We wcześniejszym samouczku „Scalanie plików danych z programem Statistica, część 1” wprowadziliśmy użycie programu Statistica do łączenia arkuszy kalkulacyjnych. Omówiliśmy tryb łączenia konkatenacji. W tym samouczku omówimy dwa inne tryby:używanie nazw przypadków i nazw zmiennych. Ten samouczek zawiera następujące sekcje:
- Używanie nazw spraw do scalania plików danych
- Używanie nazw zmiennych do łączenia plików danych
- Wniosek
Używanie nazw spraw do scalania plików danych
Następnie połączymy pliki danych (arkusze kalkulacyjne), dopasowując wiersze (zwane również przypadkami ). Jeśli wiersze mają takie same nazwy spraw, dane w wierszach z dwóch plików danych zostaną scalone. Przykładowe pliki danych, których użyliśmy w poprzednim artykule, nie zawierają nazwy sprawy. Nazwa sprawy jest określona w kolumnie 1, kolumnie przed kolumnami danych. Używając tych samych danych, co w przypadku łączenia plików danych, dodaj nazwy przypadków (log1 do log6 ) do wierszy w wlslog1.sta arkusz kalkulacyjny, jak pokazano na rysunku 1.
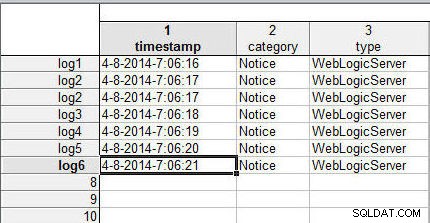
Rysunek 1: Arkusz kalkulacyjny wlslog1
Podobnie dodaj nazwy przypadków (log1 do log6 ) do każdego wiersza w wlslog2.sta , jak pokazano na rysunku 2.
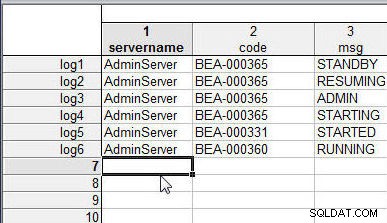
Rysunek 2: Arkusz kalkulacyjny wlslog2
Wybierz Dane>Scal oraz w Opcjach scalania , wybierz Tryb jako Dopasuj nazwy przypadków , jak pokazano na rysunku 3. Kliknij OK .
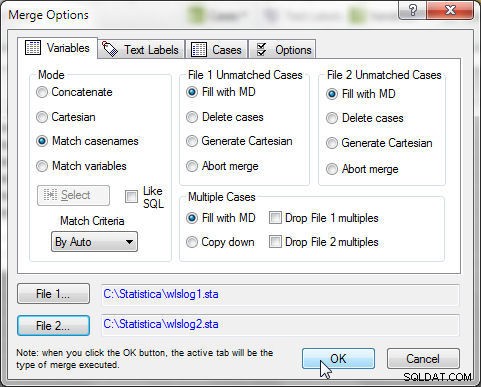
Rysunek 3: Scalanie wlslog1 i wlslog2
Dane w wlslog1.sta arkusz kalkulacyjny zostaje scalony z danymi w wlslog2.sta arkusz kalkulacyjny, jak pokazano w wynikowym arkuszu kalkulacyjnym na rysunku 4.
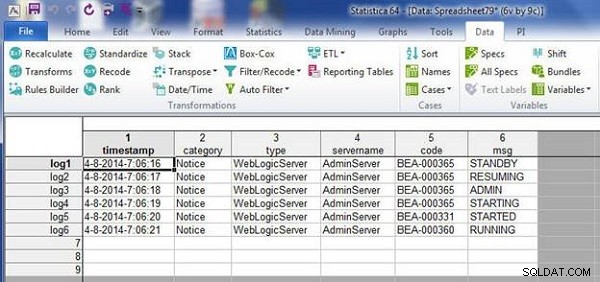
Rysunek 4: Scalony plik
Podczas scalania przez dopasowanie nazw przypadków, każdy z plików danych do scalenia musi zawierać nazwy przypadków, w przeciwnym razie zostanie wyświetlony błąd pokazany na rysunku 5.
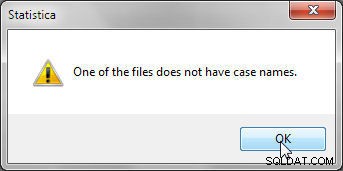
Rysunek 5: Nazwy spraw są wymagane podczas łączenia przez dopasowanie nazw spraw
Jeden arkusz kalkulacyjny może mieć więcej obserwacji (lub wierszy) niż drugi. Jako przykład dodaj 7 wierszy do wlslog1.sta (patrz rysunek 6). Kliknij Scal scalić arkusze kalkulacyjne.
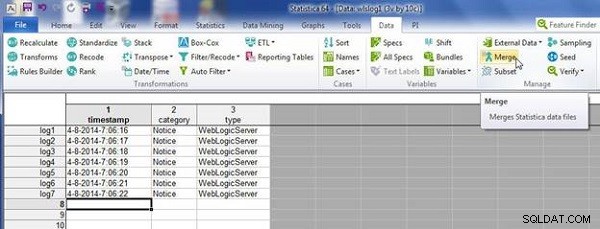
Rysunek 6: Scal z 7. rzędem w wlslog1.sta
Scal, dopasowując nazwy przypadków za pomocą wlslog2.sta , co jest takie samo jak poprzednio z 6 obserwacjami (wierszami), jak pokazano na rysunku 28. Arkusze kalkulacyjne do scalenia mają niedopasowane obserwacje (jeden arkusz kalkulacyjny ma więcej obserwacji niż drugi). Niedopasowane obserwacje są domyślnie scalane poprzez wypełnienie brakujących danych, co oznacza, że wartości danych są puste. Wynikowy arkusz kalkulacyjny zawiera puste brakujące dane dla niedopasowanych przypadków, jak pokazano na rysunku 7.
Rysunek 7: Wynikowy arkusz kalkulacyjny zawiera puste brakujące dane
Opcje scalania udostępnia kilka opcji dla Niedopasowanych przypadków inne niż wypełnienie brakujących danych. Aby zademonstrować, użyj arkusza kalkulacyjnego, wlslog1.sta , z dodatkowym wierszem i zduplikowaną nazwą sprawy (log2 ), jak pokazano na rysunku 8.
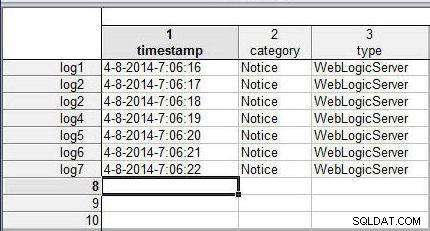
Rysunek 8: Arkusz kalkulacyjny ze zduplikowaną nazwą sprawy
Niedopasowane sprawy można usunąć, wybierając Usuń sprawy w Plik 1 Niedopasowane sprawy , jak pokazano na rysunku 9. Wiele przypadków można naprawić, wybierając opcję „Upuść plik 1 wielokrotności”. Z Trybem scalania jako Dopasuj nazwy przypadków , kliknij OK .
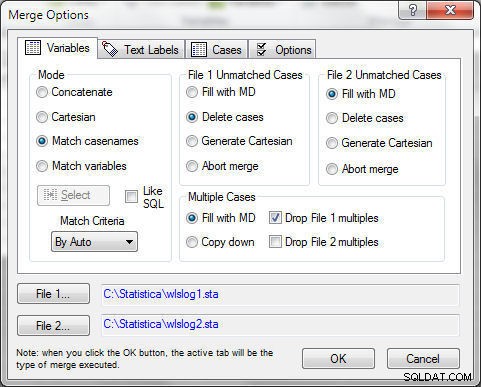
Rysunek 9: Plik 1 Unmatched Cases>Usuń sprawy
W powstałym arkuszu kalkulacyjnym oba problemy zostały naprawione. Niedopasowany przypadek jest usuwany, a duplikat jest usuwany, jak pokazano na rysunku 10.
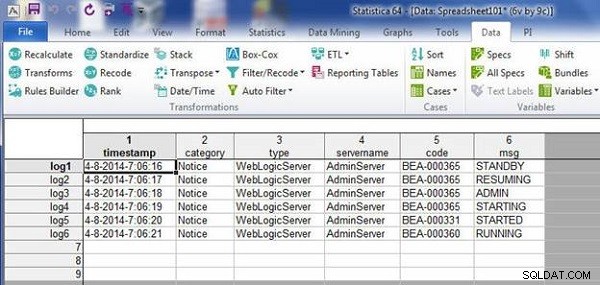
Rysunek 10: Wynikowy arkusz kalkulacyjny z usuniętą niezgodną wielkością liter i porzuconą zduplikowaną wielkością liter
Używanie nazw zmiennych do łączenia plików danych
Następnie połączymy arkusze kalkulacyjne, dopasowując nazwy zmiennych. Zacznij od dwóch arkuszy kalkulacyjnych, wlslog1.sta i wlslog2.sta , każda z nazwami kolumn pokazanymi na rysunku 11.
Rysunek 11: Nazwy kolumn w wlslog1 i wlslog2
Dodaj następujące dane do wlslog1.sta .
4-8-2014-7:06:16,Notice,WebLogicServer,AdminServer,BEA-000365, STANDBY 4-8-2014-7:06:17,Notice,WebLogicServer,AdminServer,BEA-000365, RESUMING 4-8-2014-7:06:18,Notice,WebLogicServer,AdminServer,BEA-000365, ADMIN
wlslog1.sta arkusz kalkulacyjny pokazano na rysunku 12.
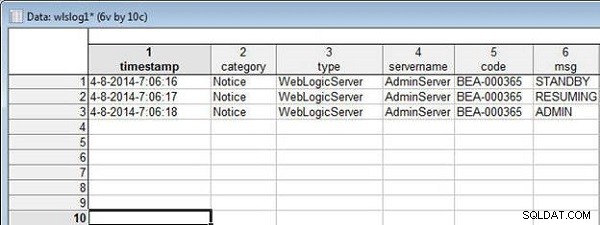
Rysunek 12: Arkusz kalkulacyjny wlslog1.sta
Dodaj następujące dane do wlslog2.sta .
4-8-2014-7:06:20,Notice,WebLogicServer,AdminServer,BEA-000331, STARTING 4-8-2014-7:06:21,Notice,WebLogicServer,AdminServer,BEA-000365, STARTED 4-8-2014-7:06:22,Notice,WebLogicServer,AdminServer,BEA-000360, RUNNING
wlslog2.sta pokazano na rysunku 13. Wybierz Dane>Scal jak poprzednio.
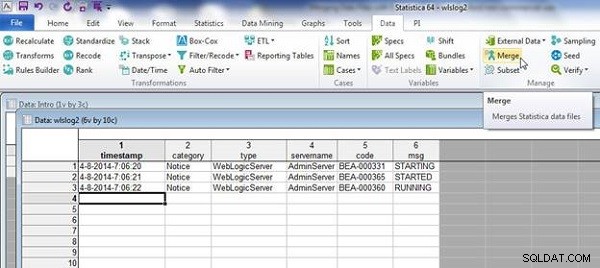
Rysunek 13: Arkusz kalkulacyjny wlslog2.sta
W Opcjach scalania , wybierz Tryb jako Dopasuj zmienne , jak pokazano na rysunku 14. Wybierz Plik 1 jako wlslog1.sta i Plik 2 jako wlslog2.sta . Kolejność jest ważna, ponieważ arkusz kalkulacyjny dodawany na dole drugiego musi być Plikem 2 . Zachowaj kryteria dopasowania jako Autom , który automatycznie wybiera najbardziej odpowiednie kryteria scalania. Inne opcje kryteriów dopasowania to Według tekstu , który porównuje dane, porównując tekst; i Liczbowo , który porównuje dane, porównując wartości liczbowe. Następnie kliknij Wybierz aby wybrać zmienne do dopasowania.
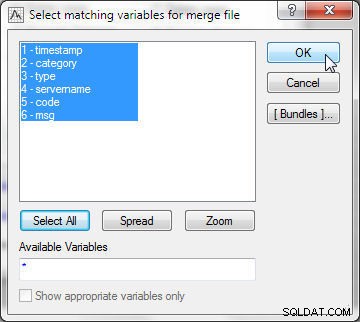
Rysunek 14: Tryb scalania jako zmienne dopasowania
Najpierw wybierz pasujące zmienne dla bieżącego pliku (Plik 1). Kliknij Zaznacz wszystko i kliknij OK, jak pokazano na rysunku 15.
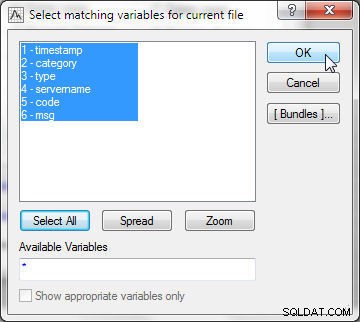
Rysunek 15: Wybieranie zmiennych w bieżącym pliku
Podobnie, wybierz wszystkie zmienne do scalenia pliku (Plik 2) i kliknij OK (patrz Rysunek 16).
Rysunek 16: Wybieranie zmiennych w pliku scalania
Kliknij OK w opcjach łączenia, jak pokazano na rysunku 17.
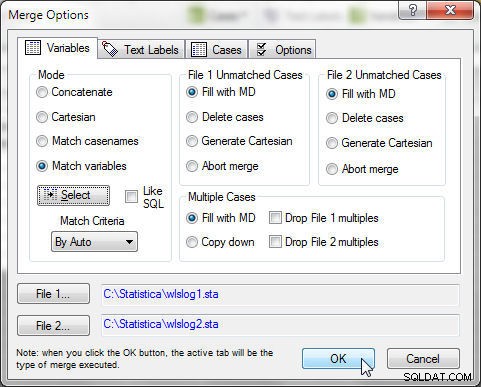
Rysunek 17: Scalanie z trybem jako zmiennymi dopasowania
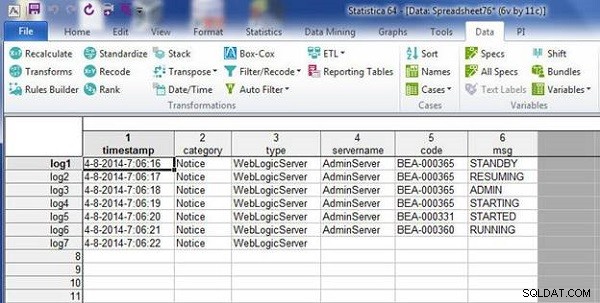
Oba arkusze kalkulacyjne zostają połączone przez dopasowanie nazw zmiennych, jak pokazano na rysunku 18.
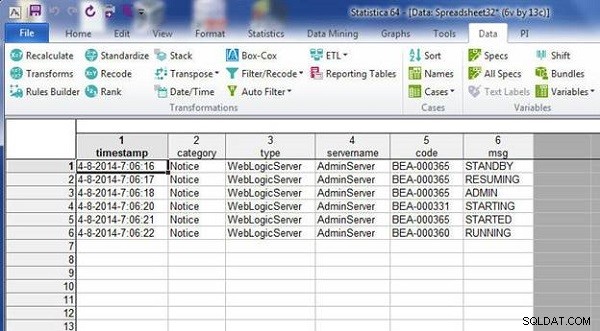
Rysunek 18: Arkusz kalkulacyjny wynikowy ze scalania przez dopasowanie nazw zmiennych
Podczas scalania arkuszy kalkulacyjnych przez dopasowanie nazw zmiennych wartości danych są sortowane numerycznie i tekstowo. Jako przykład połącz dwa arkusze kalkulacyjne z 1 arkuszem kalkulacyjnym, jak pokazano na rysunku 19.
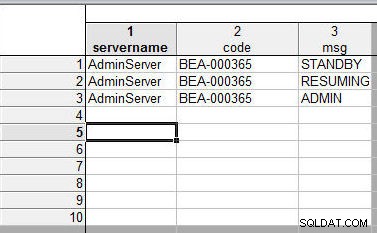
Rysunek 19: Pierwszy arkusz kalkulacyjny do scalenia
Drugi arkusz kalkulacyjny pokazano na rysunku 20. Dodana modyfikacja polega na tym, że nazwa zmiennej została nieznacznie zmodyfikowana w pliku 1:„ServerType” zamiast „servername”, „MessageCode” zamiast „code” i „Message” zamiast „ wiad”.
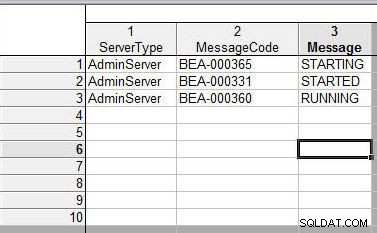
Rysunek 20: Drugi arkusz kalkulacyjny do scalenia
Kliknij Wybierz, aby wybrać zmienne, które będą używane do dopasowania. W Pliku 1 wybierz wszystkie zmienne (patrz Rysunek 21).
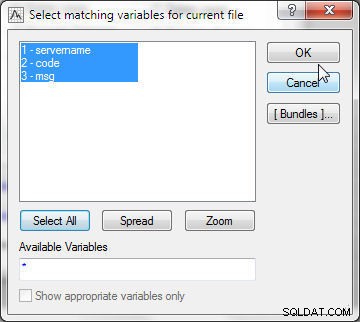
Rysunek 21: Wybieranie pasujących zmiennych dla bieżącego pliku
W Pliku 2 wybierz również wszystkie zmienne, jak pokazano na rysunku 22.
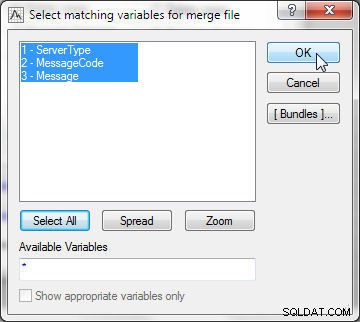
Rysunek 22: Wybieranie pasujących zmiennych do scalania pliku
Połącz oba arkusze kalkulacyjne jak poprzednio. „Nazwa serwera” lub „Typ serwera” jest taka sama dla wszystkich wierszy i nie ma wpływu na sortowanie danych w wynikowym arkuszu kalkulacyjnym. Wartości danych w kolumnach „code” lub „MessageCode” są sortowane z uwzględnieniem wielkości liter; BEA-000331 jest sortowany przed BEA-000360, który jest sortowany przed BEA-000365. Dla tej samej wartości dla kodu BEA-000365, dane w kolumnie „msg” lub „Wiadomość” są sortowane według tekstu — ADMIN->RESUMING->STANDBY>STARTING — jak pokazano na rysunku 23.
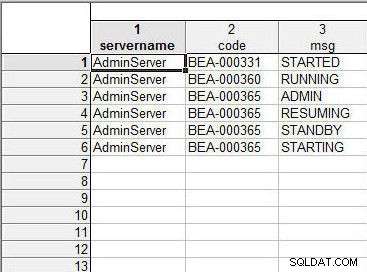
Rysunek 23: Wynikowy arkusz kalkulacyjny
Podczas wybierania zmiennych muszą być spełnione określone warunki. Co najmniej jedna zmienna musi zostać wybrana do dopasowania, w przeciwnym razie zostanie wygenerowany błąd pokazany na rysunku 24.
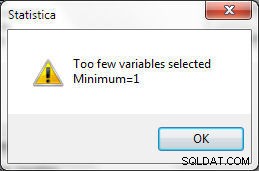
Rysunek 24: Należy wybrać co najmniej 1 zmienną
Liczba wybranych zmiennych musi być taka sama w Pliku 1 i Pliku 2, w przeciwnym razie zostanie wygenerowany błąd pokazany na rysunku 25.
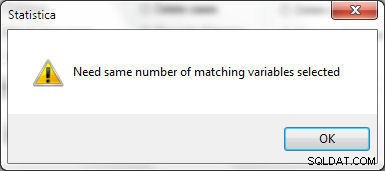
Rysunek 25: Ta sama liczba zmiennych musi być wybrana w arkuszach kalkulacyjnych do scalenia
Typ danych wybranych zmiennych musi być taki sam dla wybranych zmiennych. Na przykład zmienne „servername” i „ServerType” odpowiednio w plikach 1 i 2 muszą mieć ten sam typ danych, w przeciwnym razie zostanie wygenerowany błąd pokazany na rysunku 26.
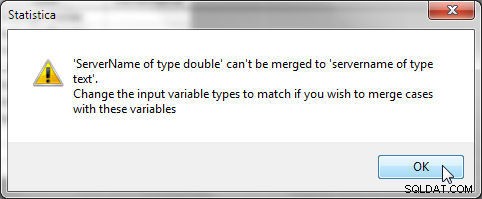
Rysunek 26: Typy zmiennych muszą być takie same podczas łączenia przez pasujące zmienne
Wniosek
W tym samouczku omówiliśmy łączenie plików danych (zwanych również arkuszami kalkulacyjnymi) w platformie Statistica przy użyciu trybów:Dopasuj nazwy przypadków i Dopasuj zmienne.