Jako administratorzy baz danych SQL Server słyszeliśmy, że struktury indeksów mogą znacznie poprawić wydajność dowolnego zapytania (lub zestawu zapytań). Mimo to istnieją pewne szczegóły, które wielu administratorów baz danych przeocza, takie jak:
- Struktury indeksów mogą ulec fragmentacji, co potencjalnie prowadzi do problemów z pogorszeniem wydajności.
- Po wdrożeniu struktury indeksu dla tabeli bazy danych SQL Server aktualizuje ją za każdym razem, gdy dla tej tabeli są wykonywane operacje zapisu. Dzieje się tak, jeśli dotyczy to kolumn zgodnych z indeksem.
- W SQL Server znajdują się metadane, dzięki którym można dowiedzieć się, kiedy statystyki dla określonej struktury indeksu zostały (jeśli w ogóle) zostały zaktualizowane po raz ostatni. Niewystarczające lub nieaktualne statystyki mogą wpłynąć na wydajność niektórych zapytań.
- Wewnątrz SQL Server znajdują się metadane, których można użyć, aby dowiedzieć się, jak bardzo struktura indeksu została zużyta przez operacje odczytu lub zaktualizowana przez operacje zapisu przez sam SQL Server. Ta informacja może być przydatna, aby dowiedzieć się, czy istnieją indeksy, których objętość zapisu znacznie przekracza liczbę odczytaną. Potencjalnie może to być struktura indeksu, której nie warto się trzymać.*
*Bardzo ważne jest, aby pamiętać, że widok systemowy, który przechowuje te konkretne metadane, jest czyszczony za każdym razem, gdy instancja SQL Server jest ponownie uruchamiana, więc nie będą to informacje z jej koncepcji.
Ze względu na wagę tych szczegółów stworzyłem Procedurę Zapisaną, aby śledzić informacje dotyczące struktur indeksów w jego środowisku, aby działać jak najbardziej proaktywnie.
Rozważania wstępne
- Upewnij się, że konto wykonujące tę procedurę składowaną ma wystarczające uprawnienia. Prawdopodobnie mógłbyś zacząć od tych administratorów, a następnie przejść tak szczegółowo, jak to możliwe, aby upewnić się, że użytkownik ma minimalne uprawnienia wymagane do prawidłowego działania SP.
- Obiekty bazy danych (tabela bazy danych i procedura składowana) zostaną utworzone wewnątrz bazy danych wybranej w czasie wykonywania skryptu, więc wybieraj ostrożnie.
- Skrypt jest tak skonstruowany, że można go wykonać wiele razy bez generowania błędu. W przypadku procedury składowanej użyłem instrukcji CREATE OR ALTER PROCEDURE, dostępnej od SQL Server 2016 SP1.
- Możesz zmienić nazwę utworzonych obiektów bazy danych, jeśli chcesz użyć innej konwencji nazewnictwa.
- Gdy wybierzesz opcję utrwalania danych zwróconych przez procedurę składowaną, tabela docelowa zostanie najpierw obcięta, tak aby przechowywany był tylko najnowszy zestaw wyników. Możesz dokonać niezbędnych korekt, jeśli chcesz, aby to zachowywało się inaczej, z jakiegokolwiek powodu (być może aby zachować informacje historyczne?).
Jak korzystać z procedury zapisanej?
- Skopiuj i wklej kod T-SQL (dostępny w tym artykule).
- SP oczekuje 2 parametrów:
- @persistData:„Y”, jeśli administrator danych chce zapisać dane wyjściowe w tabeli docelowej, i „N”, jeśli administrator danych chce tylko zobaczyć dane wyjściowe bezpośrednio.
- @db:„wszystkie”, aby uzyskać informacje o wszystkich bazach danych (system i użytkownik), „użytkownik”, aby kierować do baz danych użytkowników, „system”, aby kierować tylko systemowe bazy danych (z wyłączeniem tempdb), a na koniec rzeczywista nazwa konkretną bazę danych.
Prezentowane pola i ich znaczenie
- dbName: nazwa bazy danych, w której znajduje się obiekt indeksu.
- nazwa schematu: nazwa schematu, w którym znajduje się obiekt indeksu.
- nazwa_tabeli: nazwa tabeli, w której znajduje się obiekt indeksu.
- Nazwa indeksu: nazwa struktury indeksu.
- typ: typ indeksu (np. klastrowy, nieklastrowy).
- allocation_unit_type: określa typ danych, do których się odwołuje (np. dane w wierszu, dane lob).
- fragmentacja: ilość fragmentacji (w %), jaką ma obecnie struktura indeksu.
- strony: liczba stron 8KB, które tworzą strukturę indeksu.
- pisze: liczba zapisów, których doświadczyła struktura indeksu od ostatniego ponownego uruchomienia instancji SQL Server.
- czyta: liczba odczytów, jakich doświadczyła struktura indeksu od ostatniego ponownego uruchomienia instancji SQL Server.
- wyłączone: 1, jeśli struktura indeksu jest obecnie wyłączona lub 0, jeśli struktura jest włączona.
- stats_timestamp: wartość znacznika czasu ostatniej aktualizacji statystyk dla określonej struktury indeksu (NULL, jeśli nigdy).
- data_collection_timestamp: widoczne tylko wtedy, gdy „Y” jest przekazywane do parametru @persistData i jest używane, aby wiedzieć, kiedy SP został wykonany, a informacje zostały pomyślnie zapisane w tabeli DBA_Indexes.
Testy wykonania
Pokażę kilka wykonań procedury składowanej, abyś mógł zorientować się, czego się po niej spodziewać:
*Pełny kod T-SQL skryptu można znaleźć na końcu tego artykułu, więc upewnij się, że wykonałeś go, zanim przejdziesz do następnej sekcji.
*Zestaw wyników będzie zbyt szeroki, aby zmieścić się na 1 zrzucie ekranu, więc udostępnię wszystkie niezbędne zrzuty ekranu, aby przedstawić pełne informacje.
/* Wyświetl wszystkie informacje o indeksach dla wszystkich baz danych systemu i użytkowników */
EXEC GetIndexData @persistData = 'N',@db = 'all'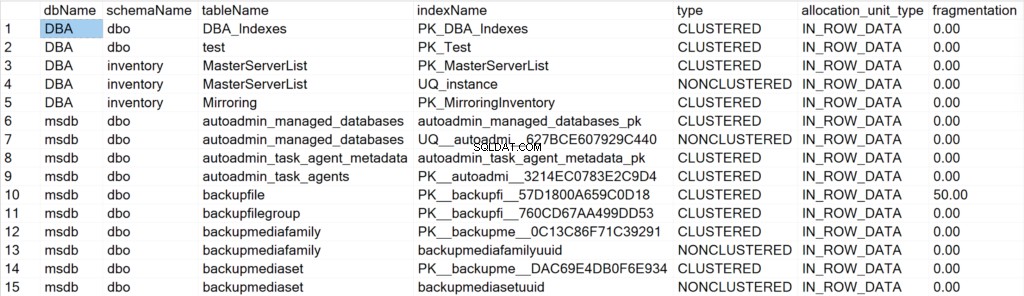
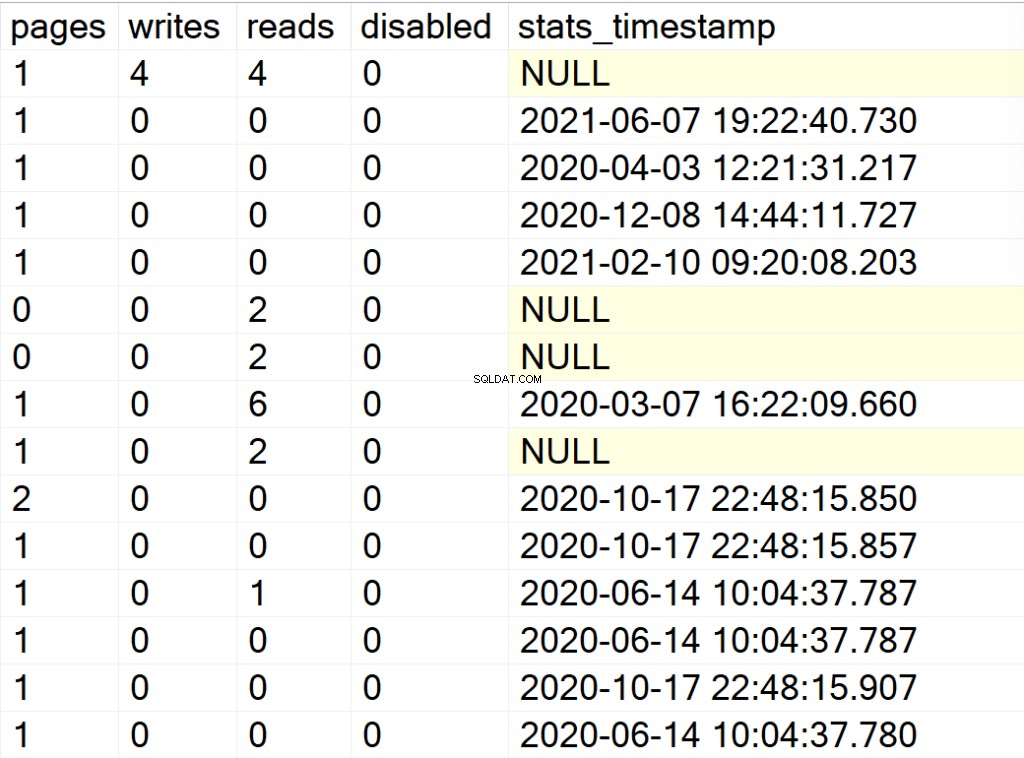
/* Wyświetl wszystkie informacje o indeksach dla wszystkich systemowych baz danych */
EXEC GetIndexData @persistData = 'N',@db = 'system'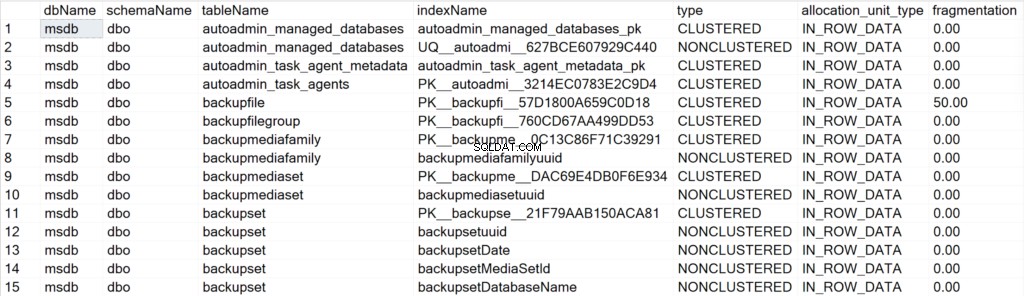
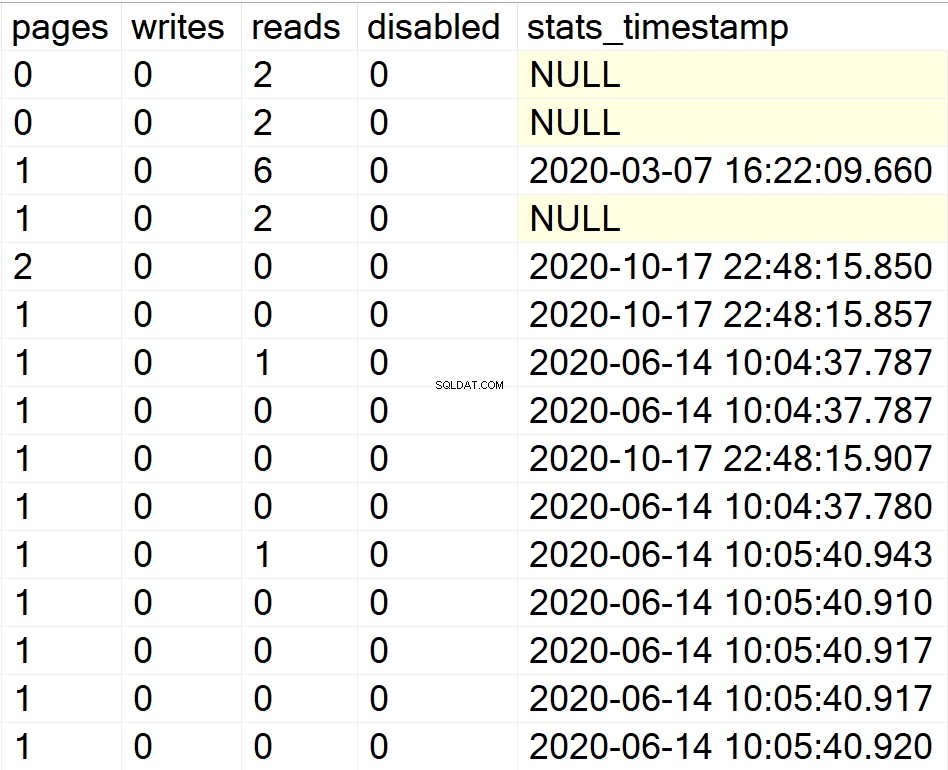
/* Wyświetl wszystkie informacje o indeksach dla wszystkich baz danych użytkowników */
EXEC GetIndexData @persistData = 'N',@db = 'user'
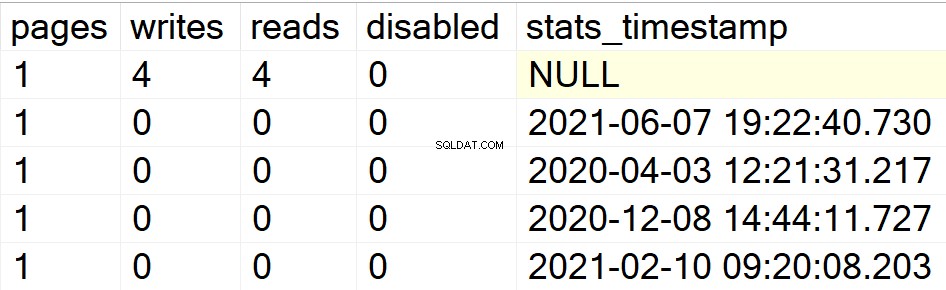
/* Wyświetl wszystkie informacje o indeksach dla określonych baz danych użytkowników */
W moich poprzednich przykładach tylko baza danych DBA była wyświetlana jako moja jedyna baza użytkowników z indeksami. Dlatego pozwól mi utworzyć strukturę indeksu w innej bazie danych, którą mam w tej samej instancji, abyś mógł zobaczyć, czy SP robi swoje, czy nie.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Wszystkie zaprezentowane do tej pory przykłady pokazują dane wyjściowe, które otrzymujesz, gdy nie chcesz utrwalać danych, dla różnych kombinacji opcji dla parametru @db. Dane wyjściowe są puste, gdy określisz opcję, która jest nieprawidłowa lub docelowa baza danych nie istnieje. Ale co zrobić, gdy administrator baz danych chce utrwalić dane w tabeli bazy danych? Dowiedzmy się.
*Zamierzam uruchomić SP tylko dla jednego przypadku, ponieważ pozostałe opcje parametru @db zostały w dużej mierze przedstawione powyżej, a wynik jest taki sam, ale utrwalony w tabeli bazy danych.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
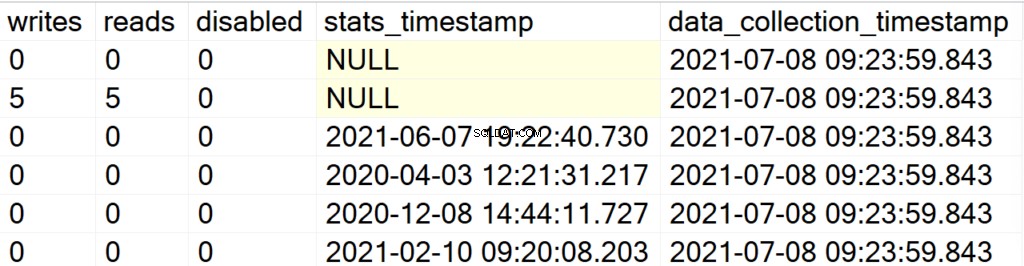
Teraz, po wykonaniu procedury przechowywanej, nie otrzymasz żadnych danych wyjściowych. Aby zapytać o zestaw wyników, musisz wydać instrukcję SELECT w odniesieniu do tabeli DBA_Indexes. Główną atrakcją jest tutaj to, że możesz wysłać zapytanie do otrzymanego zestawu wyników do postanalizy i dodać pole data_collection_timestamp, które poinformuje Cię, jak aktualne/stare są dane, na które patrzysz.
Zapytania poboczne
Teraz, aby zapewnić DBA większą wartość, przygotowałem kilka zapytań, które mogą pomóc w uzyskaniu przydatnych informacji z danych utrwalonych w tabeli.
*Zapytanie, aby znaleźć ogólnie bardzo pofragmentowane indeksy.
*Wybierz liczbę %, które uważasz za odpowiednie.
*1500 stron jest opartych na artykule, który przeczytałem, na podstawie rekomendacji Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Zapytanie, aby znaleźć wyłączone indeksy w Twoim środowisku.
SELECT * FROM DBA_Indexes WHERE disabled = 1;* Zapytanie w celu znalezienia indeksów (w większości nieklastrowanych), które nie są tak często używane przez zapytania, przynajmniej od czasu ostatniego restartu instancji SQL Server.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Zapytanie, aby znaleźć statystyki, które nigdy nie były aktualizowane lub są stare.
* Ty określasz, co jest stare w Twoim środowisku, więc pamiętaj o odpowiednim dostosowaniu liczby dni.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Oto pełny kod procedury przechowywanej:
*Na samym początku skryptu zobaczysz domyślną wartość, którą przyjmuje procedura składowana, jeśli nie przekazano żadnej wartości dla każdego parametru.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOWniosek
- Możesz wdrożyć ten SP w każdej instancji SQL Server pod twoim wsparciem i wdrożyć mechanizm ostrzegania w całym stosie obsługiwanych instancji.
- Jeśli zaimplementujesz zadanie agenta, które stosunkowo często odpytuje te informacje, możesz pozostać na szczycie gry, aby zająć się strukturami indeksów w obsługiwanych środowiskach.
- Upewnij się, że prawidłowo przetestowałeś ten mechanizm w środowisku piaskownicy, a planując wdrożenie produkcyjne, wybierz okresy niskiej aktywności.
Problemy z fragmentacją indeksu mogą być trudne i stresujące. Aby je znaleźć i naprawić, możesz użyć różnych narzędzi, takich jak dbForge Index Manager, który można pobrać tutaj.



