We wszystkich głównych produktach RDBMS klucz podstawowy w ograniczeniach SQL odgrywa kluczową rolę. Identyfikują one rekordy obecne w tabeli jednoznacznie. Dlatego powinniśmy ostrożnie wybierać serwer kluczy podstawowych podczas projektowania tabeli, aby poprawić wydajność.
W tym artykule dowiemy się, czym jest ograniczenie klucza podstawowego. Zobaczymy również, jak tworzyć, modyfikować lub usuwać ograniczenia dotyczące kluczy podstawowych.
Ograniczenia serwera SQL
W programie SQL Server Ograniczenia to zasady regulujące wprowadzanie danych do niezbędnych kolumn. Ograniczenia wymuszają dokładność danych oraz ich zgodność z wymaganiami biznesowymi. Ponadto sprawiają, że dane są wiarygodne dla użytkowników końcowych. Dlatego tak ważne jest zidentyfikowanie prawidłowych ograniczeń podczas fazy projektowania schematu bazy danych lub tabeli.
SQL Server obsługuje następujące typy ograniczeń aby wymusić integralność danych:
Podstawowe ograniczenia kluczowe są tworzone na pojedynczej kolumnie lub kombinacji kolumn w celu wymuszenia unikalności rekordów i szybszej identyfikacji rekordów. Zaangażowane kolumny nie powinny zawierać wartości NULL. Dlatego właściwość NOT NULL powinna być zdefiniowana w kolumnach.
Ograniczenia związane z kluczami zagranicznymi są tworzone na pojedynczej kolumnie lub kombinacji kolumn, aby utworzyć relację między dwiema tabelami i wymusić dane znajdujące się w jednej tabeli do drugiej. W idealnym przypadku kolumny tabeli, w których musimy wymusić dane z ograniczeniami klucza obcego, odnoszą się do tabeli źródłowej z kluczem podstawowym w SQL lub ograniczeniem klucza unikalnego. Innymi słowy, tylko rekordy dostępne w ograniczeniach klucza podstawowego lub unikalnego tabeli źródłowej mogą być wstawiane lub aktualizowane do tabeli docelowej.
Unikalne kluczowe ograniczenia są tworzone na pojedynczej kolumnie lub kombinacji kolumn, aby wymusić unikalność danych w kolumnie. Są one podobne do ograniczeń klucza podstawowego z jedną zmianą. Różnica między kluczem podstawowym a unikalnymi ograniczeniami klucza polega na tym, że ten ostatni można utworzyć na Nullable kolumn i zezwól na jeden rekord wartości NULL w swojej kolumnie.
Sprawdź ograniczenia są tworzone na pojedynczej kolumnie lub kombinacji kolumn przez ograniczenie akceptowanych wartości danych dla kolumn biorących udział w wyrażeniu logicznym. Istnieje różnica między kluczem obcym a ograniczeniami czeku. Klucz obcy wymusza integralność danych, sprawdzając dane z klucza podstawowego lub unikatowego innej tabeli. Jednak sprawdzanie ograniczenia robi to za pomocą wyrażenia logicznego.
Przejdźmy teraz przez podstawowe ograniczenia klucza.
Podstawowe ograniczenie klucza
Ograniczenie klucza podstawowego wymusza unikalność pojedynczej kolumny lub kombinacji kolumn bez wartości NULL wewnątrz zaangażowanych kolumn.
Aby wymusić unikalność, SQL Server tworzy unikalny indeks klastrowy w kolumnach, w których utworzono klucze podstawowe. Jeśli istnieją jakiekolwiek indeksy klastrowe, SQL Server tworzy unikalny indeks nieklastrowy w tabeli dla klucza podstawowego.
Zobaczmy, jak tworzymy, modyfikujemy, usuwamy, wyłączamy lub włączamy klucze podstawowe w tabeli za pomocą skryptów T-SQL.
Utwórz klucz podstawowy
Klucze podstawowe możemy tworzyć w tabeli zarówno podczas tworzenia tabeli, jak i później. Składnia różni się nieznacznie w tych scenariuszach.
Tworzenie klucza podstawowego podczas tworzenia tabeli
Składnia jest poniżej:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Utwórzmy tabelę o nazwie Pracownicy w Zasobach ludzkich schemat do celów testowych za pomocą poniższego skryptu:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
Pomyślnie utworzyliśmy HumanResources.Employees stół w AdventureWorks baza danych:
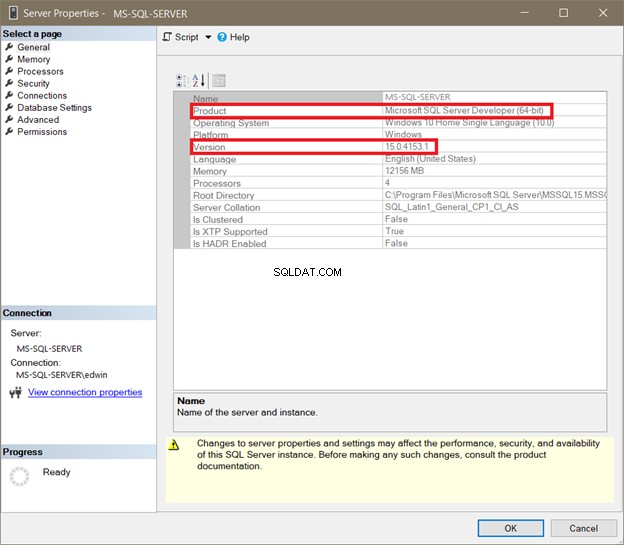
Widzimy, że indeks klastrowy został utworzony w tabeli pasującej do nazwy klucza podstawowego, jak podkreślono powyżej.
Usuńmy tabelę za pomocą poniższego skryptu i spróbujmy ponownie z nową składnią.
DROP TABLE HumanResources.EmployeesAby utworzyć klucz podstawowy w SQL w tabeli ze zdefiniowaną przez użytkownika nazwą klucza podstawowego PK_Employees , użyj poniższej składni:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
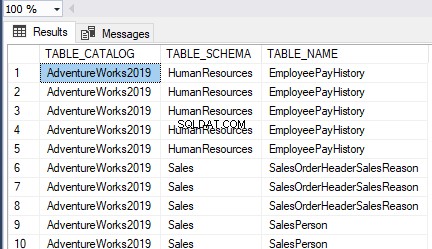
Stworzyliśmy HumanResources.Employees tabela z nazwą klucza podstawowego PK_Employees :
Tworzenie klucza podstawowego po utworzeniu tabeli
Czasami programiści lub administratorzy baz danych zapominają o kluczach podstawowych i tworzą tabele bez nich. Ale możliwe jest utworzenie klucza podstawowego w istniejących tabelach.
Odrzućmy HumanResources.Employees tabeli i odtwórz ją za pomocą poniższego skryptu:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Po pomyślnym wykonaniu tego skryptu możemy zobaczyć HumanResources.Employees tabela utworzona bez żadnych kluczy podstawowych ani indeksów:

Aby utworzyć klucz podstawowy o nazwie PK_Employees w tej tabeli użyj poniższej składni:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
Wykonanie tego skryptu tworzy klucz podstawowy na naszej tabeli:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Tworzenie klucza podstawowego w wielu kolumnach
W naszych przykładach utworzyliśmy klucze podstawowe w pojedynczych kolumnach. Jeśli chcemy utworzyć klucze podstawowe w wielu kolumnach, potrzebujemy innej składni.
Aby dodać wiele kolumn jako część klucza podstawowego, musimy po prostu dodać wartości oddzielone przecinkami w nazwach kolumn, które powinny być częścią klucza podstawowego.
Klucz podstawowy podczas tworzenia tabeli
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Klucz podstawowy po utworzeniu tabeli
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Upuść klucz podstawowy
Aby usunąć klucz podstawowy, używamy poniższej składni. Nie ma znaczenia, czy klucz podstawowy znajdował się w jednej czy wielu kolumnach.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
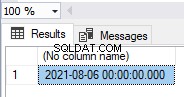
Aby usunąć ograniczenie klucza podstawowego na HumanResources.Employees tabeli, użyj poniższego skryptu:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Upuszczenie klucza podstawowego usuwa zarówno klucze podstawowe, jak i indeksy klastrowe lub nieklastrowe utworzone wraz z tworzeniem klucza podstawowego:
Zmień klucz podstawowy
W SQL Server nie ma bezpośrednich poleceń do modyfikowania kluczy podstawowych. Musimy usunąć istniejący klucz podstawowy i odtworzyć go z niezbędnymi modyfikacjami. Dlatego kroki, aby zmodyfikować klucz podstawowy to:
- Upuść istniejący klucz podstawowy.
- Utwórz nowe klucze podstawowe z niezbędnymi zmianami.
Wyłącz/włącz klucz podstawowy
Podczas ładowania zbiorczego tabeli z wieloma rekordami wyłącz klucz podstawowy i włącz go ponownie, aby uzyskać lepszą wydajność. Kroki są poniżej:
Wyłącz istniejący klucz podstawowy za pomocą poniższej składni:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;Aby wyłączyć klucz podstawowy na HumanResources.Employees tabela, skrypt to:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Włącz istniejące klucze podstawowe, które są w stanie wyłączonym. Musimy ODBUDOWAĆ indeks, używając poniższej składni:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;Aby włączyć klucz podstawowy na HumanResources.Employees tabeli, użyj następującego skryptu:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
Mity na temat klucza podstawowego
Wiele osób jest zdezorientowanych poniższymi mitami związanymi z kluczami podstawowymi w SQL Server.
- Tabela z kluczem podstawowym nie jest tabelą sterty
- Klucze podstawowe mają indeks klastrowy i dane posortowane w porządku fizycznym
Wyjaśnijmy je.
Tabela z kluczem podstawowym nie jest tabelą sterty
Zanim zagłębimy się głębiej, zrewidujmy definicję klucza podstawowego i tabeli sterty.
Klucz podstawowy tworzy indeks klastrowany w tabeli, jeśli nie ma tam innych indeksów klastrowanych. Tabela bez indeksu klastrowego będzie tabelą sterty.
Na podstawie tych definicji możemy zrozumieć, że klucz podstawowy tworzy indeks klastrowy tylko wtedy, gdy w tabeli nie ma innych indeksów klastrowych. Jeśli istnieją jakiekolwiek indeksy klastrowe, utworzenie klucza podstawowego spowoduje utworzenie indeksu nieklastrowego w tabeli odpowiadającego kluczowi głównemu.
Zweryfikujmy to, upuszczając HumanResources.Employees Stół i jego odtworzenie:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Możemy określić opcję indeksu NOCLUSTERED dla klucza podstawowego (patrz wyżej). Utworzono tabelę z unikalnym, nieklastrowym indeksem dla podstawowego klucza PK_Employees .
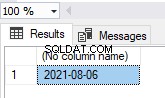
Dlatego ta tabela jest tabelą sterty, mimo że ma klucz główny.
Zobaczmy, czy SQL Server może utworzyć indeks nieklastrowy dla klucza podstawowego, jeśli nie określimy słowa kluczowego Nieklastrowy podczas tworzenia klucza podstawowego. Użyj poniższego skryptu:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
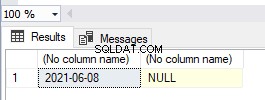
Tutaj utworzyliśmy osobno indeks klastrowy przed utworzeniem klucza podstawowego. A tabela może mieć tylko jeden indeks klastrowy. Dlatego SQL Server utworzył klucz podstawowy jako unikalny, nieklastrowany indeks. W tej chwili tabela nie jest tabelą sterty, ponieważ ma indeks klastrowy.
Jeśli zmienię zdanie i porzucę indeks klastrowy na First_Name i Last_Name kolumny za pomocą poniższego skryptu:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Pomyślnie usunęliśmy indeks klastrowy. Zasoby ludzkie.Pracownicy table jest tabelą sterty, mimo że w tabeli dostępny jest klucz podstawowy:
To wyjaśnia mit, że tabela z kluczem podstawowym może być tabelą sterty, jeśli w tabeli nie ma dostępnych indeksów klastrowych.
Klucz podstawowy będzie miał indeks klastrowy i dane posortowane w porządku fizycznym
Jak dowiedzieliśmy się z poprzedniego przykładu, klucz podstawowy w SQL może mieć indeks nieklastrowy. W takim przypadku rekordy nie byłyby posortowane w porządku fizycznym.
Zweryfikujmy tabelę z indeksem klastrowym na kluczu podstawowym. Zamierzamy sprawdzić, czy sortuje rekordy w porządku fizycznym.
Odtwórz HumanResources.Employees tabela z minimalną ilością kolumn i właściwością IDENTITY usuniętą dla Identyfikator pracownika kolumna:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Teraz, gdy utworzyliśmy tabelę bez klucza podstawowego lub indeksu klastrowego, możemy WSTAWIĆ 3 rekordy w nieposortowanej kolejności dla Identyfikatora_pracownika kolumna:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Wybierzmy spośród HumanResources.Employees tabela:
SELECT *
FROM HumanResources.Employees
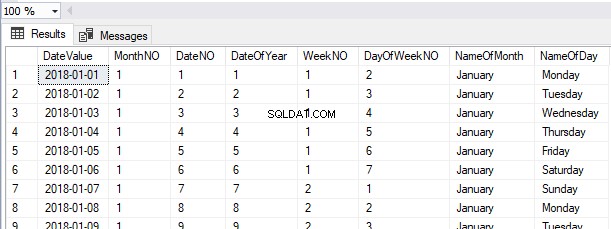
Możemy zobaczyć rekordy pobrane w tej samej kolejności, co rekordy wstawione w tej chwili z tabeli Sterta.
Utwórzmy klucz podstawowy w tej tabeli sterty i zobaczmy, czy ma on jakikolwiek wpływ na instrukcję SELECT:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Po utworzeniu klucza podstawowego widzimy, że instrukcja SELECT pobrała rekordy w kolejności rosnącej Identyfikator_pracownika (kolumna klucza podstawowego). Wynika to z klastrowanego indeksu na Employee_Id .
Jeśli klucz podstawowy zostanie utworzony z opcją nieklastrowaną, dane tabeli nie będą sortowane na podstawie kolumny Klucz podstawowy.
Jeśli długość pojedynczego rekordu w tabeli przekracza 4030 bajtów, tylko jeden rekord może zmieścić się na stronie. Indeks klastrowy zapewnia, że strony są w porządku fizycznym.
Strona jest podstawową jednostką przechowywania w plikach danych programu SQL Server o rozmiarze 8 KB (8192 bajtów). Tylko 8060 bajtów tej jednostki nadaje się do przechowywania danych. Pozostała kwota jest przeznaczona na nagłówki stron i inne elementy wewnętrzne.
Wskazówki dotyczące wyboru głównych kolumn kluczowych
- Kolumny typu danych całkowitych najlepiej nadają się do kolumn klucza podstawowego, ponieważ zajmują mniejsze rozmiary pamięci i mogą pomóc w szybszym pobieraniu danych.
- Ponieważ kolumny klucza podstawowego mają domyślnie indeks klastrowy, użyj opcji IDENTITY w kolumnach o typie danych całkowitych, aby nowe wartości były generowane w kolejności przyrostowej.
- Zamiast tworzyć klucz podstawowy w wielu kolumnach, utwórz nową kolumnę liczb całkowitych ze zdefiniowaną właściwością IDENTITY. Ponadto utwórz unikalny indeks w wielu kolumnach, które zostały pierwotnie zidentyfikowane w celu uzyskania lepszej wydajności.
- Staraj się unikać kolumn z typami danych typu string, takimi jak varchar, nvarchar itp. Nie możemy zagwarantować sekwencyjnego przyrostu danych w tych typach danych. Może to wpłynąć na wydajność INSERT w tych kolumnach.
- Wybierz kolumny, w których wartości nie będą aktualizowane jako klucze podstawowe. Na przykład, jeśli wartość klucza podstawowego może zmienić się z 5 na 1000, drzewo B skojarzone z indeksem klastrowym musi zostać zaktualizowane, co spowoduje niewielki spadek wydajności.
- Jeśli kolumny typu danych ciągu muszą być wybrane jako kolumny klucza podstawowego, upewnij się, że długość kolumn typu danych varchar lub nvarchar pozostaje mała, aby uzyskać lepszą wydajność.
Wniosek
Przeszliśmy przez podstawy ograniczeń dostępnych w SQL Server. Przeanalizowaliśmy szczegółowo ograniczenia klucza podstawowego i dowiedzieliśmy się, jak tworzyć, usuwać, modyfikować, wyłączać i odbudowywać klucze podstawowe. Ponadto wyjaśniliśmy niektóre popularne mity dotyczące kluczy podstawowych za pomocą przykładów.
Czekajcie na następny artykuł!