Prawdopodobnie popełniłeś niektóre z tych błędów, gdy zaczynałeś karierę projektanta baz danych. Może nadal je robisz, a może zrobisz je w przyszłości. Nie możemy cofnąć się w czasie i pomóc Ci naprawić błędy, ale możemy uchronić Cię przed przyszłymi (lub obecnymi) bólami głowy.
Przeczytanie tego artykułu może zaoszczędzić wiele godzin spędzonych na rozwiązywaniu problemów związanych z projektowaniem i kodem, więc zagłębimy się w szczegóły. Podzieliłem listę błędów na dwie główne grupy:te, które są nietechniczne w naturze i te, które są ściśle techniczne . Obie te grupy są ważną częścią projektowania baz danych.
Oczywiście, jeśli nie masz umiejętności technicznych, nie będziesz wiedział, jak coś zrobić. Nic dziwnego, że te błędy znajdują się na liście. Ale umiejętności nietechniczne? Ludzie mogą o nich zapomnieć, ale umiejętności te są również bardzo ważną częścią procesu projektowego. Dodają wartość do Twojego kodu i wiążą technologię z rzeczywistym problemem, który musisz rozwiązać.
Zacznijmy więc od kwestii nietechnicznych, a potem przejdźmy do technicznych.
Nietechniczne błędy projektowania bazy danych
#1 Złe planowanie
Jest to zdecydowanie problem nietechniczny, ale jest to poważny i powszechny problem. Wszyscy jesteśmy podekscytowani, gdy zaczyna się nowy projekt i wchodząc w to wszystko wygląda świetnie. Na początku projekt jest wciąż pustą stroną, a Ty i Twój klient jesteście szczęśliwi mogąc rozpocząć pracę nad czymś, co stworzy lepszą przyszłość dla Was obojga. To wszystko jest wspaniałe, a ostatecznym rezultatem będzie prawdopodobnie wspaniała przyszłość. Ale nadal musimy się skupić. To ta część projektu, w której możemy popełnić kluczowe błędy.
Zanim usiądziesz do rysowania modelu danych, upewnij się, że:
- Jesteś w pełni świadomy tego, co robi Twój klient (tj. jego biznesplany związane z tym projektem, a także jego ogólny obraz) i co chce osiągnąć dzięki temu projektowi teraz i w przyszłości.
- Zrozumiesz proces biznesowy i, jeśli zajdzie taka potrzeba, jesteś gotowy zasugerować jego uproszczenie i ulepszenie (np. zwiększenie wydajności i dochodów, zmniejszenie kosztów i godzin pracy itp.).
- Zrozumiesz przepływ danych w firmie klienta. Najlepiej byłoby, gdybyś znał każdy szczegół:kto pracuje z danymi, kto wprowadza zmiany, jakie raporty są potrzebne, kiedy i dlaczego to wszystko się dzieje.
- Możesz użyć języka/terminologii używanej przez Twojego klienta. Chociaż możesz być ekspertem w swojej dziedzinie lub nie, Twój klient na pewno nim jest. Poproś ich, aby wyjaśnili, czego nie rozumiesz. A kiedy wyjaśniasz klientowi szczegóły techniczne, użyj języka i terminologii, którą rozumie.
- Wiesz, jakich technologii będziesz używać, od silnika bazy danych i języków programowania po inne narzędzia. To, z czego zdecydujesz się skorzystać, jest ściśle związane z problemem, który rozwiążesz, ale ważne jest, aby uwzględnić preferencje klienta i jego aktualną infrastrukturę IT.
W fazie planowania powinieneś uzyskać odpowiedzi na następujące pytania:
- Które tabele będą głównymi tabelami w Twoim modelu? Prawdopodobnie będziesz mieć ich kilka, podczas gdy pozostałe tabele będą zwykłymi (np. user_account, role). Nie zapomnij o słownikach i relacjach między tabelami.
- Jakie nazwy będą używane dla tabel w modelu? Pamiętaj, aby terminologia była podobna do tej, której aktualnie używa klient.
- Jakie reguły będą obowiązywać podczas nadawania nazw tabelom i innym obiektom? (Zobacz punkt 4 o konwencjach nazewnictwa.)
- Jak długo potrwa cały projekt? Jest to ważne zarówno dla Twojego harmonogramu, jak i harmonogramu klienta.
Dopiero gdy masz wszystkie te odpowiedzi, jesteś gotowy, aby podzielić się wstępnym rozwiązaniem problemu. To rozwiązanie nie musi być kompletną aplikacją – może krótkim dokumentem lub nawet kilkoma zdaniami w języku biznesu klienta.
Dobre planowanie nie dotyczy tylko modelowania danych; ma zastosowanie do prawie każdego projektu informatycznego (i nie-IT). Pomijanie jest opcją tylko wtedy, gdy 1) masz naprawdę mały projekt; 2) zadania i cele są jasne i 3) naprawdę się spieszysz. Historycznym przykładem jest Sputnik 1, który inżynierowie uruchamiający Sputnik 1 udzielają ustnych instrukcji technikom, którzy go montowali. Projekt był w pośpiechu z powodu wiadomości, że Stany Zjednoczone planują wkrótce wystrzelić własnego satelitę – ale myślę, że nie będziesz się tak spieszyć.
#2 Niewystarczająca komunikacja z klientami i programistami
Kiedy rozpoczniesz proces projektowania bazy danych, prawdopodobnie zrozumiesz większość głównych wymagań. Niektóre są bardzo powszechne niezależnie od branży, np. role i statusy użytkowników. Z drugiej strony niektóre tabele w twoim modelu będą dość specyficzne. Na przykład, jeśli budujesz model dla firmy taksówkowej, będziesz mieć stoły dla pojazdów, kierowców, klientów itp.
Jednak nie wszystko będzie oczywiste na początku projektu. Możesz źle zrozumieć niektóre wymagania, klient może dodać nowe funkcjonalności, zobaczysz coś, co można zrobić inaczej, proces może się zmienić itp. Wszystko to powoduje zmiany w modelu. Większość zmian wymaga dodania nowych tabel, ale czasami będziesz usuwać lub modyfikować tabele. Jeśli zacząłeś już pisać kod, który używa tych tabel, będziesz musiał również przepisać ten kod.
Aby skrócić czas spędzany na nieoczekiwanych zmianach, należy:
- Rozmawiaj z programistami i klientami i nie bój się zadawać ważnych pytań biznesowych. Kiedy uznasz, że jesteś gotowy, aby zacząć, zadaj sobie pytanie, Czy sytuacja X jest uwzględniona w naszej bazie danych? Klient obecnie robi Y w ten sposób; czy spodziewamy się zmiany w najbliższej przyszłości? Gdy jesteśmy pewni, że nasz model jest w stanie przechowywać wszystko, czego potrzebujemy we właściwy sposób, możemy zacząć kodować.
- Jeśli napotkasz poważną zmianę w swoim projekcie i masz już napisany dużo kodu, nie powinieneś próbować szybkiej naprawy. Zrób to tak, jak powinno być zrobione, bez względu na obecną sytuację. Szybka naprawa może teraz zaoszczędzić trochę czasu i prawdopodobnie przez jakiś czas będzie działała dobrze, ale później może zmienić się w prawdziwy koszmar.
- Jeśli uważasz, że coś jest teraz w porządku, ale może stać się problemem później, nie ignoruj tego. Przeanalizuj ten obszar i wprowadź zmiany, jeśli poprawią jakość i wydajność systemu. Będzie to kosztować trochę czasu, ale dostarczysz lepszy produkt i będziesz spać znacznie lepiej.
Jeśli spróbujesz uniknąć wprowadzania zmian w modelu danych, gdy zobaczysz potencjalny problem — lub jeśli zdecydujesz się na szybką naprawę zamiast robić to prawidłowo — prędzej czy później za to zapłacisz.
Pozostań w kontakcie z klientem i programistami przez cały czas trwania projektu. Zawsze sprawdzaj i sprawdzaj, czy od ostatniej dyskusji zostały wprowadzone jakieś zmiany.
#3 Słaba lub brakująca dokumentacja
Dla większości z nas dokumentacja pojawia się pod koniec projektu. Jeśli jesteśmy dobrze zorganizowani, prawdopodobnie udokumentowaliśmy wszystko po drodze i będziemy musieli tylko wszystko podsumować. Ale szczerze mówiąc, zwykle tak nie jest. Pisanie dokumentacji ma miejsce tuż przed zamknięciem projektu — i zaraz po tym, jak mentalnie skończymy z tym modelem danych!
Cena zapłacona za słabo udokumentowany projekt może być dość wysoka, kilka razy wyższa niż cena, jaką płacimy za prawidłowe udokumentowanie wszystkiego. Wyobraź sobie, że znalazłeś błąd kilka miesięcy po zamknięciu projektu. Ponieważ nie sporządziłeś odpowiedniej dokumentacji, nie wiesz, od czego zacząć.
Podczas pracy nie zapomnij pisać komentarzy. Wyjaśnij wszystko, co wymaga dodatkowych wyjaśnień, i po prostu zapisz wszystko, co uważasz za przydatne pewnego dnia. Nigdy nie wiesz, czy i kiedy będziesz potrzebować tych dodatkowych informacji.
Techniczne błędy w projektowaniu bazy danych
#4 Nieużywanie konwencji nazewnictwa
Nigdy nie wiadomo na pewno, jak długo potrwa projekt i czy nad modelem danych będzie pracować więcej niż jedna osoba. Jest moment, w którym jesteś naprawdę blisko modelu danych, ale jeszcze go nie zacząłeś rysować. Wtedy warto zdecydować, jak będziesz nazywać obiekty w swoim modelu, w bazie danych i w ogólnej aplikacji. Przed modelowaniem powinieneś wiedzieć:
- Czy nazwy tabel są w liczbie pojedynczej czy mnogiej?
- Czy pogrupujemy tabele według nazw? (Np. wszystkie tabele związane z klientem zawierają „client_”, wszystkie tabele związane z zadaniami zawierają „task_” itp.)
- Czy użyjemy wielkich i małych liter, czy tylko małych?
- Jakiej nazwy będziemy używać dla kolumn ID? (Najprawdopodobniej będzie to „id”.)
- Jak nazwiemy klucze obce? (Najprawdopodobniej „id_” i nazwa wskazanej tabeli.)
Porównaj część modelu, który nie używa konwencji nazewnictwa z tą samą częścią, która używa konwencji nazewnictwa, jak pokazano poniżej:
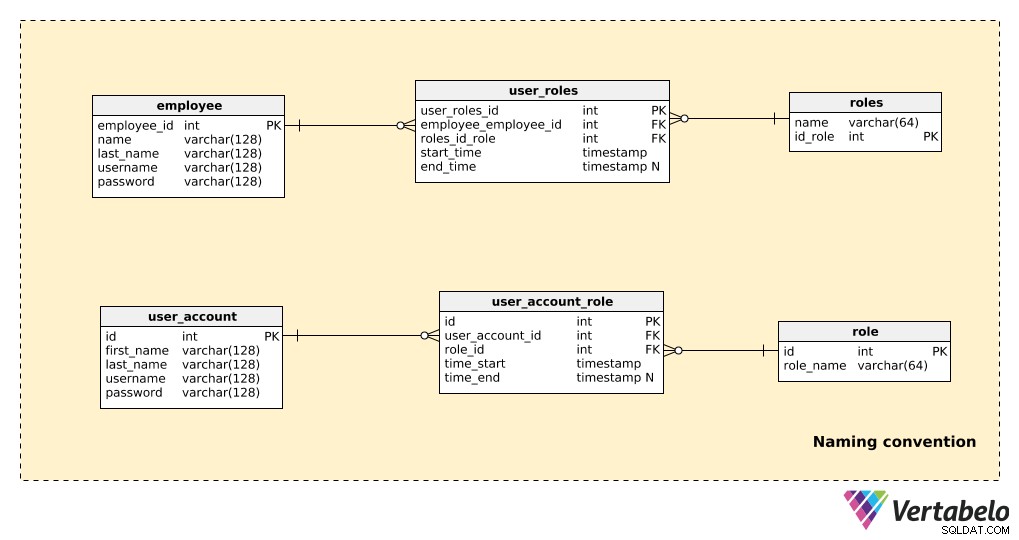
Jest tu tylko kilka tabel, ale nadal jest dość oczywiste, który model jest łatwiejszy do odczytania. Zauważ, że:
- Oba modele „działają”, więc nie ma problemów od strony technicznej.
- W przykładzie bez konwencji nazewnictwa (trzy górne tabele) jest kilka rzeczy, które znacząco wpływają na czytelność:używanie w nazwach tabel zarówno liczby pojedynczej, jak i mnogiej; niestandardowe nazwy kluczy podstawowych (
employees_id,id_role); i atrybuty w różnych tabelach mają tę samą nazwę (np. imię i nazwisko pojawia się zarówno w „employee” i „roles” tabele).
A teraz wyobraź sobie, jaki bałagan stworzylibyśmy, gdyby nasz model zawierał setki tabel. Może moglibyśmy pracować z takim modelem (jeśli sami go stworzyliśmy), ale sprawilibyśmy, że ktoś miałby pecha, gdyby musiał nad nim pracować po nas.
Aby uniknąć przyszłych problemów z nazwami, nie używaj w nich słów zastrzeżonych SQL, znaków specjalnych ani spacji.
Tak więc, zanim zaczniesz tworzyć jakiekolwiek nazwy, stwórz prosty dokument (może mieć tylko kilka stron), który opisuje konwencję nazewnictwa, której użyłeś. Zwiększy to czytelność całego modelu i uprości przyszłą pracę.
Możesz przeczytać więcej o konwencjach nazewnictwa w tych dwóch artykułach:
- Konwencje nazewnictwa w modelowaniu baz danych
- Nieemocjonalne logiczne spojrzenie na konwencje nazewnictwa SQL Server
#5 Problemy z normalizacją
Normalizacja jest istotną częścią projektowania bazy danych. Każda baza danych powinna być znormalizowana do co najmniej 3NF (klucze podstawowe są zdefiniowane, kolumny są niepodzielne i nie ma powtarzających się grup, zależności częściowych ani zależności przechodnich). Zmniejsza to powielanie danych i zapewnia integralność referencyjną.
Więcej o normalizacji przeczytasz w tym artykule. Krótko mówiąc, ilekroć mówimy o modelu relacyjnej bazy danych, mamy na myśli znormalizowaną bazę danych. Jeśli baza danych nie jest znormalizowana, napotkamy szereg problemów związanych z integralnością danych.
W niektórych przypadkach możemy chcieć zdenormalizować naszą bazę danych. Jeśli to zrobisz, masz naprawdę dobry powód. Możesz przeczytać więcej o denormalizacji bazy danych tutaj.
#6 Korzystanie z modelu Entity-Atrybut-Wartość (EAV)
EAV oznacza wartość atrybutu podmiotu. Ta struktura może służyć do przechowywania dodatkowych danych o wszystkim w naszym modelu. Rzućmy okiem na jeden przykład.
Załóżmy, że chcemy przechowywać dodatkowe atrybuty klienta. „customer ” to nasza jednostka, „attribute ” to oczywiście nasz atrybut, a „attribute_value ” tabela zawiera wartość tego atrybutu dla tego klienta.
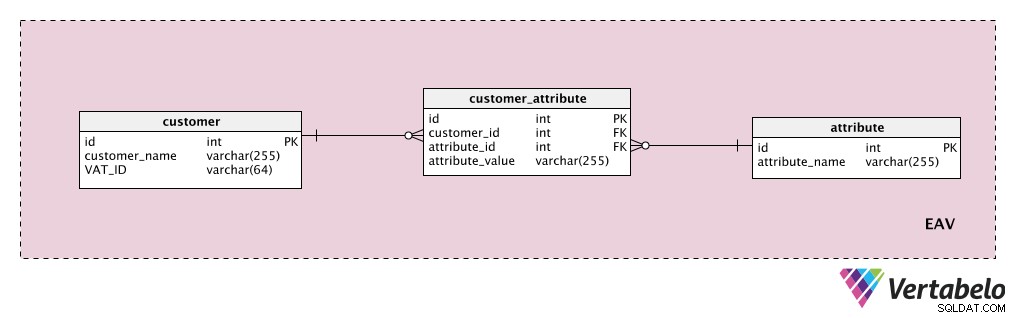
Najpierw dodamy słownik z listą wszystkich możliwych właściwości, które moglibyśmy przypisać klientowi. To jest „attribute " stół. Może zawierać właściwości, takie jak „wartość klienta”, „dane kontaktowe”, „dodatkowe informacje” itp. „customer_attribute Tabela zawiera listę wszystkich atrybutów wraz z wartościami dla każdego klienta. Dla każdego klienta będziemy mieć rekordy tylko dla posiadanych przez niego atrybutów i będziemy przechowywać „attribute_value ” dla tego atrybutu.
To może wydawać się naprawdę świetne. Umożliwiłoby nam to łatwe dodawanie nowych właściwości (ponieważ dodajemy je jako wartości w „customer_attribute " stół). W ten sposób uniknęlibyśmy wprowadzania zmian w bazie danych. Prawie zbyt piękne, aby mogło być prawdziwe.
I jest za dobry. Podczas gdy model będzie przechowywać potrzebne nam dane, praca z takimi danymi jest znacznie bardziej skomplikowana. Obejmuje to prawie wszystko, od pisania prostych zapytań SELECT po uzyskiwanie wszystkich wartości związanych z klientem, wstawianie, aktualizowanie lub usuwanie wartości.
Krótko mówiąc, powinniśmy unikać struktury EAV. Jeśli musisz go użyć, używaj go tylko wtedy, gdy masz 100% pewności, że jest naprawdę potrzebny.
#7 Używanie GUID/UUID jako klucza podstawowego
GUID (Globally Unique Identifier) to 128-bitowa liczba generowana zgodnie z regułami zdefiniowanymi w RFC 4122. Czasami są one również znane jako UUID (Universally Unique Identifiers). Główną zaletą identyfikatora GUID jest to, że jest wyjątkowy; prawdopodobieństwo, że trafisz dwa razy w ten sam GUID, jest naprawdę mało prawdopodobne. Dlatego identyfikatory GUID wydają się być świetnym kandydatem do kolumny klucza podstawowego. Ale tak nie jest.
Ogólna zasada dotycząca kluczy podstawowych jest taka, że używamy kolumny liczb całkowitych z właściwością autoincrement ustawioną na „tak”. Spowoduje to dodanie danych w kolejności sekwencyjnej do klucza podstawowego i zapewni optymalną wydajność. Bez klucza sekwencyjnego lub znacznika czasu nie ma możliwości sprawdzenia, które dane zostały wstawione jako pierwsze. Ten problem pojawia się również, gdy używamy UNIKATOWYCH wartości rzeczywistych (np. NIP). Chociaż mają wartości UNIKALNE, nie są dobrymi kluczami podstawowymi. Używaj ich jako klawiszy alternatywnych.
Jedna dodatkowa uwaga: Wolę używać jednokolumnowych automatycznie generowanych atrybutów liczb całkowitych jako klucza podstawowego. To zdecydowanie najlepsza praktyka. Zalecam unikanie używania złożonych kluczy podstawowych.
#8 Niewystarczające indeksowanie
Indeksy są bardzo ważną częścią pracy z bazami danych, ale dokładne omówienie ich wykracza poza zakres tego artykułu. Na szczęście mamy już kilka artykułów związanych z indeksami, które możesz sprawdzić, aby dowiedzieć się więcej:- Co to jest indeks bazy danych?
- Wszystko o indeksach:same podstawy
- Wszystko o indeksach, część 2:Struktura i wydajność indeksu MySQL
Krótka wersja jest taka, że zalecam dodanie indeksu wszędzie tam, gdzie oczekujesz, że będzie potrzebny. Możesz również dodać je po uruchomieniu bazy danych, jeśli zauważysz, że dodanie indeksu w określonym miejscu poprawi wydajność.
#9 nadmiarowe dane
Zasadniczo należy unikać nadmiarowych danych w każdym modelu. Nie tylko zajmuje dodatkowe miejsce na dysku, ale także znacznie zwiększa szanse na problemy z integralnością danych. Jeśli coś musi być zbędne, powinniśmy zadbać o to, aby oryginalne dane i „kopia” były zawsze w spójnych stanach. W rzeczywistości istnieją sytuacje, w których pożądane są nadmiarowe dane:
- W niektórych przypadkach musimy nadać priorytet określonej czynności — i aby tak się stało, musimy wykonać złożone obliczenia. Te obliczenia mogą wykorzystywać wiele tabel i zużywać dużo zasobów. W takich przypadkach rozsądnie byłoby wykonać te obliczenia poza godzinami pracy (w ten sposób unikając problemów z wydajnością w godzinach pracy). Jeśli zrobimy to w ten sposób, będziemy mogli przechowywać tę obliczoną wartość i wykorzystać ją później bez konieczności jej ponownego przeliczania. Oczywiście wartość jest zbędna; jednak to, co zyskujemy na wydajności, jest znacznie większe niż to, co tracimy (trochę miejsca na dysku twardym).
- Możemy również przechowywać mały zestaw danych raportowania w bazie danych. Na przykład na koniec dnia będziemy przechowywać liczbę wykonanych tego dnia połączeń, liczbę udanych sprzedaży itp. Dane raportowe powinny być przechowywane w ten sposób tylko wtedy, gdy musimy z nich często korzystać. Po raz kolejny stracimy trochę miejsca na dysku twardym, ale unikniemy ponownego obliczania danych lub łączenia się z bazą danych raportowania (jeśli taką posiadamy).
W większości przypadków nie powinniśmy używać nadmiarowych danych, ponieważ:
- Przechowywanie tych samych danych więcej niż raz w bazie danych może wpłynąć na integralność danych. Jeśli przechowujesz nazwę klienta w dwóch różnych miejscach, powinieneś wprowadzić zmiany (wstawić/zaktualizować/usunąć) w obu miejscach jednocześnie. To również komplikuje kod, którego będziesz potrzebować, nawet do najprostszych operacji.
- Chociaż moglibyśmy przechowywać pewne zagregowane liczby w naszej operacyjnej bazie danych, powinniśmy to robić tylko wtedy, gdy naprawdę jest to konieczne. Operacyjna baza danych nie jest przeznaczona do przechowywania danych raportowania, a mieszanie tych dwóch jest generalnie złą praktyką. Każdy, kto tworzy raporty, będzie musiał korzystać z tych samych zasobów, co użytkownicy pracujący nad zadaniami operacyjnymi; Zapytania raportowania są zwykle bardziej złożone i mogą wpływać na wydajność. Dlatego powinieneś oddzielić swoją operacyjną bazę danych od bazy danych raportowania.
Teraz Twoja kolej na ważenie
Mam nadzieję, że przeczytanie tego artykułu dostarczyło Ci nowych informacji i zachęci Cię do stosowania najlepszych praktyk modelowania danych. Zaoszczędzą Ci trochę czasu!
Czy napotkałeś któryś z problemów wymienionych w tym artykule? Myślisz, że przegapiliśmy coś ważnego? A może uważasz, że powinniśmy coś usunąć z naszej listy? Powiedz nam w komentarzach poniżej.