Zacznijmy naszą podróż SQL, aby zrozumieć agregację danych w SQL i typy agregacji, w tym agregacje proste i przesuwne.
Zanim przejdziemy do agregacji, warto rozważyć ciekawe fakty, często pomijane przez niektórych programistów, jeśli chodzi o SQL w ogóle, a agregację w szczególności.
W tym artykule SQL odnosi się do T-SQL, który jest wersją SQL Microsoftu i ma więcej funkcji niż standardowy SQL.
Matematyka w SQL
Bardzo ważne jest, aby zrozumieć, że T-SQL opiera się na pewnych solidnych koncepcjach matematycznych, chociaż nie jest sztywnym językiem opartym na matematyce.
Zgodnie z książką „Microsoft_SQL_Server_2008_T_SQL_Fundamentals” autorstwa Itzika Ben-Gana, SQL jest przeznaczony do wykonywania zapytań i zarządzania danymi w systemie zarządzania relacyjnymi bazami danych (RDBMS).
Sam system zarządzania relacyjnymi bazami danych opiera się na dwóch solidnych gałęziach matematycznych:
- Teoria mnogości
- Logika predykatów
Teoria mnogości
Teoria mnogości, jak sama nazwa wskazuje, jest gałęzią matematyki zajmującą się zbiorami, którą można również nazwać zbiorami określonych, odrębnych obiektów.
Krótko mówiąc, w teorii mnogości myślimy o rzeczach lub obiektach jako całości w taki sam sposób, jak myślimy o pojedynczym przedmiocie.
Na przykład książka jest zbiorem wszystkich wyraźnie odrębnych książek, więc bierzemy książkę jako całość, co wystarczy, aby uzyskać szczegółowe informacje o wszystkich zawartych w niej książkach.
Logika predykatów
Logika predykatów to logika logiczna, która zwraca prawdę lub fałsz w zależności od warunku lub wartości zmiennych.
Logika predykatów może być użyta do wymuszenia reguł integralności (cena musi być większa niż 0,00) lub filtrowania danych (gdzie cena jest większa niż 10,00), jednak w kontekście T-SQL mamy trzy wartości logiczne:
- Prawda
- Fałsz
- Nieznany (pusty)
Można to zilustrować w następujący sposób:
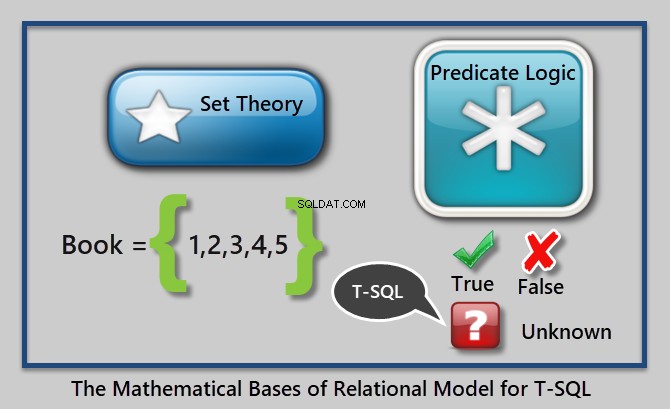
Przykładem predykatu jest „Gdzie cena książki jest większa niż 10,00”.
Tyle o matematyce, ale pamiętaj, że odniosę się do tego w dalszej części artykułu.
Dlaczego agregowanie danych w SQL jest łatwe
Agregacja danych w SQL w najprostszej formie polega na poznaniu sum za jednym razem.
Na przykład, jeśli mamy tabelę klientów, która zawiera listę wszystkich klientów wraz z ich danymi, to zagregowane dane tabeli klientów mogą dać nam całkowitą liczbę klientów, którą mamy.
Jak wspomniano wcześniej, myślimy o zestawie jako o pojedynczym elemencie, więc po prostu stosujemy funkcję agregującą do tabeli, aby uzyskać sumy.
Ponieważ SQL jest pierwotnie językiem opartym na zbiorach (jak omówiono wcześniej), więc stosunkowo łatwiej jest zastosować do niego funkcje agregujące w porównaniu z innymi językami.
Na przykład, jeśli mamy tabelę produktów, która zawiera rekordy wszystkich produktów w bazie danych, możemy od razu zastosować funkcję count do tabeli produktów, aby uzyskać całkowitą liczbę produktów, zamiast liczyć je jeden po drugim w pętli.
Przepis na agregację danych
Aby agregować dane w SQL, potrzebujemy co najmniej następujących rzeczy:
- Dane (tabela) z kolumnami, które po zagregowaniu mają sens
- Funkcja agregująca do zastosowania na danych
Przygotowywanie przykładowych danych (tabela)
Weźmy za przykład prostą tabelę zamówień, która zawiera trzy rzeczy (kolumny):
- Numer zamówienia (OrderId)
- Data złożenia zamówienia (OrderDate)
- Kwota zamówienia (TotalAmount)
Utwórzmy bazę danych AggregateSample, aby przejść dalej:
-- Create aggregate sample database CREATE DATABASE AggregateSample
Teraz utwórz tabelę zamówień w przykładowej bazie danych w następujący sposób:
-- Create order table in the aggregate sample database USE AggregateSample CREATE TABLE SimpleOrder (OrderId INT PRIMARY KEY IDENTITY(1,1), OrderDate DATETIME2, TotalAmount DECIMAL(10,2) )
Wypełnianie przykładowych danych
Wypełnij tabelę, dodając jeden wiersz:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ); GO
Spójrzmy teraz na tabelę:
-- View order table SELECT OrderId ,OrderDate ,TotalAmount FROM SimpleOrder
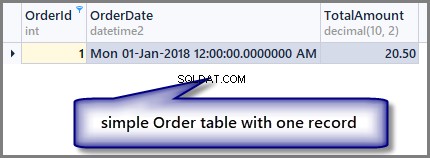
Pamiętaj, że w tym artykule używam dbForge Studio dla SQL Server, więc tylko wygląd wyjścia może się różnić, jeśli uruchomisz ten sam kod w SSMS (SQL Server Management Studio), nie ma różnicy, jeśli chodzi o skrypty i ich wyniki.
Podstawowe funkcje agregujące
Podstawowe funkcje agregujące, które można zastosować do tabeli, to:
- Suma
- Liczba
- Min
- Maks
- Średnia
Agregacja tabeli pojedynczych rekordów
Teraz interesujące pytanie brzmi:„czy możemy zagregować (zsumować lub zliczyć) dane (rekordy) w tabeli, jeśli ma ona tylko jeden wiersz, jak w naszym przypadku?” Odpowiedź brzmi „Tak”, możemy, chociaż nie ma to większego sensu, ale może nam pomóc zrozumieć, jak dane są przygotowywane do agregacji.
Aby uzyskać całkowitą liczbę zamówień, używamy funkcji count() z tabelą, jak omówiono wcześniej, możemy po prostu zastosować funkcję agregującą do tabeli, ponieważ SQL jest językiem opartym na zbiorach, a operacje można zastosować do zbioru bezpośrednio.
-- Getting total number of orders placed so far SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
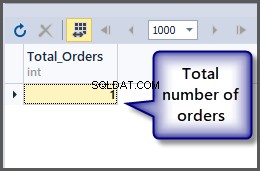
A teraz co z zamówieniem z minimalną, maksymalną i średnią kwotą dla pojedynczego rekordu:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
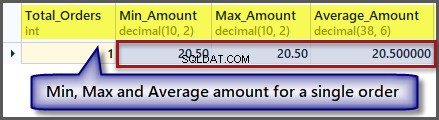
Jak widać z danych wyjściowych, minimalna, maksymalna i średnia kwota jest taka sama, jeśli mamy pojedynczy rekord, więc zastosowanie funkcji agregującej do pojedynczego rekordu jest możliwe, ale daje nam te same wyniki.
Aby zagregowane dane miały sens, potrzebujemy co najmniej więcej niż jednego rekordu.
Agregacja tabeli wielu rekordów
Dodajmy teraz cztery kolejne rekordy w następujący sposób:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ), ( '20180102' -- OrderDate - datetime2 ,30.50 -- TotalAmount - decimal(10, 2) ), ( '20180103' -- OrderDate - datetime2 ,10.50 -- TotalAmount - decimal(10, 2) ), ( '20180110' -- OrderDate - datetime2 ,100.50 -- TotalAmount - decimal(10, 2) ); GO
Tabela wygląda teraz następująco:
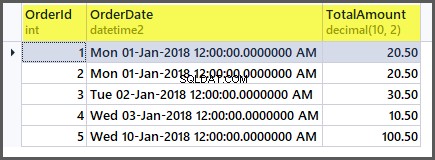
Jeśli teraz zastosujemy funkcje agregujące do tabeli, uzyskamy dobre wyniki:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
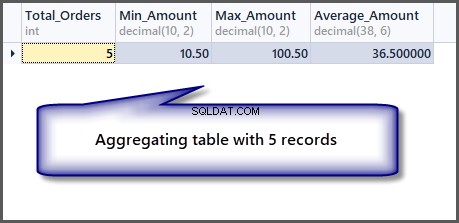
Grupowanie zagregowanych danych
Możemy pogrupować zagregowane dane według dowolnej kolumny lub zestawu kolumn, aby uzyskać dane zagregowane na podstawie tej kolumny.
Na przykład, jeśli chcemy poznać całkowitą liczbę zamówień na dzień, musimy pogrupować tabelę według daty, używając klauzuli Group by w następujący sposób:
-- Getting total orders per date SELECT OrderDate ,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate
Dane wyjściowe są następujące:
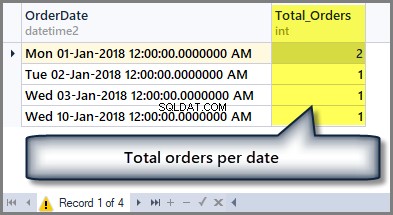
Jeśli więc chcemy zobaczyć suma wszystkich kwot zamówienia, możemy po prostu zastosować funkcję sum do kolumny całkowitej kwoty bez żadnego grupowania w następujący sposób:
-- Sum of all the orders amount SELECT SUM(TotalAmount) AS Sum_of_Orders_Amount FROM SimpleOrder
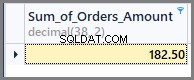
Aby uzyskać sumę zamówień na dzień, po prostu dodajemy grupowanie według daty do powyższego polecenia SQL w następujący sposób:
-- Sum of all the orders amount per date SELECT OrderDate ,SUM(TotalAmount) AS Sum_of_Orders FROM SimpleOrder GROUP BY OrderDate
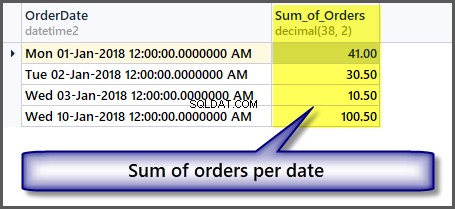
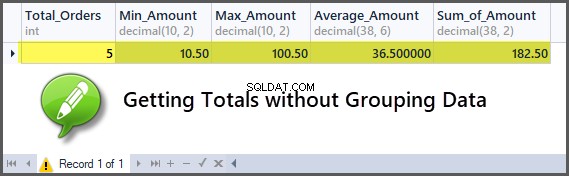
Pobieranie sum bez grupowania danych
Możemy od razu uzyskać sumy, takie jak suma zamówień, maksymalna kwota zamówienia, minimalna kwota zamówienia, suma zamówień, średnia kwota zamówienia bez konieczności grupowania, jeśli agregacja jest przeznaczona dla wszystkich tabel.
-- Getting order with minimum amount, maximum amount, average amount, sum of amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) AS Average_Amount ,SUM(TotalAmount) AS Sum_of_Amount FROM SimpleOrder
Dodawanie klientów do zamówień
Dodajmy trochę zabawy, dodając klientów do naszego stołu. Możemy to zrobić, tworząc kolejną tabelę klientów i przekazując identyfikator klienta do tabeli zamówień, jednak dla uproszczenia i udawania stylu hurtowni danych (gdzie tabele są zdenormalizowane) dodaję kolumnę nazwy klienta w tabeli zamówień w następujący sposób :
-- Adding CustomerName column and data to the order table ALTER TABLE SimpleOrder ADD CustomerName VARCHAR(40) NULL GO UPDATE SimpleOrder SET CustomerName = 'Eric' WHERE OrderId = 1 GO UPDATE SimpleOrder SET CustomerName = 'Sadaf' WHERE OrderId = 2 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 3 GO UPDATE SimpleOrder SET CustomerName = 'Asif' WHERE OrderId = 4 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 5 GO
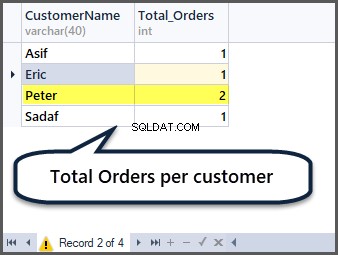
Uzyskiwanie łącznej liczby zamówień na klienta
Czy potrafisz teraz zgadnąć, jak uzyskać całkowitą liczbę zamówień na klienta? Musisz pogrupować według klienta (CustomerName) i zastosować funkcję agregującą count() do wszystkich rekordów w następujący sposób:
-- Total orders per customer
SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder
GROUP BY CustomerName
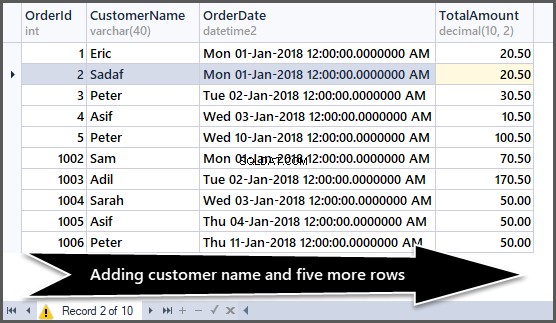
Dodawanie kolejnych pięciu rekordów do tabeli zamówień
Teraz dodamy pięć kolejnych wierszy do prostej tabeli kolejności w następujący sposób:
-- Adding 5 more records to order table
INSERT INTO SimpleOrder (OrderDate, TotalAmount, CustomerName)
VALUES
('01-Jan-2018', 70.50, 'Sam'),
('02-Jan-2018', 170.50, 'Adil'),
('03-Jan-2018',50.00,'Sarah'),
('04-Jan-2018',50.00,'Asif'),
('11-Jan-2018',50.00,'Peter')
GO
Spójrz teraz na dane:
-- Viewing order table after adding customer name and five more rows SELECT OrderId,CustomerName,OrderDate,TotalAmount FROM SimpleOrder GO
Uzyskiwanie łącznej liczby zamówień na klienta posortowanych według zamówień od maksymalnej do minimalnej
Jeśli interesuje Cię całkowita liczba zamówień na klienta posortowana według zamówień od maksymalnej do minimalnej, nie jest złym pomysłem rozbicie tego na mniejsze kroki w następujący sposób:
-- (1) Getting total orders SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
-- (2) Getting total orders per customer SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName
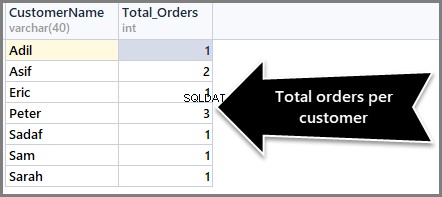
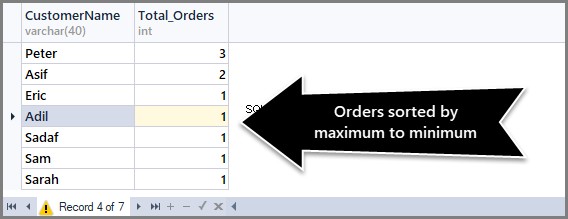
Aby posortować liczbę zamówień od maksimum do minimum, musimy użyć klauzuli Order By DESC (kolejność malejąca) z count() na końcu w następujący sposób:
-- (3) Getting total orders per customer from maximum to minimum orders SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName ORDER BY COUNT(*) DESC
Uzyskiwanie łącznej liczby zamówień według daty posortowanych najpierw według najnowszego zamówienia
Korzystając z powyższej metody, możemy teraz sprawdzić całkowitą liczbę zamówień według daty posortowaną najpierw według najnowszego zamówienia w następujący sposób:
-- Getting total orders per date from most recent first SELECT CAST(OrderDate AS DATE) AS OrderDate,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate ORDER BY OrderDate DESC
Funkcja CAST pomaga nam uzyskać tylko datę. Dane wyjściowe są następujące:
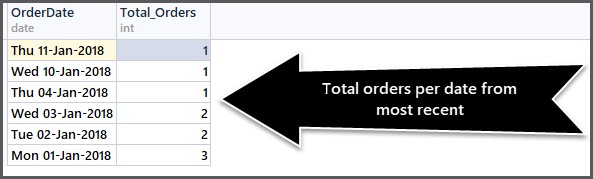
Możesz użyć tak wielu kombinacji, jak to tylko możliwe, o ile mają sens.
Uruchomione agregacje
Teraz, gdy znamy już zastosowanie funkcji agregujących do naszych danych, przejdźmy do zaawansowanej formy agregacji, a jedną z takich agregacji jest agregacja działająca.
Uruchamiane agregacje to agregacje stosowane do podzbioru danych, a nie do całego zestawu danych, co pomaga nam tworzyć małe okna danych.
Do tej pory widzieliśmy, że wszystkie funkcje agregujące są stosowane do wszystkich wierszy tabeli, które można pogrupować według jakiejś kolumny, takiej jak data zamówienia lub nazwa klienta, ale przy uruchomionych agregacjach mamy swobodę stosowania funkcji agregujących bez grupowania całości zbiór danych.
Oczywiście oznacza to, że możemy zastosować funkcję agregującą bez użycia klauzuli Group By, co jest nieco dziwne dla początkujących SQL (lub czasami niektórzy programiści to przeoczają), którzy nie są zaznajomieni z funkcjami okienkowania i uruchamianiem agregacji.
Windows na dane
Jak wspomniano wcześniej, działająca agregacja jest stosowana do podzbioru zestawu danych lub (innymi słowy) do małych okien danych.
Pomyśl o oknach jako zestawie(ach) w zestawie lub stole(ach) w tabeli. Dobrym przykładem okienkowania danych w naszym przypadku jest to, że mamy tabelę zamówień, która zawiera zamówienia złożone w różnych terminach, więc co jeśli każda data jest osobnym oknem, to możemy zastosować funkcje agregujące na każdym oknie w ten sam sposób, w jaki zastosowaliśmy stół.
Jeśli posortujemy tabelę zamówień (SimpleOrder) według daty zamówienia (OrderDate) w następujący sposób:
-- View order table sorted by order date
SELECT so.OrderId
,so.OrderDate
,so.TotalAmount
,so.CustomerName FROM SimpleOrder so
ORDER BY so.OrderDate
Windows na danych gotowych do uruchomienia agregacji można zobaczyć poniżej:

Możemy również rozważyć te okna lub podzbiory jako sześć mini tabel opartych na datach zamówień, a do każdej z tych mini tabel można zastosować agregaty.
Użycie partycji przez wewnątrz klauzuli OVER()
Uruchomione agregacje można zastosować, dzieląc tabelę na partycje za pomocą „Partycji według” wewnątrz klauzuli OVER().
Na przykład, jeśli chcemy podzielić tabelę kolejności według dat, na przykład każda data jest podtablicą lub oknem w zbiorze danych, musimy podzielić dane według daty zamówienia i można to osiągnąć za pomocą funkcji agregującej, takiej jak COUNT ( ) z OVER() i partycjonowaniem wewnątrz OVER() w następujący sposób:
-- Running Aggregation on Order table by partitioning by dates SELECT OrderDate, Total_Orders=COUNT(*) OVER(PARTITION BY OrderDate) FROM SimpleOrder

Pobieranie sum bieżących na datę (partycja)
Uruchamianie agregacji pomaga nam ograniczyć zakres agregacji tylko do zdefiniowanego okna i możemy uzyskać bieżące sumy na okno w następujący sposób:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per date window (partition by date) SELECT CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY OrderDate), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY OrderDate) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY OrderDate) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY OrderDate), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY OrderDate) FROM SimpleOrder
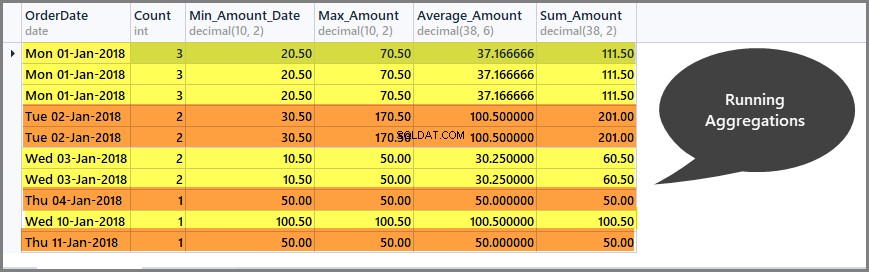
Uzyskiwanie sum bieżących na okno klienta (partycja)
Podobnie jak sumy bieżące na okno daty, możemy również obliczyć sumy bieżące na okno klienta, dzieląc zestaw zamówień (tabela) na podzbiory małych klientów (partycje) w następujący sposób:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per customer window (partition by customer) SELECT CustomerName, CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY CustomerName), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY CustomerName) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY CustomerName) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY CustomerName) FROM SimpleOrder ORDER BY Count DESC,OrderDate
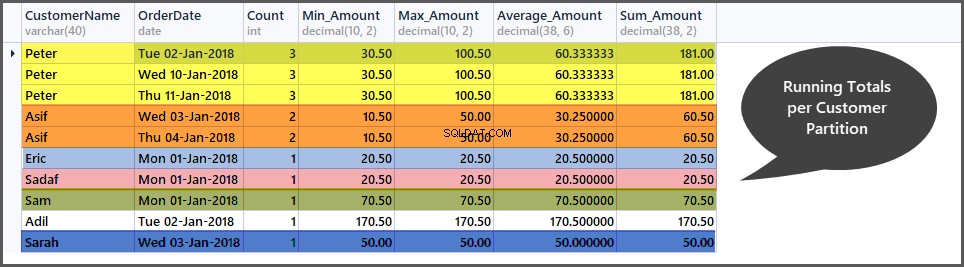
Agregacje przesuwne
Agregacje przesuwne to agregacje, które można zastosować do ramek w oknie, co oznacza dalsze zawężenie zakresu w oknie (partycji).
Innymi słowy, sumy bieżące dają nam sumy (suma, średnia, min, maks, liczba) dla całego okna (podzbioru), które tworzymy w tabeli, podczas gdy sumy przesuwne dają nam sumy (suma, średnia, min, maks, liczba) dla ramki (podzbioru podzbioru) w oknie (podzbioru) tabeli.
Na przykład, jeśli utworzymy okno na podstawie danych na podstawie (podział według klienta) klienta, to widzimy, że klient „Piotr” ma w swoim oknie trzy rekordy i wszystkie agregacje są stosowane do tych trzech rekordów. Teraz, jeśli chcemy utworzyć ramkę tylko dla dwóch wierszy na raz, oznacza to, że agregacja jest dalej zawężana, a następnie stosowana do pierwszego i drugiego wiersza, a następnie do drugiego i trzeciego i tak dalej.
Użycie WIERSZY POSTĘPUJĄCYCH z zamówieniem według wewnątrz klauzuli OVER()
Agregacje przesuwne można zastosować, dodając ROWS
Na przykład, jeśli chcemy agregować dane tylko dla dwóch wierszy na raz dla każdego klienta, musimy zastosować agregacje przesuwne do tabeli zamówień w następujący sposób:
-- Getting minimum amount, maximum amount, average amount per frame per customer window SELECT CustomerName, Min_Amount=Min(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING), Max_Amount=Max(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) FROM SimpleOrder so ORDER BY CustomerName
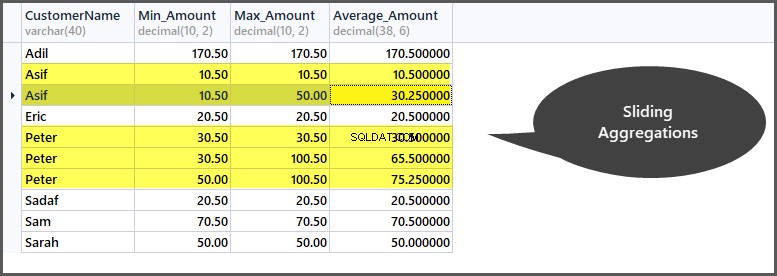
Aby zrozumieć, jak to działa, spójrzmy na oryginalny stół w kontekście ram i okien:
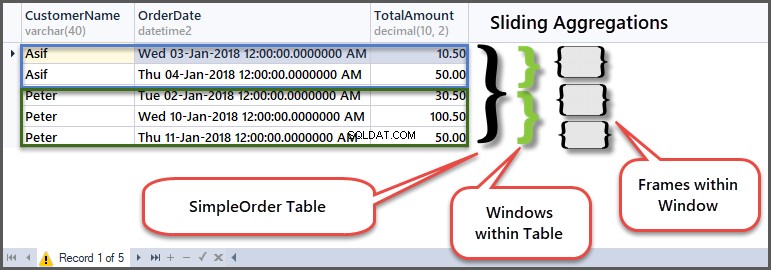
W pierwszym rzędzie okna klienta Piotr złożył zamówienie o wartości 30,50, ponieważ jest to początek ramki w oknie klienta, więc min i max są takie same, jak nie ma poprzedniego wiersza do porównania.
Następnie minimalna kwota pozostaje taka sama, ale maksymalna wynosi 100,50, ponieważ kwota poprzedniego wiersza (pierwszego wiersza) wynosi 30,50, a ta kwota wiersza to 100,50, więc maksymalna z dwóch wynosi 100,50.
Następnie, przechodząc do trzeciego rzędu, porównanie odbędzie się z drugim rzędem, więc minimalna ilość tych dwóch to 50,00, a maksymalna to 100,50.
Funkcja MDX od początku roku (YTD) i uruchomione agregacje
MDX to wielowymiarowy język wyrażeń używany do wykonywania zapytań o dane wielowymiarowe (takie jak kostka) i jest używany w rozwiązaniach Business Intelligence (BI).
Zgodnie z https://docs.microsoft.com/en-us/sql/mdx/ytd-mdx funkcja od roku do daty (YTD) w MDX działa w taki sam sposób, jak uruchamianie lub przesuwanie agregacji. Na przykład, YTD często używany w połączeniu bez dostarczonego parametru wyświetla bieżącą sumę do tej pory.
Oznacza to, że jeśli zastosujemy tę funkcję w roku, uzyskamy wszystkie dane roczne, ale jeśli przejdziemy do marca, otrzymamy wszystkie sumy od początku roku do marca i tak dalej.
Jest to bardzo przydatne w raportach SSRS.
Rzeczy do zrobienia
Otóż to! Po przejrzeniu tego artykułu jesteś gotowy do przeprowadzenia podstawowej analizy danych i możesz dalej doskonalić swoje umiejętności, wykonując następujące czynności:
- Spróbuj napisać działający skrypt agregujący, tworząc okna w innych kolumnach, takich jak Całkowita kwota.
- Spróbuj również napisać przesuwany skrypt agregujący, tworząc ramki w innych kolumnach, takich jak Całkowita kwota.
- Możesz dodać więcej kolumn i rekordów do tabeli (lub nawet więcej tabel), aby wypróbować inne kombinacje agregacji.
- Przykładowe skrypty wymienione w tym artykule można przekształcić w procedury składowane do wykorzystania w raportach SSRS za zbiorami danych.
Referencje:
- Od początku (MDX)
- dbForge Studio dla serwera SQL