Bardzo łatwo jest udowodnić, że następujące dwa wyrażenia dają dokładnie ten sam wynik:pierwszy dzień bieżącego miesiąca.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); Obliczenia zajmują mniej więcej tyle samo czasu:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
W moim systemie wykonanie obu partii zajęło około 175 sekund.
Dlaczego więc wolisz jedną metodę od drugiej? Kiedy jeden z nich naprawdę miesza w szacunkach kardynalności .
Na początek porównajmy te dwie wartości:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Pamiętaj, że rzeczywiste wartości przedstawione tutaj będą się zmieniać w zależności od tego, kiedy czytasz ten post – „dzisiaj” w komentarzu to 5 września 2013 r., czyli dzień, w którym ten post został napisany. Na przykład w październiku 2013 r. dane wyjściowe będą być 2013-10-01 i 1786-04-01 .)
Pomijając to, pozwól, że pokażę ci, co mam na myśli…
Reprodukcja
Stwórzmy bardzo prostą tabelę, zawierającą tylko zgrupowaną DATE kolumnę i załaduj 15 000 wierszy z wartością 1786-05-01 oraz 50 wierszy o wartości 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
A potem spójrzmy na rzeczywiste plany dla tych dwóch zapytań:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
Plany graficzne wyglądają dobrze:
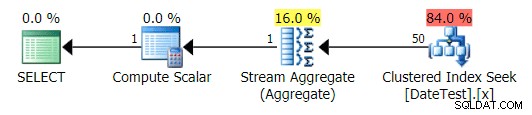
Plan graficzny dla DATEDIFF(MIESIĄC, 0, GETDATE()) zapytanie
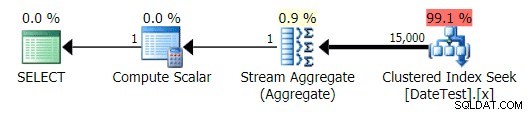
Plan graficzny dla DATEDIFF(MIESIĄC, GETDATE(), 0) zapytanie
Ale szacunkowe koszty są nie do zniesienia – zauważ, o ile wyższe są szacowane koszty dla pierwszego zapytania, które zwraca tylko 50 wierszy, w porównaniu z drugim zapytaniem, które zwraca 15 000 wierszy!

Siatka zestawień pokazująca szacunkowe koszty
A karta Top Operations pokazuje, że pierwsze zapytanie (szukając 2013-09-01 ) oszacował, że znalazłby 15 000 wierszy, podczas gdy w rzeczywistości znalazł tylko 50; drugie zapytanie pokazuje coś przeciwnego:spodziewano się znaleźć 50 wierszy pasujących do 1786-05-01 , ale znaleziono 15 000. Na podstawie niepoprawnych szacunków kardynalności, takich jak ta, jestem pewien, że możesz sobie wyobrazić, jaki drastyczny wpływ może to mieć na bardziej złożone zapytania dotyczące znacznie większych zestawów danych.
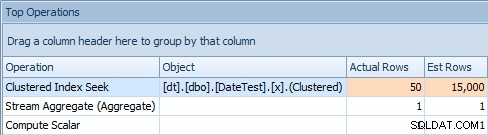
Karta Najważniejsze operacje dla pierwszego zapytania [DATEDIFF(MIESIĄC, 0, GETDATE())]
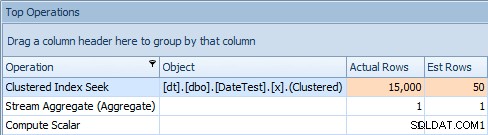
Karta Najważniejsze operacje dla drugiego zapytania [DATEDIFF(MIESIĄC, 0, GETDATE())]
Nieco inna odmiana zapytania, używająca innego wyrażenia do obliczenia początku miesiąca (wspomniana na początku postu), nie wykazuje tego objawu:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
Plan jest bardzo podobny do zapytania 1 powyżej i jeśli nie przyjrzysz się bliżej, pomyślisz, że te plany są równoważne:
Plan graficzny dla zapytania innego niż DATEDIFF
Kiedy jednak spojrzysz na kartę Najważniejsze operacje tutaj, zobaczysz, że oszacowanie jest super:
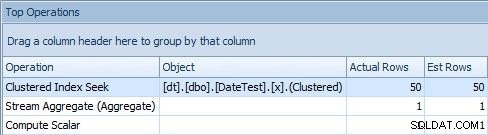
Karta Najważniejsze operacje z dokładnymi szacunkami
W przypadku tego konkretnego rozmiaru danych i zapytania wpływ na wydajność netto (w szczególności czas trwania i odczyty) jest w dużej mierze nieistotny. I ważne jest, aby pamiętać, że same zapytania nadal zwracają poprawne dane; po prostu szacunki są błędne (i mogą prowadzić do gorszego planu, niż przedstawiłem tutaj). To powiedziawszy, jeśli wyprowadzasz stałe za pomocą DATEDIFF w ten sposób w swoich zapytaniach naprawdę powinieneś przetestować ten wpływ w swoim środowisku.
Więc dlaczego tak się dzieje?
Mówiąc prościej, SQL Server ma DATEDIFF błąd polegający na zamianie drugiego i trzeciego argumentu podczas oceny wyrażenia pod kątem oszacowania kardynalności. Wydaje się, że obejmuje to ciągłe fałdowanie, przynajmniej obwodowo; w tym artykule w Books Online jest dużo więcej szczegółów na temat ciągłego składania, ale niestety artykuł nie ujawnia żadnych informacji na temat tego konkretnego błędu.
Jest poprawka – czy jest?
Istnieje artykuł w bazie wiedzy (KB #2481274), który twierdzi, że rozwiązuje ten problem, ale ma kilka własnych problemów:
- W artykule KB stwierdzono, że problem został rozwiązany w różnych dodatkach Service Pack lub aktualizacjach zbiorczych dla SQL Server 2005, 2008 i 2008 R2. Jednak symptom jest nadal obecny w gałęziach, które nie są tam wyraźnie wymienione, mimo że od czasu opublikowania artykułu widziały one wiele dodatkowych jednostek CU. Nadal mogę odtworzyć ten problem w SQL Server 2008 SP3 CU #8 (10.0.5828) i SQL Server 2012 SP1 CU #5 (11.0.3373).
- Pomija wspomnieć, że aby skorzystać z poprawki, należy włączyć flagę śledzenia 4199 (i „korzystać” ze wszystkich innych sposobów, w jakie określona flaga śledzenia może wpływać na optymalizator). O tym, że ta flaga śledzenia jest wymagana w przypadku poprawki, wspomniano w powiązanym elemencie Connect, #630583, ale te informacje nie powróciły do artykułu KB. Ani artykuł KB, ani element Connect nie dają żadnego wglądu w przyczynę (argumenty
DATEDIFFzostały zamienione podczas oceny). Na plus, uruchamiając powyższe zapytania z włączoną flagą śledzenia (przy użyciuOPTION (QUERYTRACEON 4199)) daje plany, które nie zawierają nieprawidłowego problemu z oszacowaniem.
- Sugeruje użycie dynamicznego SQL do obejścia tego problemu. W moich testach używam innego wyrażenia (takiego jak powyższe, które nie używa
DATEDIFF) przezwyciężyło ten problem w nowoczesnych kompilacjach zarówno SQL Server 2008, jak i SQL Server 2012. Rekomendowanie w tym przypadku dynamicznego SQL jest niepotrzebnie skomplikowane i prawdopodobnie przesadne, biorąc pod uwagę, że inne wyrażenie mogłoby rozwiązać problem. Ale jeśli miałbyś używać dynamicznego SQL, zrobiłbym to w ten sposób, a nie tak, jak zalecają w artykule z KB, co najważniejsze, aby zminimalizować ryzyko wstrzyknięcia SQL:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(I możesz dodać
OPTION (RECOMPILE)tam, w zależności od tego, jak SQL Server ma obsługiwać podsłuchiwanie parametrów.)Prowadzi to do tego samego planu, co wcześniejsze zapytanie, które nie używa
DATEDIFF, z odpowiednimi szacunkami i 99,1% kosztów w wyszukiwaniu indeksu klastrowego.Innym podejściem, które może cię kusić (a przez ciebie mam na myśli mnie, kiedy zaczynałem dochodzenie) jest użycie zmiennej do wcześniejszego obliczenia wartości:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
Problem z tym podejściem polega na tym, że przy zmiennej będziesz mieć stabilny plan, ale kardynalność będzie oparta na zgadywaniu (a rodzaj zgadywania będzie zależał od obecności lub braku statystyk). . W tym przypadku oto dane szacunkowe i rzeczywiste:
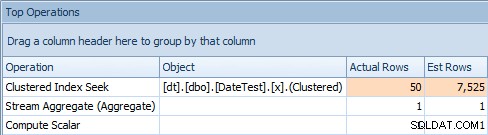
Karta Najważniejsze operacje dla zapytania używającego zmiennejTo wyraźnie nie w porządku; wygląda na to, że SQL Server odgadł, że zmienna pasuje do 50% wierszy w tabeli.
Serwer SQL 2014
Znalazłem nieco inny problem w SQL Server 2014. Pierwsze dwa zapytania są naprawione (przez zmiany w estymatorze liczności lub inne poprawki), co oznacza, że DATEDIFF argumenty nie są już przełączane. Tak!
Wydaje się jednak, że regresja została wprowadzona w celu obejścia użycia innego wyrażenia — teraz cierpi na niedokładne oszacowanie (oparte na tym samym 50% przypuszczeniu, co przy użyciu zmiennej). Oto zapytania, które przeprowadziłem:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Oto tabela zestawień porównująca szacunkowe koszty i rzeczywiste dane dotyczące czasu działania:
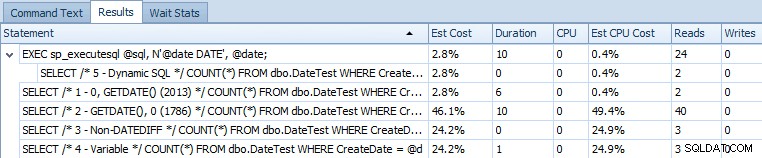
Szacowane koszty 5 przykładowych zapytań w SQL Server 2014
A oto ich szacunkowa i rzeczywista liczba wierszy (złożona za pomocą Photoshopa):

Szacowana i rzeczywista liczba wierszy dla 5 zapytań w programie SQL Server 2014
Z tych wyników jasno wynika, że wyrażenie, które wcześniej rozwiązywało problem, teraz wprowadziło inne. Nie jestem pewien, czy jest to objaw działania w CTP (np. coś, co zostanie naprawione), czy to naprawdę jest regresja.
W takim przypadku flaga śledzenia 4199 (samodzielna) nie ma żadnego wpływu; nowy estymator kardynalności domyśla się i po prostu nie jest poprawny. To, czy prowadzi to do rzeczywistego problemu z wydajnością, zależy w dużej mierze od wielu innych czynników wykraczających poza zakres tego postu.
Jeśli natkniesz się na ten problem, możesz – przynajmniej w obecnych CTP – przywrócić stare zachowanie za pomocą OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . Flaga śledzenia 9481 wyłącza nowy estymator kardynalności, jak opisano w tych informacjach o wydaniu (który z pewnością zniknie lub przynajmniej przesunie się w pewnym momencie). To z kolei przywraca prawidłowe szacunki dla wartości innych niż DATEDIFF wersji zapytania, ale niestety nadal nie rozwiązuje problemu polegającego na odgadywaniu na podstawie zmiennej (a użycie samego TF9481, bez TF4199, wymusza powrót dwóch pierwszych zapytań do starego zachowania wymiany argumentów).
Wniosek
Przyznam, że była to dla mnie ogromna niespodzianka. Podziękowania dla Martina Smitha i t-clausen.dk za wytrwanie i przekonanie mnie, że to prawdziwy, a nie wyimaginowany problem. Również wielkie podziękowania dla Paula White'a (@SQL_Kiwi), który pomógł mi zachować zdrowie psychiczne i przypomniał mi o rzeczach, których nie powinienem mówić. :-)
Nie będąc świadomym tego błędu, byłem nieugięty, że lepszy plan zapytania został wygenerowany po prostu przez zmianę tekstu zapytania, a nie przez konkretną zmianę. Jak się okazuje, czasami zmiana w zapytaniu, którą założysz nie zrobi różnicy, faktycznie będzie. Dlatego zalecam, aby jeśli masz podobne wzorce zapytań w swoim środowisku, przetestować je i upewnić się, że szacunki dotyczące kardynalności są prawidłowe. I zanotuj, aby przetestować je ponownie po aktualizacji.