Teraz nasza społeczność zajmująca się analizą danych big data zaczęła w pełni wykorzystywać Apache Spark do przetwarzania danych big data. Przetwarzanie może dotyczyć zapytań ad-hoc, gotowych zapytań, przetwarzania wykresów, uczenia maszynowego, a nawet przesyłania strumieniowego danych.
Dlatego zrozumienie Spark Job Submission jest bardzo ważne dla społeczności. Rozszerz się na to, aby podzielić się z Tobą wiedzą na temat kroków związanych z przesyłaniem zadania Apache Spark.
Zasadniczo składa się z dwóch kroków,

Przesyłanie pracy
Zadanie Spark jest przesyłane automatycznie, gdy akcje, takie jak count(), są wykonywane na RDD.
Wewnętrznie runJob() do wywołania w SparkContext, a następnie wywołanie harmonogramu, który działa jako część pochodnej.
Harmonogram składa się z 2 części – Harmonogramu DAG i Harmonogramu zadań.
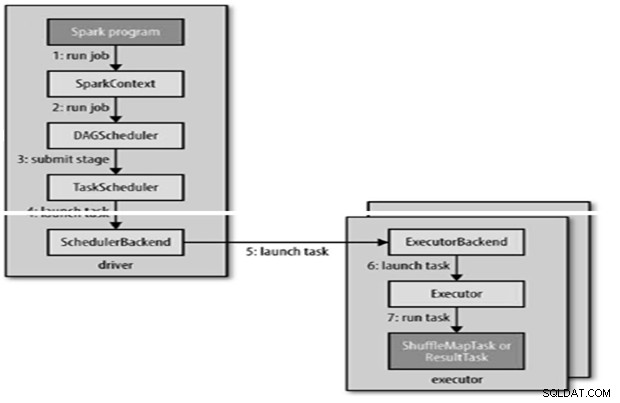
Konstrukcja DAG
Istnieją dwa rodzaje konstrukcji DAG,

- Proste zadanie Spark to takie, które nie wymaga przetasowania i dlatego ma tylko jeden etap złożony z zadań wynikowych, takich jak zadanie tylko na mapie w MapReduce
- Złożone zadanie Spark obejmuje operacje grupowe i wymaga co najmniej jednego etapu losowania.
- Program planujący DAG Sparka zamienia zadanie na dwa etapy.
- Harmonogram DAG jest odpowiedzialny za podzielenie etapu na zadania w celu przesłania do harmonogramu zadań.
- Każde zadanie otrzymuje preferencję rozmieszczenia przez harmonogram DAG, aby umożliwić harmonogramowi zadań wykorzystanie lokalizacji danych.
- Etapy potomne są przesyłane dopiero po pomyślnym ukończeniu przez rodziców.
Planowanie zadań
- Harmonogram zadań wyśle zestaw zadań; używa swojej listy executorów, które działają dla aplikacji i konstruuje mapowanie zadań na executory, które uwzględniają preferencje rozmieszczenia.
- Harmonogram zadań przypisuje executorom, które mają wolne rdzenie, do każdego zadania domyślnie przydzielany jest jeden rdzeń. Można to zmienić za pomocą parametru spark.task.cpus.
- Spark używa Akka, która jest platformą aktorską do tworzenia wysoce skalowalnych aplikacji rozproszonych sterowanych zdarzeniami.
- Spark nie używa Hadoop RPC do połączeń zdalnych.
Wykonywanie zadania
Wykonawca uruchamia zadanie w następujący sposób,
- Upewnia się, że zależności JAR i plików dla zadania są aktualne.
- Deserializuje kod zadania.
- Kod zadania jest wykonywany.
- Zadanie zwraca wyniki do sterownika, który składa się w końcowy wynik, który jest zwracany użytkownikowi.
Odniesienie
- Ostateczny przewodnik po Hadoop
- Społeczność Open Source Analytics i Big Data
Ten artykuł pierwotnie pojawił się tutaj. Opublikowane ponownie za zgodą. Tutaj możesz przesłać swoje skargi dotyczące praw autorskich.



