacji i błędy czasu wykonywania. Te pierwsze mogą być tylną stroną sztywności. Te ostatnie są najbardziej niebezpieczne, ponieważ występują po stronie klienta. Są więc wskaźnikiem kruchości.
Bez wątpienia wskaźnik jest względny. Ktoś bardzo dokładnie naprawia kod i prawdopodobieństwo jego awarii jest niewielkie, inni robią to w pośpiechu i niedbale. Jednak inny kod z tymi samymi użytkownikami może powodować różną liczbę błędów. Prawdopodobnie możemy powiedzieć, że im trudniej jest zrozumieć kod i polegać na czasie wykonywania programu, a nie na etapie kompilacji, tym bardziej kruchy jest kod.
Ponadto funkcjonalność, która nie będzie modyfikowana, często ulega awarii. Może ucierpieć z powodu wysokiego sprzężenia logiki różnych komponentów.
Rozważ konkretny przykład. Tutaj logika autoryzacji użytkownika z określoną rolą (zdefiniowaną jako parametr rolled) w celu uzyskania dostępu do określonego zasobu (zdefiniowanego jako resourceUri) znajduje się w metodzie statycznej.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Jak widać, logika jest skomplikowana. Oczywiste jest, że dodanie nowych ról i zasobów łatwo to zepsuje. W rezultacie określona rola może uzyskać lub utracić dostęp do zasobu. Utworzenie klasy Resource, która wewnętrznie przechowuje identyfikator zasobu i listę obsługiwanych ról, jak pokazano poniżej, zmniejszyłoby niestabilność.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} W tym przypadku, aby dodać nowe zasoby i role, nie trzeba wcale modyfikować kodu logiki autoryzacji, to znaczy, że tak naprawdę nie ma nic do złamania.
Co może pomóc w wyłapaniu błędów w czasie wykonywania? Odpowiedzią jest testowanie ręczne, automatyczne i jednostkowe. Im lepiej zorganizowany jest proces testowania, tym bardziej prawdopodobne jest, że delikatny kod pojawi się po stronie klienta.
Często kruchość jest tylną stroną innych identyfikatorów złego projektu, takich jak sztywność, słaba czytelność i niepotrzebne powtarzanie.
Wniosek
Próbowaliśmy nakreślić i opisać główne identyfikatory złego projektu. Niektóre z nich są współzależne. Musisz zrozumieć, że kwestia projektu nie zawsze nieuchronnie prowadzi do trudności. Wskazuje tylko, że mogą wystąpić. Im mniej tych identyfikatorów jest monitorowanych, tym mniejsze jest to prawdopodobieństwo.