Wprowadzenie
Ostatnio napotkaliśmy interesujący problem z wydajnością jednej z naszych baz danych SQL Server, która przetwarza transakcje z dużą szybkością. Tabela transakcji używana do przechwytywania tych transakcji stała się tabelą gorącą. W rezultacie problem pojawił się w warstwie aplikacji. To był sporadyczny limit czasu sesji podczas próby zaksięgowania transakcji.
Stało się tak, ponieważ sesja zwykle „wstrzymywała” tabelę i powodowała serię fałszywych blokad w bazie danych.
Pierwszą reakcją typowego administratora bazy danych byłoby zidentyfikowanie podstawowej sesji blokującej i bezpieczne jej zakończenie. Było to bezpieczne, ponieważ zwykle było to polecenie SELECT lub sesja bezczynności.
Były też inne próby rozwiązania problemu:
- Oczyszczanie stołu. Oczekiwano, że zapewni to dobrą wydajność, nawet jeśli zapytanie musiało przeskanować całą tabelę.
- Włączanie poziomu izolacji ODCZYTAJ ZATWIERDZONEJ MIgawki w celu zmniejszenia wpływu sesji blokujących.
W tym artykule postaramy się odtworzyć uproszczoną wersję scenariusza i użyć jej do pokazania, jak proste indeksowanie może rozwiązać takie sytuacje, jeśli zostanie wykonane prawidłowo.
Dwie powiązane tabele
Spójrz na Listing 1 i Listing 2. Pokazują uproszczone wersje tabel biorących udział w rozważanym scenariuszu.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Listing 3 pokazuje wyzwalacz, który wstawia cztery wiersze do TranDetails tabela dla każdego wiersza wstawionego do TranLog tabela.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Dołącz do zapytania
Typowe jest znalezienie tabel transakcji obsługiwanych przez duże tabele. Celem jest przechowywanie znacznie starszych transakcji lub przechowywanie szczegółów rekordów podsumowanych w pierwszej tabeli. Pomyśl o tym jako o zamówieniu i szczegóły zamówienia tabele, które są typowe w przykładowych bazach danych SQL Server. W naszym przypadku rozważamy TranLog i Szczegóły Tran tabele.
W normalnych okolicznościach transakcje zapełniają te dwie tabele z biegiem czasu. Jeśli chodzi o raportowanie lub proste zapytania, zapytanie wykona sprzężenie w tych dwóch tabelach. To połączenie będzie wykorzystywać wspólną kolumnę między tabelami.
Najpierw wypełniamy tabelę za pomocą zapytania z Listingu 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
W naszym przykładzie wspólną kolumną używaną przez sprzężenie jest TranID kolumna:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Możesz zobaczyć dwa proste przykładowe zapytania, które używają sprzężenia do pobierania rekordów z TranLog i Szczegóły Tran .
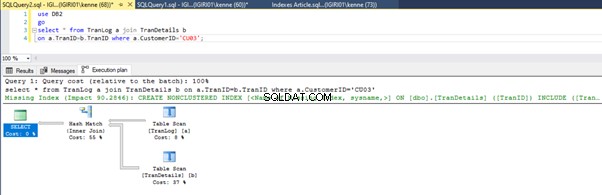
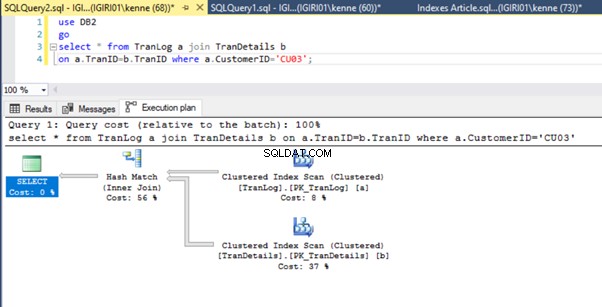
Gdy uruchamiamy zapytania z Listingu 5, w obu przypadkach musimy wykonać pełne skanowanie obu tabel (patrz Rysunki 1 i 2). Dominującą częścią każdego zapytania są operacje fizyczne. Oba są sprzężeniami wewnętrznymi. Listing 5a wykorzystuje jednak Hash Match dołącz, podczas gdy Listing 5b używa pętli zagnieżdżonej Przystąp. Uwaga:Listing 5a zwraca 4000 wierszy, podczas gdy Listing 4b zwraca 4 wiersze.
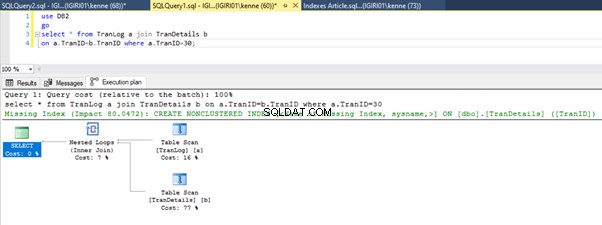
Trzy kroki dostrajania wydajności
Pierwszą optymalizacją, jaką robimy, jest wprowadzenie indeksu (dokładnie klucza podstawowego) w TranID kolumna TranLog tabela:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
Rysunki 3 i 4 pokazują, że SQL Server wykorzystuje ten indeks w obu zapytaniach, wykonując skanowanie z Listingu 5a i wyszukiwanie z Listingu 5b.
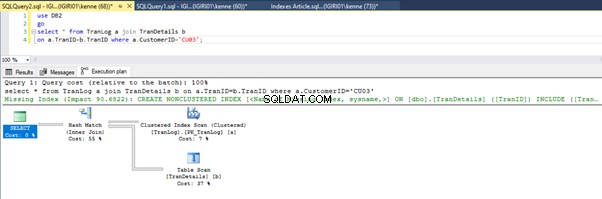
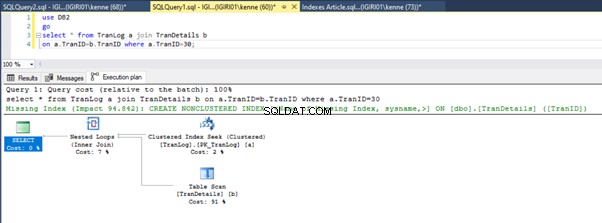
Wyszukiwanie indeksu znajduje się na listingu 5b. Dzieje się tak z powodu kolumny zaangażowanej w predykat klauzuli WHERE – TranID. To jest ta kolumna, do której zastosowaliśmy indeks.
Następnie wprowadzamy klucz obcy w TranID kolumna TranDetails tabela (Listing 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Niewiele to zmienia w planie realizacji. Sytuacja jest praktycznie taka sama, jak pokazano wcześniej na rysunkach 3 i 4.
Następnie wprowadzamy indeks w kolumnie klucza obcego:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
Ta czynność radykalnie zmienia plan wykonania z Listingu 5b (patrz Rysunek 6). Widzimy więcej prób indeksu. Zwróć także uwagę na wyszukiwanie RID na rysunku 6.
Wyszukiwania RID na stertach zwykle mają miejsce w przypadku braku klucza podstawowego. Sterta to tabela bez klucza podstawowego.
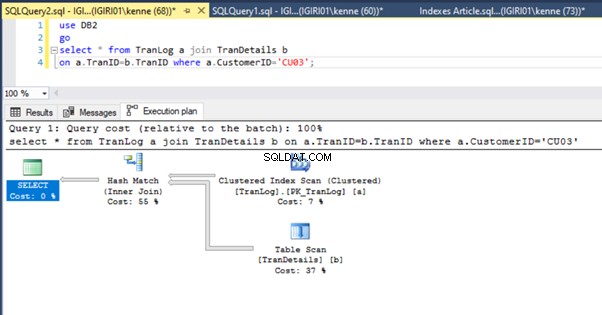
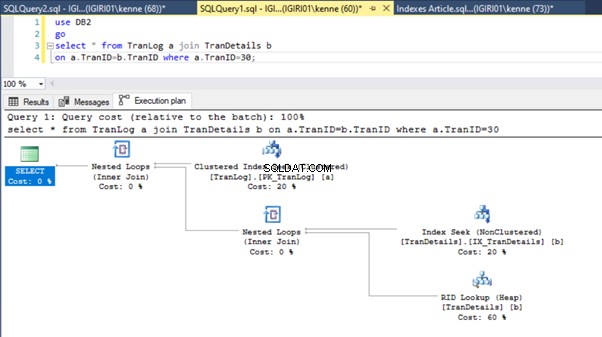
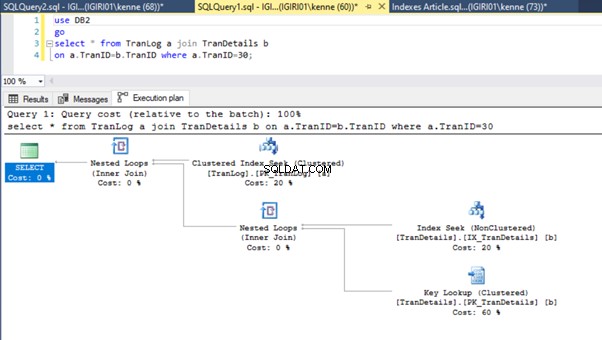
Na koniec dodajemy klucz podstawowy do TranDetails stół. Powoduje to usunięcie skanowania tabeli i wyszukiwania sterty RID odpowiednio z Listingów 5a i 5b (patrz rysunki 7 i 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Wniosek
Poprawa wydajności wprowadzona przez indeksy jest dobrze znana nawet początkującym DBA. Chcemy jednak zwrócić uwagę, że musisz dokładnie przyjrzeć się, w jaki sposób zapytania wykorzystują indeksy.
Ponadto pomysł polega na ustaleniu rozwiązania w konkretnym przypadku, w którym mamy zapytania łączące między Dziennikiem transakcji tabele i Szczegóły transakcji tabele.
Ogólnie rzecz biorąc, sensowne jest wymuszanie relacji między takimi tabelami za pomocą klucza i wprowadzenie indeksów do kolumn klucza podstawowego i obcego.
Tworząc aplikacje wykorzystujące taki projekt, programiści powinni pamiętać o wymaganych indeksach i relacjach na etapie projektowania. Nowoczesne narzędzia dla specjalistów SQL Server znacznie ułatwiają spełnienie tych wymagań. Możesz profilować swoje zapytania za pomocą specjalistycznego narzędzia Query Profiler. Jest to część wielofunkcyjnego profesjonalnego rozwiązania dbForge Studio dla SQL Server opracowanego przez Devart, aby uprościć życie DBA.