FILESTREAM został wprowadzony przez firmę Microsoft w 2008 roku. Jego celem było efektywniejsze przechowywanie i zarządzanie plikami bez struktury. Przed wprowadzeniem FILESTREAM do przechowywania danych na serwerze SQL stosowano następujące metody:
- Pliki bez struktury mogą być przechowywane w kolumnie VARBINARY lub IMAGE tabeli SQL Server. Takie podejście jest skuteczne w utrzymaniu spójności transakcyjnej i zmniejsza złożoność zarządzania plikami, ale gdy aplikacja kliencka odczytuje dane z tabeli SQL, używa pamięci SQL, co prowadzi do słabej wydajności.
- Zamiast przechowywać cały plik w tabeli SQL, zapisz fizyczną lokalizację pliku bez struktury w tabeli SQL. Takie podejście daje ogromną poprawę wydajności, ale nie zapewnia spójności transakcyjnej, a zarządzanie plikami też było trudne.
Funkcja FILESTREAM jest bardzo skuteczna, ponieważ umożliwia przechowywanie plików BLOB w systemie plików NT i utrzymuje spójność transakcyjną. Gdy aplikacja kliencka odczytuje dane z kontenera FILESTREAM, zamiast korzystać z pamięci bufora SQL Server, używa pamięci podręcznej systemu Nthe T, co poprawia wydajność.
FILESTREAM nie jest typem danych. Jest to atrybut, który można przypisać do kolumny VARBINARY(MAX). Gdy kolumna VARBINARY(MAX) jest przypisana do atrybutu FILESTREAM, jest nazywana kolumną FILESTREAM. Dane przechowywane w kolumnie FILESTREAM będą przechowywane w systemie NT jako plik dyskowy, a wskaźnik pliku zostanie zapisany w tabeli. Kolumna VARBINARY(max) z przypisanym atrybutem FILESTREAM nie ma limitu przechowywania 2 GB w tabeli. Dzięki temu możemy przechowywać również ogromne pliki.
W tym artykule zademonstruję w następujący sposób:
- Jak włączyć funkcję FILESTREAM.
- Jak tworzyć i konfigurować grupy plików FILESTREAM i kontener danych FILESTREAM.
- Jak przechowywać i uzyskiwać dostęp do danych z tabel obsługujących FILESTREAM.
Demo:
W tym demo użyję:
- Serwer bazy danych :Serwer SQL 2017
- Oprogramowanie :Studio zarządzania serwerem SQL
- Baza danych :FileStream_Demo
Skonfiguruj dostęp FILESTREAM w bazie danych SQL Server
Aby skonfigurować FileStream w SQL Server, wprowadź następujące zmiany w SQL Server.
- Włącz funkcję FILESTREAM z SQL Server Configuration Manager.
- Włącz poziom dostępu FILESTREAM w instancji SQL Server.
- Utwórz grupę plików FILESTREAM i kontener FileStream do przechowywania danych BLOB.
Włącz funkcję FILESTREAM
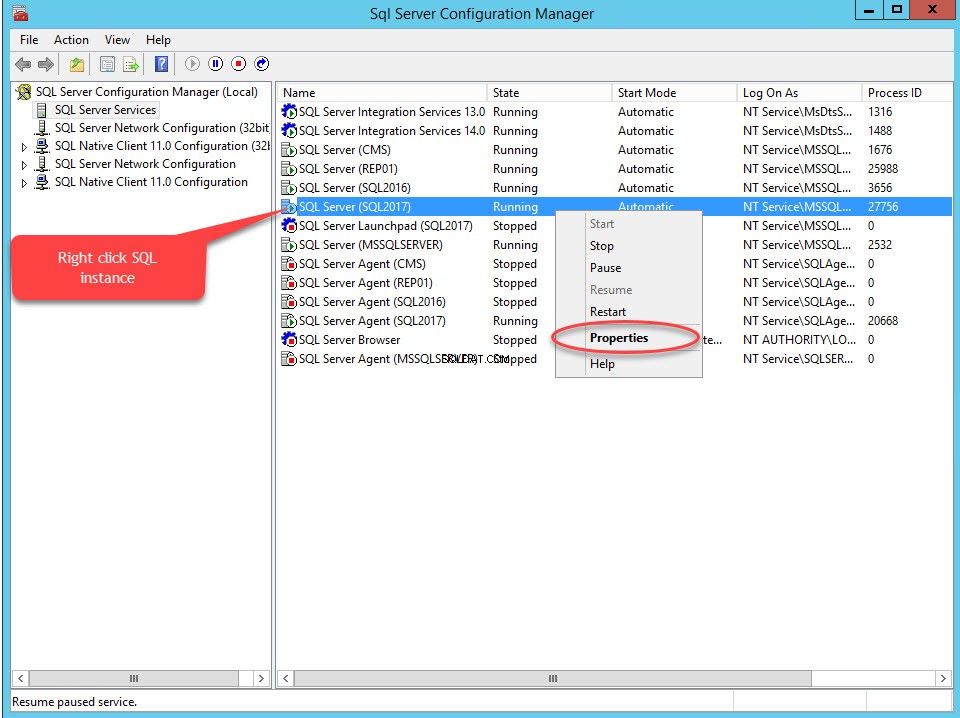
Aby włączyć FileStream w dowolnej bazie danych, najpierw włącz funkcję FileStream w instancji SQL Server. Aby to zrobić, otwórz Menedżera konfiguracji SQL Server, kliknij prawym przyciskiem myszy Instancję SQL, wybierz Właściwości , jak pokazano na poniższym obrazku:
Otworzy się okno dialogowe do konfiguracji właściwości serwera. Przełącz się na FILESTREAM patka. Wybierz Włącz FILESTREAM dla dostępu T-SQL . Wybierz Włącz FILESTREAM dla dostępu we/wy a następnie wybierz Zezwalaj klientowi na zdalny dostęp do danych FILESTREAM . W nazwa udziału Windows pole tekstowe, podaj nazwę katalogu do przechowywania plików. Zobacz następujący obraz:
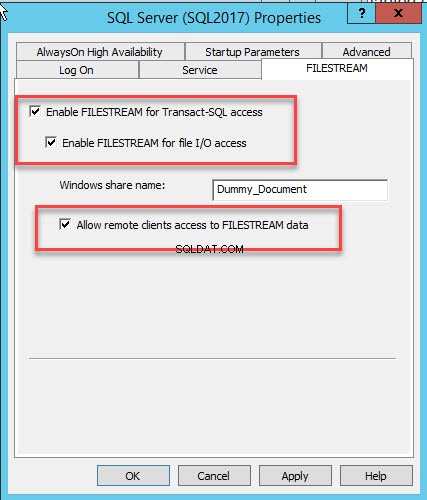
Kliknij OK i uruchom ponownie usługę SQL.
Włącz poziom dostępu FILESTREAM w instancji SQL Server
Po włączeniu funkcji FILESTREAM zmień poziom dostępu FILESTREAM. Aby zmienić poziom dostępu FileStream, wykonaj następujące zapytanie:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
W powyższym zapytaniu poniższe parametry są prawidłowymi wartościami:
0 oznacza obsługa FILESTREAM dla instancji SQL jest wyłączona.
1 oznacza obsługa FILESTREAM dla T-SQL jest włączona.
2 oznacza obsługa FILESTREAM dla dostępu strumieniowego T-SQL i Win32 jest włączona.
Poziom dostępu FILESTREAM można zmienić za pomocą programu SQL Server Management Studio. Aby to zrobić, kliknij prawym przyciskiem myszy połączenie SQL Server>> wybierz Właściwości>> W oknie dialogowym właściwości serwera wybierz Poziom dostępu do strumienia plików z listy rozwijanej i wybierz Włączony pełny dostęp , jak pokazano na poniższym obrazku:
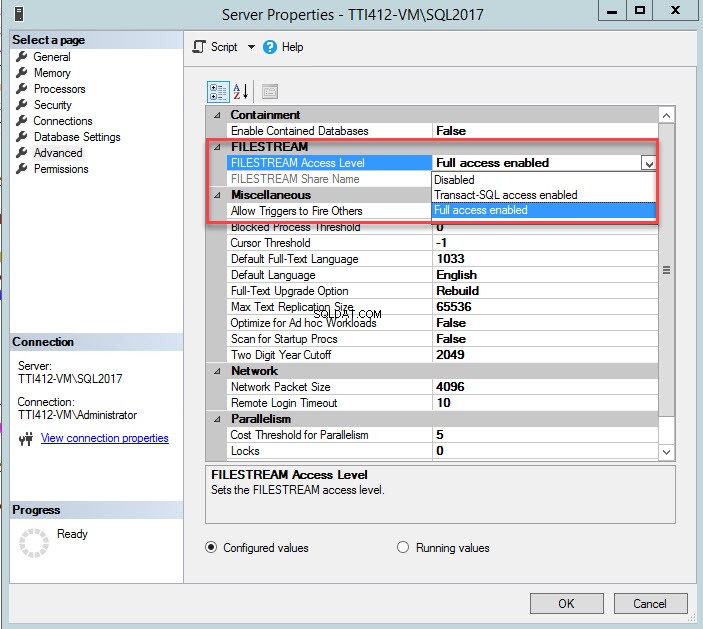
Po zmianie parametru uruchom ponownie usługi SQL Server.
Dodaj grupę plików FILESTREAM i pliki danych
Po włączeniu FILESTREAM dodaj grupę plików FILESTREAM i kontener FILESTREAM.
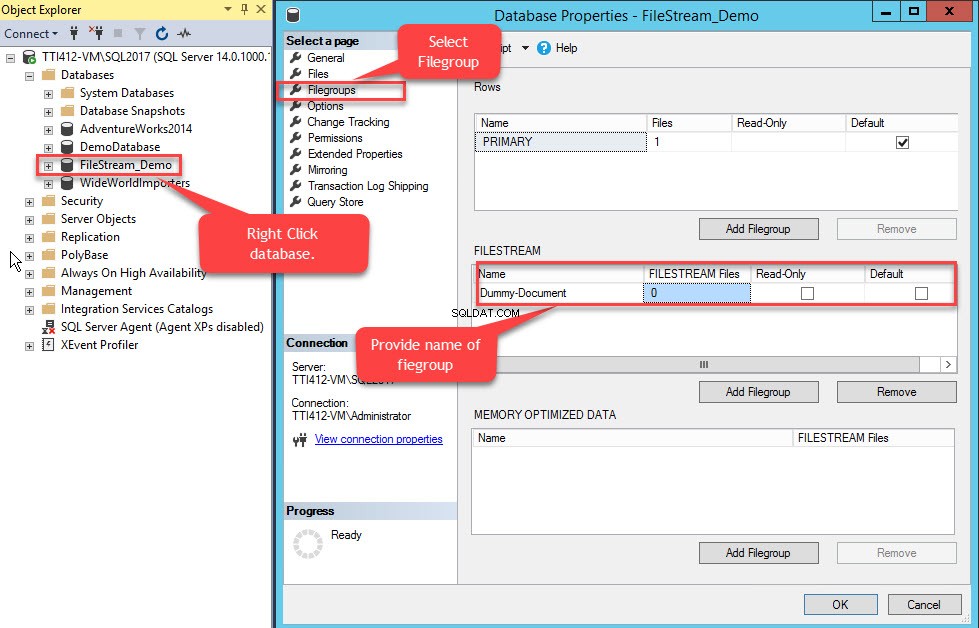
Aby to zrobić, kliknij prawym przyciskiem myszy FileStream-Demo baza danych>> wybierz Właściwości>> W lewym okienku Właściwości bazy danych w oknie dialogowym wybierz Grupy plików>> W siatce FILESTREAM kliknij Dodaj grupę plików przycisk>> Nazwij grupę plików jako Dokument fikcyjny . Zobacz następujący obraz:
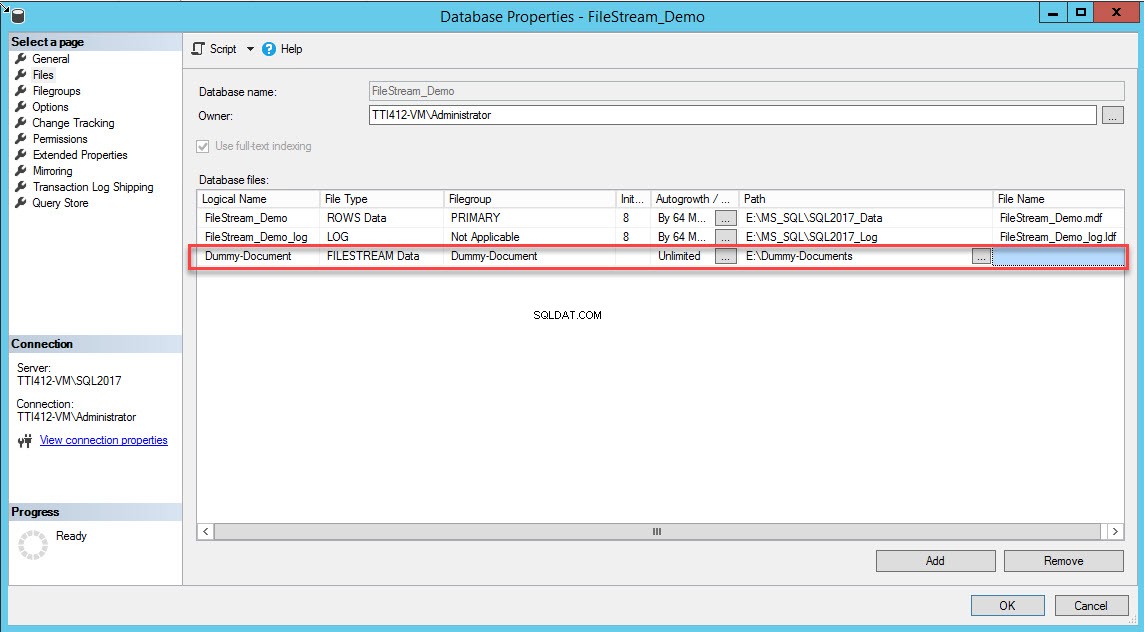
Po utworzeniu grupy plików w oknie dialogowym Właściwości bazy danych wybierz pliki i kliknij przycisk Dodaj. Włącza siatkę Pliki bazy danych. W kolumnie Nazwa logiczna podaj nazwę – Dokument fikcyjny . Wybierz dane FILESTREAM w Typie pliku upuścić pudło. Wybierz Dokument fikcyjny w grupie plików kolumna. Na ścieżce podaj lokalizację katalogu, w którym będą przechowywane pliki (E:\Dummy-Documents). Zobacz następujący obraz:
Alternatywnie możesz dodać grupę plików i kontenery FILESTREAM, wykonując następujące zapytanie T-SQL:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
Aby sprawdzić, czy kontener FileStream został utworzony, otwórz Eksplorator Windows i przejdź do katalogu „E:\Dummy-Document”.
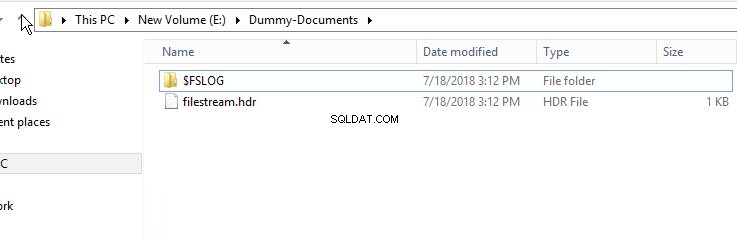
Jak pokazano na powyższym obrazku, katalog $FSLOG i filestream.hdr plik został utworzony. $FSLOG jest jak T-Log serwera SQL i filestream.hdr zawiera metadane FILESTREAM. Upewnij się, że nie zmieniasz ani nie edytujesz tych plików.
Przechowuj pliki w tabeli SQL
W tym demo utworzymy tabelę do przechowywania różnych plików z komputera. Tabela ma następujące kolumny:
- „Katalog główny ” do przechowywania lokalizacji pliku.
- „Nazwa pliku ” do przechowywania nazwy pliku.
- „Atrybut pliku ” kolumna do przechowywania atrybutu pliku (surowy/katalog.
- „Data utworzenia pliku ” do przechowywania czasu utworzenia pliku.
- „Rozmiar pliku ” do przechowywania rozmiaru pliku.
- „FileStreamCol ” do przechowywania zawartości pliku w formacie binarnym.
Utwórz tabelę SQL z kolumną FILESTREAM
Po skonfigurowaniu FILESTREAM utwórz tabelę SQL z kolumnami FILESTREAM, aby przechowywać różne pliki w tabeli serwera SQL. Jak wspomniałem powyżej, FILESTREAM nie jest typem danych. Jest to atrybut, który dodajemy do kolumny varbinary(max) w tabeli z włączoną funkcją FILESTREAM. Podczas tworzenia tabeli obsługującej technologię FILESTREAM pamiętaj, aby dodać UNIQUEIDENTIFIER kolumna, która ma ROWGUIDCOL i UNIKALNE atrybuty.
Wykonaj następujący skrypt, aby utworzyć tabelę z obsługą FILESTREAM:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Wstaw dane do tabeli
Mam plik WorldWide_Importors.xls dokument przechowywany na komputerze w lokalizacji „E:\Dokumenty”. Użyj OPENROWSET(Zbiorczo) aby załadować jego zawartość z dysku do VARBINARY(max) zmienny. Następnie zapisz zmienną w FileStreamCol (VARBINARY(max)) kolumna DummyDocumen t tabeli. Aby to zrobić, uruchom następujący skrypt:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Dostęp do danych FILESTREAM
Dostęp do danych FILESTREAM można uzyskać za pomocą T-SQL i zarządzanego interfejsu API. Gdy kolumna FILESTREAM uzyskana za pomocą zapytania T-SQL używa pamięci SQL do odczytania zawartości pliku danych i wysłania danych do aplikacji klienckiej. Gdy kolumna FILESTREAM jest dostępna przy użyciu interfejsu API zarządzanego Win32, nie używa pamięci programu SQL Server. Wykorzystuje możliwości przesyłania strumieniowego systemu plików NT, co zapewnia korzyści w zakresie wydajności.
Dostęp do danych FILESTREAM za pomocą T-SQL
Jak wspomniałem na początku artykułu, FILESTREAM jest atrybutem przypisanym do kolumny tabeli, która ma typ danych varbinary(max), dlatego można do niego uzyskać dostęp jak do każdej innej kolumny tabeli. Aby pobrać dane FILESTREAM wraz ze wszystkimi informacjami z tabeli, wykonaj poniższe zapytanie
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
Poniżej znajduje się wynik zapytania:

Jak pokazano na powyższym obrazku, dokument „WorldWide_Importors.xls” został przekonwertowany na obiekt BLOB, który jest przechowywany w kolumnie „FileStreamCol”.
Dostęp do danych FILESTREAM za pomocą zarządzanego interfejsu API
Chociaż dostęp do FILESTREAM przy użyciu Win32 API zapewnia wydajność i inne korzyści, ma inną i trudną składnię niż składnie T-SQL, co utrudnia dostęp do danych. Po pierwsze, aby zlokalizować plik w magazynie danych FILESTREAM, musimy zidentyfikować ścieżkę logiczną, aby jednoznacznie zidentyfikować plik w magazynie danych FILESTREAM. Możemy to zrobić za pomocą Pathname() metoda kolumny FILESTREAM. Wielkość liter jest rozróżniana.
Po pobraniu ścieżki do pliku, aby uzyskać dostęp, musimy uzyskać kontekst transakcji za pomocą Rozpocznij transakcję metoda. Po uzyskaniu kontekstu transakcji możemy uzyskać do niego dostęp za pomocą SQLFileStream klasa.
Poniższy kod uzyskuje lokalną ścieżkę do pliku WorldWide_Importors.xls dokument w magazynie danych FILESTREAM.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Wyjście zapytania:

Usuń pliki z kontenera FILESTREAM
Usuwanie plików jest proste. Aby usunąć plik z tabeli SQL z włączoną funkcją FILESTREAM, należy uruchomić zapytanie usuwające. Mimo że rekord został usunięty z tabel, plik będzie fizycznie dostępny w magazynie danych FILSTREAM. Zostanie usunięty przez Garbage Collector. Proces Garbage Collector jest wykonywany po wystąpieniu zdarzenia punktu kontrolnego. Podając wyraźny punkt kontrolny, możesz go usunąć natychmiast po usunięciu z tabeli.
Zapytanie o usunięcie plików z tabeli SQL:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Podsumowanie
W tym artykule omówiłem:
- Wprowadzenie FILESTREAM i jakie są korzyści.
- Jak włączyć funkcję FILESTREAM na instancji serwera SQL.
- Utwórz i skonfiguruj magazyn danych FILESTREAM i grupy plików.
- Wykonaj wstawianie i usuwanie plików z magazynu danych FILESTREAM.
W przyszłych artykułach wyjaśnię:
- Jak wykonać kopię zapasową i przywrócić bazę danych z obsługą FILESTREAM.
- Konfigurowanie replikacji i podziału tabel w tabelach FILESTREAM.
Bądź na bieżąco!