Relacyjny model zarządzania danymi został po raz pierwszy opracowany przez dr Edgara F. Codda w 1969 roku. Współczesne systemy zarządzania relacyjnymi bazami danych (RDBMS) są zgodne z paradygmatem. Kluczową strukturą identyfikowaną z RDBMS jest struktura logiczna zwana „tablicą”. Tabele składają się głównie z wierszy i kolumn (zwanych również rekordami i atrybutami lub krotkami i polami). W ścisłym sensie matematycznym termin tabela jest w rzeczywistości określany jako relacja i odpowiada terminowi „Model relacyjny”. W matematyce relacja jest reprezentacją zbioru.
Atrybut expression dobrze opisuje przeznaczenie kolumny – charakteryzuje zbiór skojarzonych z nią wierszy. Każda kolumna musi należeć do określonego typu danych, a każdy wiersz musi mieć pewne unikalne cechy identyfikujące zwane „kluczami”. Zmiana danych jest zazwyczaj bardziej wydajna, gdy jest wykonywana przy użyciu modelu relacyjnego, podczas gdy pobieranie danych może być szybsze w przypadku starszego modelu hierarchicznego, który został przedefiniowany w modelowych systemach NoSQL.
Normalizacja danych to matematyczny proces modelowania danych biznesowych do postaci, która zapewnia, że każda jednostka jest reprezentowana przez pojedynczą relację (tabelę). Pierwsi zwolennicy modelu relacyjnego zaproponowali koncepcję form normalnych. Edgar Codd zdefiniował pierwszą, drugą i trzecią formę normalną. Następnie dołączył do niego Raymond F. Boyce. Razem zdefiniowali normalną formę Boyce-Codd. Do tej pory teoretycznie zdefiniowano sześć form normalnych, ale w większości praktycznych zastosowań zwykle rozszerzamy normalizację do trzeciej formy normalnej. Każdy formularz normalny dąży do uniknięcia anomalii podczas modyfikacji danych, zmniejszenia nadmiarowości i zależności danych w tabeli. Każdy poziom normalizacji wprowadza więcej tabel, zmniejsza nadmiarowość, zwiększa prostotę każdej tabeli, ale także zwiększa złożoność całego systemu zarządzania relacyjnymi bazami danych. Tak więc strukturalnie systemy RDBM wydają się być bardziej złożone niż systemy hierarchiczne.
Dlaczego normalizacja bazy danych:cztery anomalie
Przechowywanie danych bez normalizacji powoduje szereg problemów z konsumpcją danych. Zwolennicy normalizacji nazywali takie problemy anomaliami. Aby opisać te anomalie, spójrzmy na dane przedstawione na rys. 1.

Rys. 1 stół dla pracowników
Lista 1. Podstawowa tabela demonstrująca normalizację bazy danych.
1.1. Utwórz tabelę
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Wstaw wiersze
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Zapytanie do tabeli
select * from staffers;
Ta tabela przedstawia zasadniczo dwa zestawy danych, które zostały przypadkowo połączone:nazwiska pracowników i działy. Zauważ, że wszyscy pracownicy są z tego samego działu:Inżynierii. Zrobiono to dla uproszczenia i zademonstrowania normalizacji. Istnieją trzy główne problemy związane z manipulowaniem tą strukturą:
Anomalia wstawiania
Aby wstawić nowy rekord, musimy ciągle powtarzać nazwy działów i kierowników.
Anomalia usunięcia
Aby usunąć dane pracownika, musimy również usunąć powiązanego kierownika i dział. Jeśli istnieje potrzeba usunięcia danych WSZYSTKICH pracowników, musimy również usunąć wszystkie działy i wszystkich menedżerów.
Anomalia aktualizacji
Jeśli istnieje potrzeba zmiany kierownika dowolnego działu, musimy dokonać zmiany w każdym wierszu tej tabeli, ponieważ wartości są zduplikowane dla każdego pracownika.
Normalne formularze bazy danych
W kolejnych częściach artykułu postaramy się opisać pierwszą, drugą i trzecią postać normalną, które są znacznie bardziej prawdopodobne w rzeczywistych systemach RDBM. Istnieją inne rozszerzenia teorii, takie jak czwarta, piąta i forma normalna Boyce-Codd, ale w tym artykule ograniczymy się do Trzech form normalnych.
Pierwsza forma normalna
Pierwsza forma normalna jest zdefiniowana przez cztery zasady:
Każda kolumna musi zawierać wartości tego samego typu danych.
Tabela Staffers już spełnia tę zasadę.
Każda kolumna w tabeli musi być niepodzielna.
Zasadniczo oznacza to, że należy dzielić zawartość kolumny, dopóki nie będzie można jej już dzielić. Zauważ, że Rola kolumna w Pracownicy tabela łamie regułę 2 dla wiersza z StaffID=3.
Każdy wiersz w tabeli musi być niepowtarzalny.
Wyjątkowość w znormalizowanych tabelach jest zazwyczaj osiągana przy użyciu kluczy podstawowych. Klucz podstawowy jednoznacznie definiuje każdy wiersz w tabeli. W większości przypadków klucz podstawowy jest definiowany tylko przez jedną kolumnę. Klucz główny składający się z więcej niż jednej kolumny nazywany jest kluczem złożonym.
Kolejność przechowywania rekordów nie ma znaczenia.
Aby wyrównać dane w Staffers tabela z założeniami pierwszej formy normalnej, musimy podzielić tabelę, jak pokazano na rysunkach 2, 3 i 4.
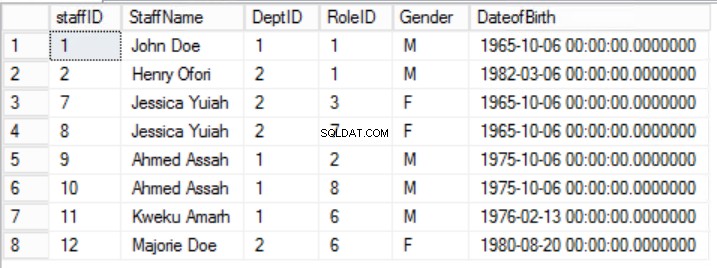
Rys. Stół dla 2 pracowników
Zawęziliśmy dane w Personelach tabeli i zaimplementowano złożony klucz podstawowy, aby zagwarantować unikalność. Stworzyliśmy również dwie dodatkowe tabele Role i Departamenty które mają relacje z głównymi pracownikami tabela zaimplementowana przy użyciu kluczy obcych. Przejrzyj DDL na liście 2.
Listing 2. DDL nowych pracowników Tabela dla pierwszej postaci normalnej.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
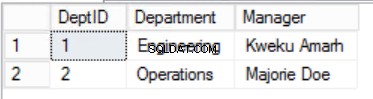
Rys. Tabela 3 działów
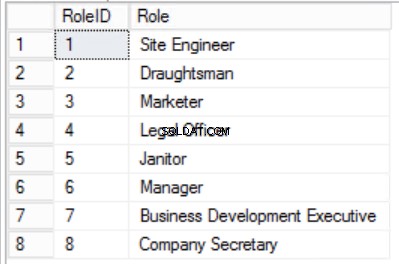
Rys. Tabela 4 ról
Druga forma normalna
Pierwszy formularz normalny musi już istnieć.
Każda kolumna niebędąca kluczem nie może mieć częściowej zależności od klucza podstawowego.
Ideą drugiej zasady jest to, że wszystkie kolumny tabeli muszą zależeć od wszystkich kolumn, które razem składają się na klucz podstawowy. Patrząc wstecz na tabele na rysunkach 2, 3 i 4, stwierdzamy, że osiągnęliśmy wszystkie wymagania pierwszej formy normalnej. Osiągnęliśmy również wymagania drugiej formy normalnej dla dwóch tabel Role i Departamenty . Jednak w przypadku personelu tabeli, nadal mamy problem. Nasz klucz podstawowy składa się z kolumn StaffID i RoleID.
Zasada 2 drugiej formy normalnej jest tutaj złamana przez fakt, że płeć i data urodzenia personelu nie zależą od identyfikatora roli. Istnieje częściowa zależność.
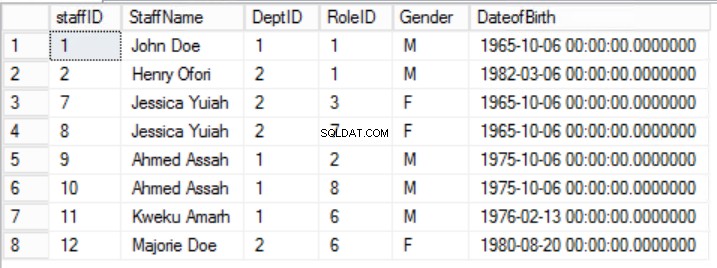
Rys. 5 pracowników do pierwszej formy normalnej
W podanym przykładzie możemy spróbować to naprawić, usuwając identyfikator roli z klucza podstawowego, ale jeśli to zrobimy, złamiemy inną zasadę:rolę unikalności podaną w pierwszej postaci normalnej. Musimy przyjąć inne podejście. Zmodyfikujemy personel tabeli ze zrozumieniem, że pracownik może odgrywać więcej niż jedną rolę. Patrz rys. 6.
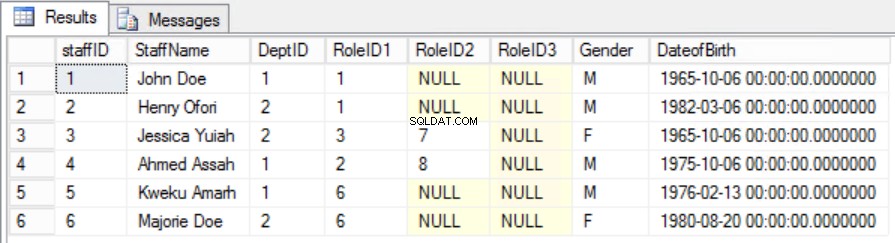
Rys. Tabela 6 sztabowych dla drugiej formy normalnej
Udało nam się zachować wyjątkowość, a także usunąć częściową zależność.
Listing 3. DDL nowej tabeli personelu dla drugiej postaci normalnej.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Trzecia forma normalna
Drugi formularz normalny musi już istnieć.
Każda kolumna niebędąca kluczem nie może mieć przejściowej zależności od klucza podstawowego.
Istotą trzeciej postaci normalnej jest to, że nie mogą istnieć żadne kolumny zależne od kolumn niekluczowych, nawet jeśli te kolumny niekluczowe już zależą od klucza podstawowego.
Przyjmijmy jako przykład, że zdecydowaliśmy się dodać dodatkową kolumnę do Pracowników tabeli, jak pokazano na rys. 7, aby wyraźnie zobaczyć kierownika personelu. W ten sposób złamalibyśmy drugą regułę trzeciej formy normalnej, ponieważ nazwa menedżera zależy od DeptID, a DeptID z kolei zależy od StaffID. To jest zależność przechodnia.
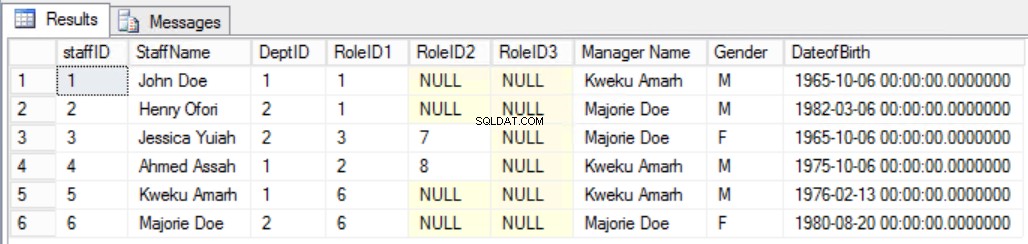
Rys. Tabela 7 pracowników dla trzeciej formy normalnej (złamana reguła)
Lepiej byłoby zachować stary formularz i wyświetlić wymagane informacje za pomocą połączenia między tabelą Staffers a tabelą Department.
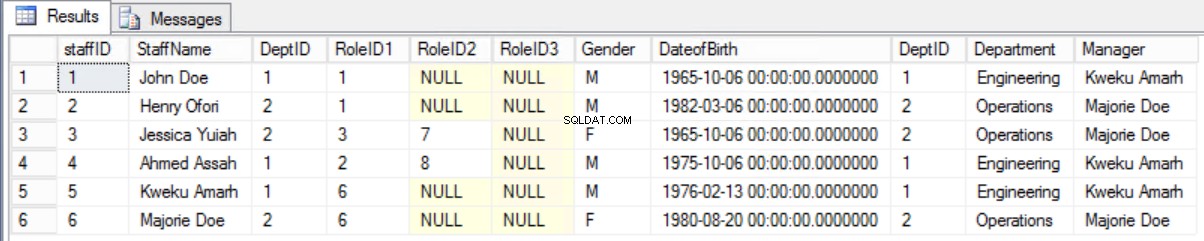
Rys. 8 Połącz personel z działem
Lista 4. Zapytanie do pracowników i menedżerów ds. ekspozycji.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Praktyczne zastosowanie
Większość dojrzałych aplikacji implementuje reguły normalizacji w rozsądnym zakresie. Widzimy, że implementacja normalizacji danych powoduje użycie ograniczeń klucza podstawowego i ograniczeń klucza obcego. Ponadto, gdy głębiej zagłębiamy się w temat, pojawiają się również takie problemy, jak indeksowanie kluczy obcych. Wcześniej wspomnieliśmy, jak brak normalizacji może wpłynąć na płynną manipulację danymi, jak opisano w anomaliach wstawiania, usuwania i aktualizacji. Brak odpowiedniej normalizacji może również pośrednio wpłynąć na wydajność zapytań.
Niedawno natknąłem się na tabelę, która miała postać pokazaną w tabeli 1, którą nazwiemy Customer_Accounts.
S/Nie | Nazwa | Konto_Nr | Nr telefonu |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Kowale Ernesta | 6677554897 | 2348022887546, 2348039988456 |
Tabela 1 Customer_Accounts
Głównym problemem związanym z tą tabelą jest to, że łamie ona drugą zasadę pierwszej postaci normalnej. W rezultacie w naszym przypadku wyszukiwanie klientów na podstawie ich numerów telefonów wymagało użycia LIKE w klauzuli WHERE i wiodącego %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
Wpływ powyższej konstrukcji polegał na tym, że optymalizator nigdy nie używał indeksu, co stanowiło ogromny problem z wydajnością.
Wniosek
Normalizacja danych leży w sferze projektowania baz danych i zarówno deweloperzy, jak i administratorzy baz danych powinni zwracać uwagę na zasady przedstawione w tym artykule. Zawsze lepiej jest wykonać normalizację, zanim baza danych przejdzie do produkcji. Korzyści z właściwie zaprojektowanego systemu zarządzania relacyjnymi bazami danych są po prostu warte wysiłku.