Jest to czwarta część z pięcioczęściowej serii, w której szczegółowo omówiono sposób, w jaki rozpoczynają się wykonywanie planów równoległych w trybie wiersza SQL Server. Część 1 zainicjowała kontekst wykonania zero dla zadania nadrzędnego, a część 2 utworzyła drzewo skanowania zapytań. Część 3 rozpoczęła skanowanie zapytania, wykonała wczesną fazę przetwarzania i rozpoczął pierwsze dodatkowe zadania równoległe w gałęzi C.
Szczegóły wykonania oddziału C
To jest drugi krok sekwencji wykonywania:
- Oddział A (zadanie nadrzędne).
- Oddział C (dodatkowe zadania równoległe).
- Gałąź D (dodatkowe zadania równoległe).
- Gałąź B (dodatkowe zadania równoległe).
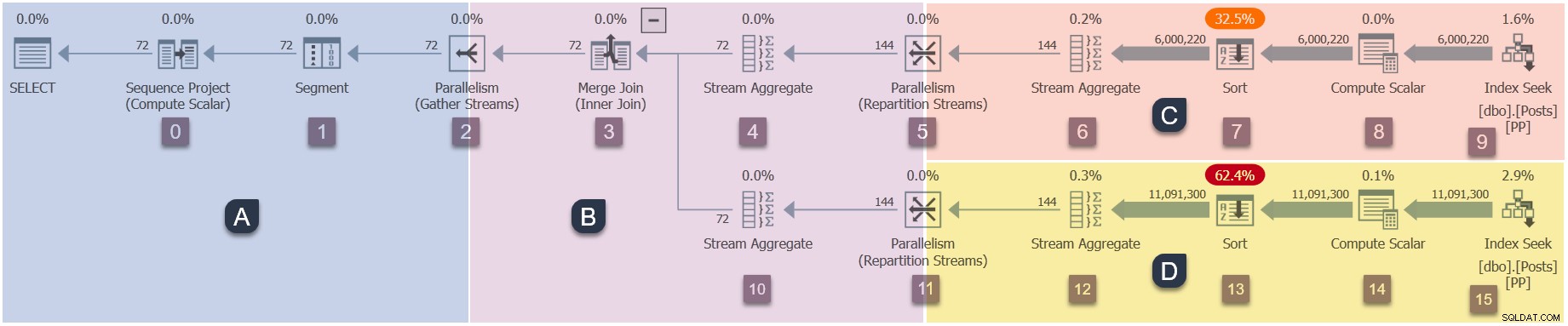
Przypomnienie o oddziałach w naszym planie równoległym (kliknij, aby powiększyć)
Krótko po nowych zadaniach dla gałęzi C są w kolejce, SQL Server dołącza pracownika do każdego zadania i umieszcza pracownika w harmonogramie gotowy do realizacji. Każde nowe zadanie jest uruchamiane w nowym kontekście wykonania. W DOP 2 są dwa nowe zadania, dwa wątki robocze i dwa konteksty wykonania dla gałęzi C. Każde zadanie uruchamia własną kopię iteratorów w gałęzi C we własnym wątku roboczym:

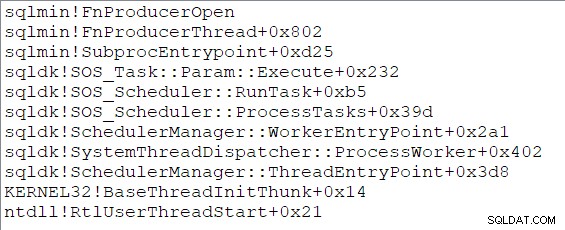
Dwa nowe równoległe zadania zaczynają działać w procedurze podrzędnej punkt wejścia, który początkowo prowadzi do Open zadzwoń po stronie producenta giełdy (CQScanXProducerNew::Open ). Oba zadania mają identyczne stosy wywołań na początku swojego życia:
Synchronizacja wymiany
Tymczasem zadanie nadrzędne (działa we własnym wątku roboczym) rejestruje nowe podprocesy u menedżera podprocesów, a następnie czeka po stronie konsumenta wymiany strumieni partycji w węźle 5. Zadanie nadrzędne czeka na CXPACKET * do wszystkich zadań równoległych gałęzi C kończy swoje Open telefonuje i wraca do strony producenta wymiany. Zadania równoległe otworzą każdy iterator w swoim poddrzewie (tj. aż do przeszukiwania indeksu w węźle 9 i z powrotem) przed powrotem do wymiany strumieni repartycji w węźle 5. Zadanie nadrzędne będzie czekać na CXPACKET kiedy to się dzieje. Pamiętaj, że zadanie nadrzędne wykonuje wywołania we wczesnych fazach.
Możemy to zobaczyć w zadaniach oczekujących DMV:

Zerowy kontekst wykonania (zadanie nadrzędne) jest blokowany przez oba nowe konteksty wykonania. Te konteksty wykonania są pierwszymi dodatkowymi, które zostaną utworzone po kontekście zero, więc mają przypisane liczby jeden i dwa. Aby podkreślić:oba nowe konteksty wykonania muszą otworzyć swoje poddrzewa i powrócić do wymiany dla CXPACKET zadania nadrzędnego poczekaj na zakończenie.
Być może spodziewałeś się zobaczyć CXCONSUMER czeka tutaj, ale to czekanie jest zarezerwowane na czekanie na dane wiersza przybyć. Bieżące oczekiwanie nie dotyczy wierszy — otwiera się po stronie producenta , więc otrzymujemy ogólny CXPACKET * czekaj.
* Baza danych SQL Azure i wystąpienie zarządzane korzystają z nowego CXSYNC_PORT czekaj zamiast CXPACKET tutaj, ale to ulepszenie nie zostało jeszcze wprowadzone do SQL Server (od 2019 CU9).
Kontrola nowych zadań równoległych
Nowe zadania widzimy w profilach zapytań DMV. Informacje o profilowaniu dla nowych zadań pojawiają się w DMV, ponieważ ich konteksty wykonania zostały wyprowadzone (sklonowane, a następnie zaktualizowane) od elementu nadrzędnego (kontekst wykonania zero):
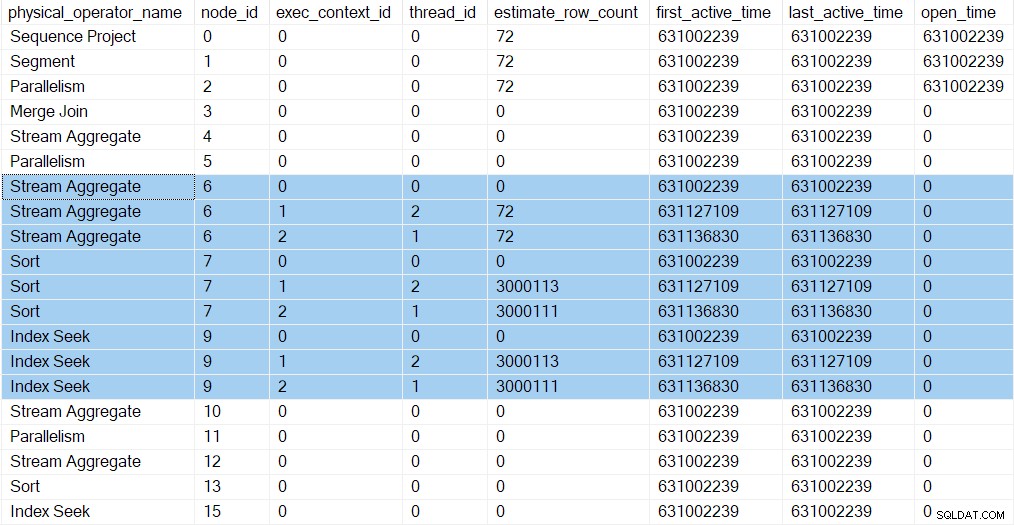
Istnieją teraz trzy wpisy dla każdego iteratora w gałęzi C (podświetlone). Jeden dla zadania nadrzędnego (kontekst wykonania zero) i jeden dla każdego nowego dodatkowego zadania równoległego (kontekst 1 i 2). Zwróć uwagę, że szacowana liczba wierszy na wątek (patrz część 1) przybyły teraz i są pokazane tylko dla zadań równoległych. Pierwszy i ostatni czas aktywności dla zadań równoległych reprezentuje czas, w którym zostały utworzone ich konteksty wykonania. Żadne z nowych zadań nie otwierało się żadnych iteratorów jeszcze.
strumienie podziału wymiana w węźle 5 nadal ma tylko jeden wpis na wyjściu DMV. Dzieje się tak, ponieważ powiązany niewidoczny profiler monitoruje konsumenta stronie wymiany. Dodatkowe zadania równoległe znajdują się u producenta stronie wymiany. Strona konsumenta węzła 5 w końcu mamy równoległe zadania, ale jeszcze nie doszliśmy do tego punktu.
Punkt kontrolny
Wydaje się, że to dobry moment, aby zatrzymać się na oddech i podsumować, gdzie wszystko jest w tej chwili. W miarę postępów będzie więcej tych punktów zatrzymania.
- Zadanie nadrzędne jest po stronie konsumenta wymiany strumieni repartycji w węźle 5 , czekam na
CXPACKET. Jest w trakcie wykonywania połączeń we wczesnych fazach. Zatrzymał się, aby uruchomić gałąź C, ponieważ ta gałąź zawiera sortowanie blokujące. Oczekiwanie nadrzędnego zadania będzie kontynuowane, aż oba równoległe zadania zakończą otwieranie swoich poddrzew. - Dwa nowe równoległe zadania po stronie producenta centrali węzła 5 jest gotowych do otwarcia iteratorów w gałęzi C.
Nic poza gałęzią C tego równoległego planu wykonania nie może posuwać się naprzód, dopóki zadanie nadrzędne nie zostanie zwolnione z jego CXPACKET czekać. Pamiętaj, że do tej pory utworzyliśmy tylko jeden zestaw dodatkowych procesów roboczych dla gałęzi C. Jedynym innym wątkiem jest zadanie nadrzędne, które jest zablokowane.
Wykonywanie równoległe oddziału C
Dwa równoległe zadania zaczynają się od strony producenta wymiany strumieni repartycji w węźle 5. Każdy ma oddzielny (szeregowy) plan z własną agregacją strumieni, sortowaniem i wyszukiwaniem indeksowym. Skalar obliczeniowy nie pojawia się w planie wykonawczym, ponieważ jego obliczenia są odroczone do sortowania.
Każde wystąpienie wyszukiwania indeksu jest rozpoznawane równolegle i działa na rozłącznych zestawach rzędów. Te zestawy są generowane na żądanie z nadrzędnego zestawu wierszy utworzonego wcześniej przez zadanie nadrzędne (omówione w części 1). Gdy którakolwiek instancja wyszukiwania potrzebuje nowego podzakresu wierszy, synchronizuje się z innymi wątkami roboczymi, dzięki czemu tylko jeden podzakres przydziela nowy podzakres w tym samym czasie. Użyty obiekt synchronizacji również został utworzony wcześniej przez zadanie nadrzędne. Gdy zadanie czeka na wyłączny dostęp do nadrzędnego zestawu wierszy w celu uzyskania nowego podzakresu, czeka na CXROWSET_SYNC .
Zadania gałęzi C otwarte
Sekwencja Open wywołania dla każdego zadania w Gałąź C to:
CQScanXProducerNew::Open. Zwróć uwagę, że po stronie producenta wymiany nie ma poprzedzającego programu profilującego. Jest to niefortunne dla tunerów zapytań.CXTransLocal::OpenCXPort::RegisterCXTransLocal::ActivateWorkersCQScanProfileNew::Open. Profiler nad węzłem 6.CQScanStreamAggregateNew::Open(węzeł 6)CQScanProfileNew::Open. Profiler nad węzłem 7.CQScanSortNew::Open(węzeł 7)
Sort jest w pełni operatorem blokującym . Zużywa całe dane wejściowe podczas Open połączenie. Jest tu wiele interesujących szczegółów wewnętrznych do zbadania, ale miejsca jest mało, więc omówię tylko najważniejsze:
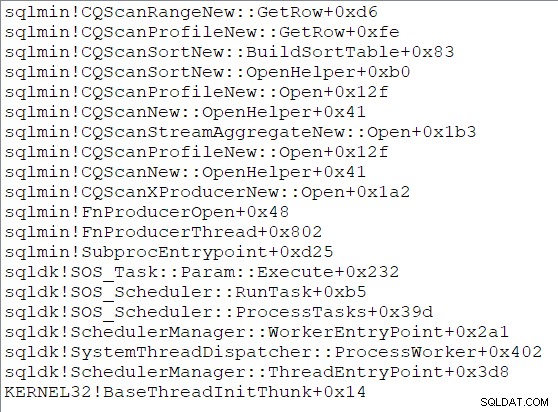
sortowanie buduje swoją tabelę sortowania, otwierając swoje poddrzewo i zużywając wszystkie wiersze, które mogą dostarczyć jej elementy potomne. Po zakończeniu sortowania sortowanie jest gotowe do przejścia do trybu wyjściowego i zwraca kontrolę nadrzędnemu. Sortowanie będzie później odpowiadać na GetRow() wzywa, zwracając za każdym razem kolejny posortowany wiersz. Przykładowy stos wywołań podczas sortowania to:
Wykonywanie jest kontynuowane, dopóki każdy sort nie zużyje wszystkich (rozłącznych zakresów) wierszy dostępnych z jego podrzędnego przeszukiwania indeksu . Sortowanie następnie wywołuje Close w wynikach wyszukiwania indeksu i zwraca kontrolę nadrzędnemu agregatowi strumienia . Agregaty strumieni inicjują swoje liczniki i zwracają kontrolę do producenta strona wymiany partycji w węźle 5. Sekwencja Open połączenia w tej gałęzi są teraz zakończone.
Profilowanie DMV w tym momencie pokazuje zaktualizowane liczby czasu i czasy zamknięcia dla indeksu równoległego szuka:
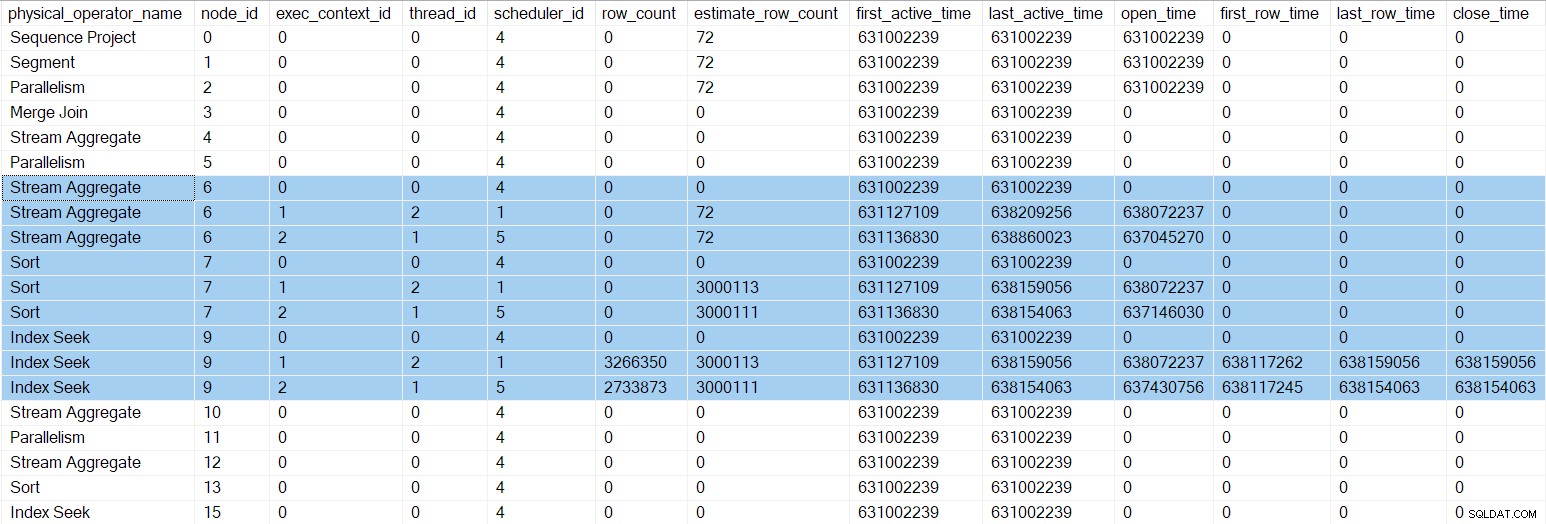
Więcej synchronizacji wymiany
Przypomnij sobie, że zadanie nadrzędne czeka na konsumenta strona węzła 5 dla wszystkich producentów, aby otworzyć. Podobny proces synchronizacji zachodzi teraz wśród równoległych zadań producenta strona tej samej giełdy:
Każde zadanie producenta synchronizuje się z innymi za pomocą CXTransLocal::Synchronize . Producenci nazywają CXPort::Open , a następnie poczekaj na CXPACKET dla wszystkich po stronie konsumenta równoległe zadania do otwarcia. Kiedy pierwsze zadanie równoległe gałęzi C wraca po stronie producenta na giełdzie i czeka, zadania oczekujące DMV wyglądają następująco:

Nadal mamy oczekiwania po stronie konsumenta zadania nadrzędnego. Nowy CXPACKET wyróżnione jest nasze pierwsze równoległe zadanie po stronie producenta, które czeka na wszystkie równoległe zadania po stronie konsumenta aby otworzyć port wymiany.
Zadania równoległe po stronie konsumenta (w gałęzi B) jeszcze nie istnieją, więc zadanie producenta wyświetla NULL dla kontekstu wykonania, przez który jest blokowane. Zadanie aktualnie oczekujące po stronie konsumenta wymiany strumieni repartycji jest zadaniem nadrzędnym (nie równoległym!) uruchamiającym EarlyPhases kod, więc to się nie liczy.
Czekanie CXPACKET zadania nadrzędnego się kończy
Kiedy druga zadanie równoległe w gałęzi C wraca po stronie producenta giełdy ze swojego Open połączeń, wszyscy producenci otworzyli port wymiany, więc zadanie nadrzędne po stronie konsumenta giełdy jest udostępniony z jego CXPACKET czekaj.
Pracownicy po stronie producenta nadal czekają na utworzenie równoległych zadań po stronie konsumenta i otwarcie portu wymiany:

Punkt kontrolny
W tym momencie:
- Istnieją w sumie trzy zadania:dwa w gałęzi C plus zadanie nadrzędne.
- Obaj producenci w węźle 5 giełda otworzyła się i czeka na
CXPACKETaby otworzyć równoległe zadania po stronie konsumenta. Wiele maszyn do wymiany (w tym bufory rzędów) jest tworzonych przez stronę konsumenta, więc producenci nie mają jeszcze miejsca na umieszczenie rzędów. - sortuje w Gałęzi C zużyli wszystkie swoje dane wejściowe i są gotowi do dostarczenia posortowanych danych wyjściowych.
- Indeks szuka w Oddziale C zakończyli pracę i zamknęli.
- Zadanie nadrzędne właśnie został zwolniony z oczekiwania na
CXPACKETpo stronie konsumenta wymiany strumieni wymiany węzła 5. Jest nadal wykonywanie zagnieżdżonychEarlyPhasespołączeń.
Rozpoczęcie zadań równoległych gałęzi D
To jest trzeci krok w sekwencji wykonywania:
- Oddział A (zadanie nadrzędne).
- Gałąź C (dodatkowe zadania równoległe).
- Oddział D (dodatkowe zadania równoległe).
- Gałąź B (dodatkowe zadania równoległe).
Wydany ze swojego CXPACKET czekaj po stronie konsumenta wymiany strumieni repartycji w węźle 5, zadaniu nadrzędnym wznosi się drzewo skanowania zapytań gałęzi B. Wraca z zagnieżdżonych EarlyPhases wywołuje różne iteratory i profilery na zewnętrznym (górnym) wejściu połączenia scalającego.
Jak wspomniano, wznoszące drzewo aktualizuje czasy, które upłynął i czasy procesora zarejestrowane przez niewidoczne iteratory profilowania. Wykonujemy kod za pomocą zadania nadrzędnego, więc te liczby są rejestrowane względem kontekstu wykonania zero. Jest to ostateczne źródło liczb czasowych „wątku 0”, o których mowa w moim poprzednim artykule, Zrozumienie czasów operatora planu wykonania.
Po powrocie do łączenia przez scalanie zadanie nadrzędne wywołuje EarlyPhases dla iteratorów i profilerów na wewnętrznych (dolnych) danych wejściowych do łączenia scalającego. To są węzły od 10 do 15 (z wyjątkiem 14, które jest odroczone):
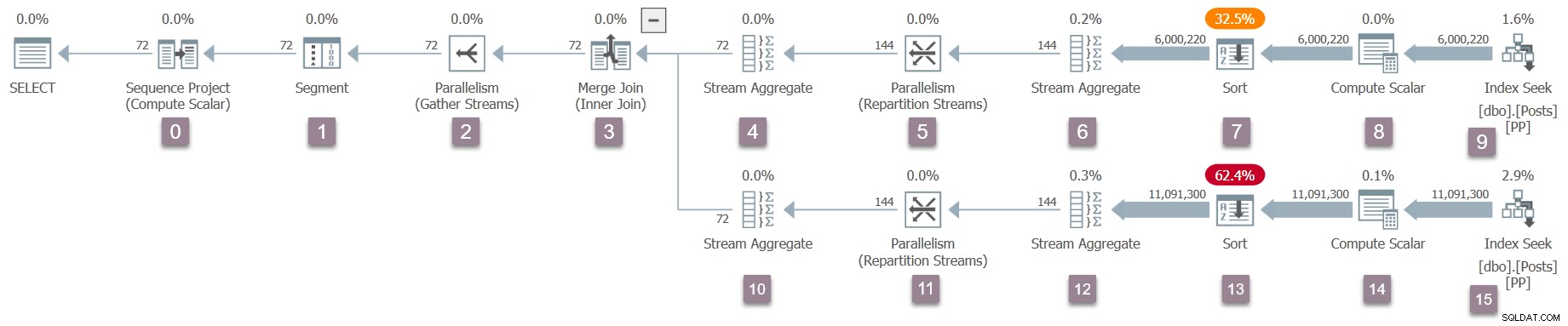
Gdy wywołania wczesnej fazy zadania nadrzędnego dotrą do indeksu wyszukiwania w węźle 15, zaczyna ponownie wznosić się w drzewie (ustawiając czasy profilowania), aż dotrze do wymiany strumieni partycji w węźle 11.
Następnie, tak jak to miało miejsce na zewnętrznym (górnym) wejściu do połączenia scalającego, uruchamia stronę producenta giełdy w węźle 11 , tworząc dwa nowe równoległe zadania .
To wprawia w ruch gałąź D (pokazaną poniżej). Gałąź D działa dokładnie tak, jak opisano szczegółowo dla Gałąź C.
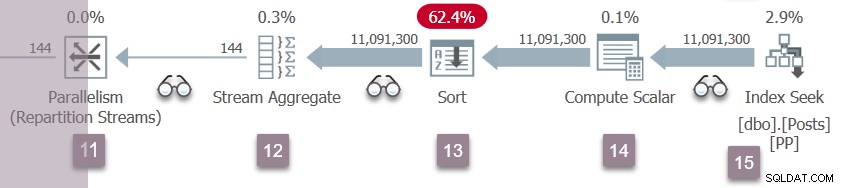
Natychmiast po rozpoczęciu zadań dla Gałęzi D zadanie nadrzędne czeka na CXPACKET w węźle 11, aby nowi producenci otworzyli port wymiany:

Nowy CXPACKET oczekiwania są podświetlone. Zwróć uwagę, że zgłoszony identyfikator węzła może być nieco mylący. Zadanie nadrzędne naprawdę czeka po stronie konsumenta węzła 11 (strumienie repartycji), a nie węzła 2 (zbieranie strumieni). To dziwactwo przetwarzania we wczesnej fazie.
Tymczasem wątki producenta w gałęzi C nadal czekają na CXPACKET dla strony konsumenta wymiany strumieni repartycji węzła 5 na otwarcie.
Otwór oddziału D
Zaraz po tym, jak zadanie nadrzędne uruchomi producentów gałęzi D, profil zapytania DMV pokazuje nowe konteksty wykonania (3 i 4):
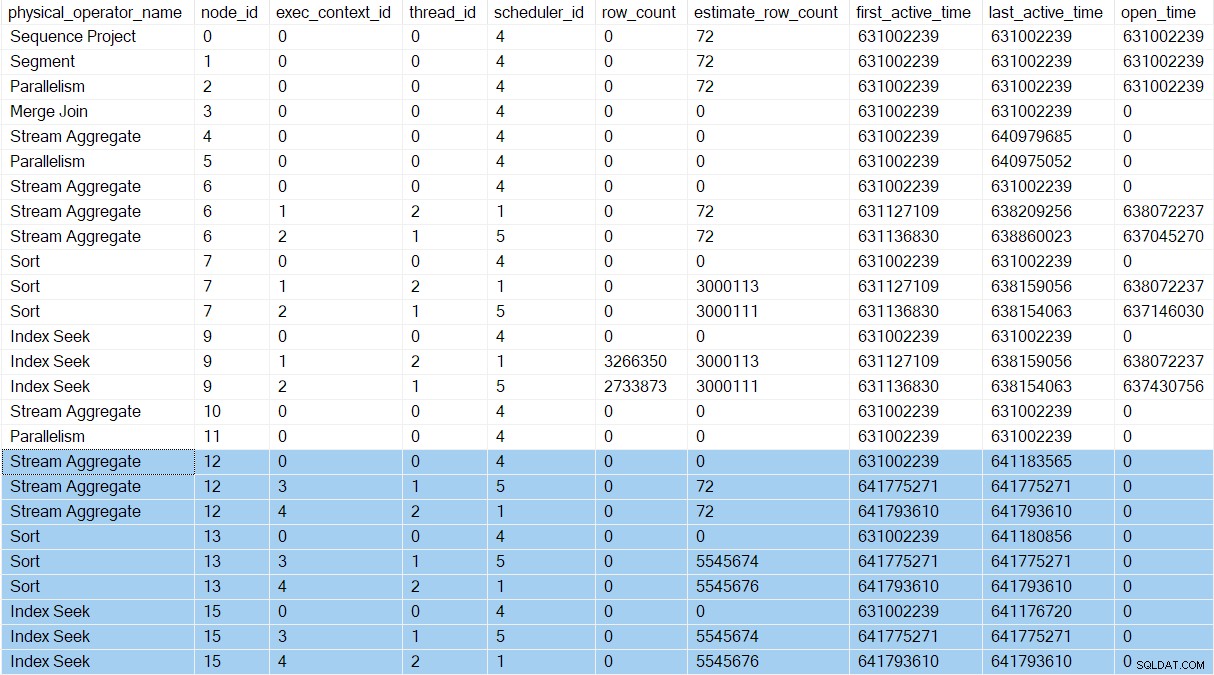
Dwa nowe równoległe zadania w Gałąź D postępuj dokładnie tak, jak w Gałęzi C. Rodzaje zużywają cały ich wkład, a zadania Gałęzi D wracają do wymiany. To zwalnia zadanie nadrzędne z jego CXPACKET czekać. Pracownicy gałęzi D czekają na CXPACKET po stronie producenta węzła 11, aby otworzyć równoległe zadania po stronie konsumenta. Ci pracownicy równolegli (w Oddziale B) jeszcze nie istnieją.
Punkt kontrolny
Zadania oczekujące w tym momencie są pokazane poniżej:

Oba zestawy równoległych zadań w gałęziach C i D czekają na CXPACKET dla ich zadań równoległych konsumenci otwierają się, przy strumieniach repartycyjnych wymieniają odpowiednio węzły 5 i 11. Jedyne zadanie, które można uruchomić w całym zapytaniu jest teraz zadaniem nadrzędnym .
Profiler zapytań DMV w tym momencie jest pokazany poniżej, z podświetlonymi operatorami w gałęziach C i D:
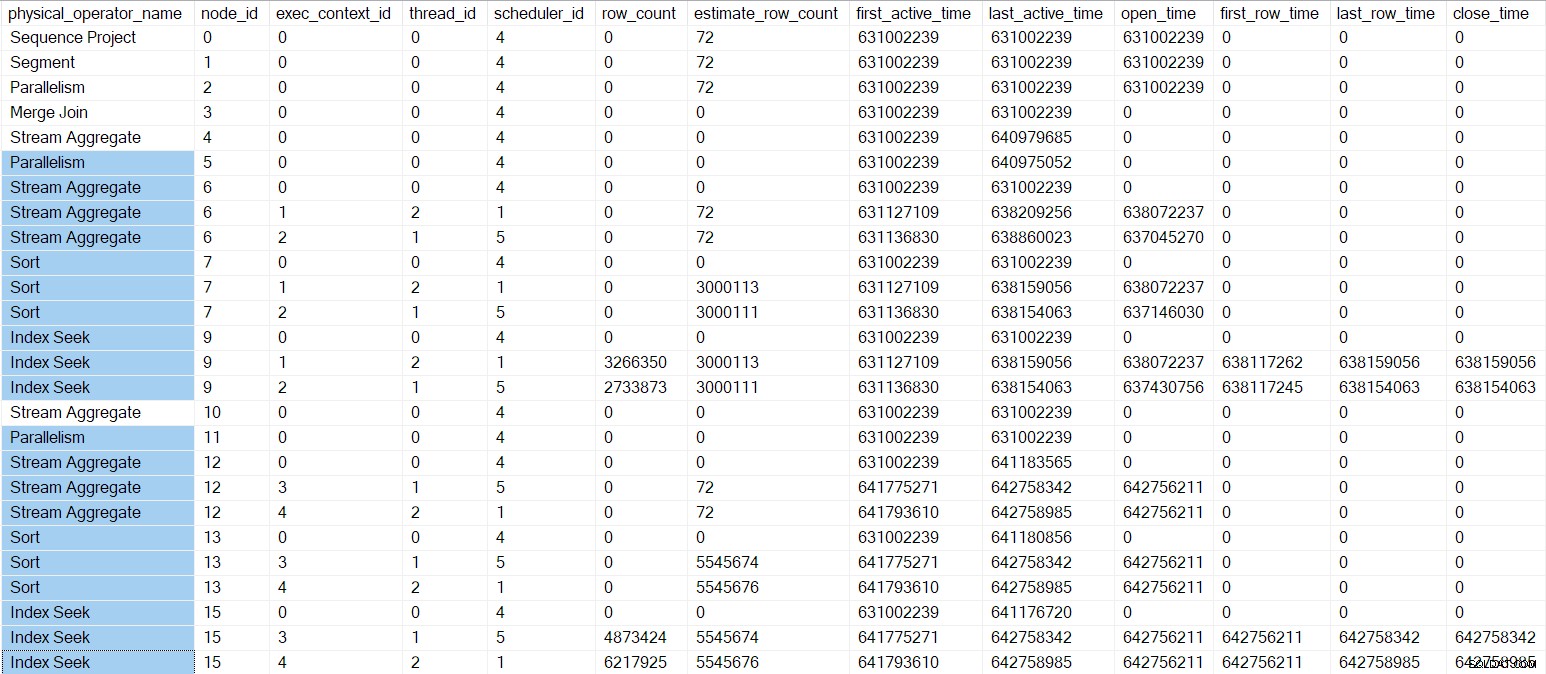
Jedyne równoległe zadania, których jeszcze nie rozpoczęliśmy, znajdują się w Gałąź B. Cała dotychczasowa praca w Gałęzi B była wczesnymi fazami połączenia wykonywane przez zadanie nadrzędne .
Koniec części 4
W końcowej części tej serii opiszę, jak rozpoczyna się pozostała część tego konkretnego równoległego planu wykonania, i krótko opiszę, w jaki sposób plan zwraca wyniki. Zakończę bardziej ogólnym opisem, który dotyczy równoległych planów o dowolnej złożoności.



