Bazy danych szeregów czasowych, jak sama nazwa wskazuje, są przeznaczone do przechowywania danych, które zmieniają się w czasie. Mogą to być dowolne dane, które zostały zebrane w czasie. Mogą to być metryki zebrane z niektórych systemów, a właściwie wszystkie systemy trendów są przykładami danych szeregów czasowych.
Mamy różne typy baz danych szeregów czasowych, których powinniśmy użyć?
W tym blogu zobaczymy, jakie są główne różnice między dwiema głównymi opcjami, TimescaleDB i InfluxDB.
InfluxDB
InfluxDB został stworzony przez InfluxData. Jest to niestandardowa baza danych typu open source, oparta na szeregach czasowych NoSQL, napisana w Go. Magazyn danych zapewnia podobny do SQL język do wykonywania zapytań o dane, zwany InfluxQL, który ułatwia programistom integrację z ich aplikacjami. Ma również nowy niestandardowy język zapytań o nazwie Flux, który może ułatwić niektóre zadania, ale zawsze jest krzywa uczenia się przy przyjmowaniu niestandardowego języka zapytań.
To jest przykład zapytania Flux:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()W tej bazie danych każdy pomiar ma sygnaturę czasową oraz powiązany zestaw tagów i zestaw pól. Pole reprezentuje rzeczywiste wartości odczytu pomiaru, podczas gdy znacznik reprezentuje metadane opisujące pomiary. Typy danych pól są ograniczone do zmiennoprzecinkowych, int, łańcuchów i wartości logicznych i nie można ich zmienić bez przepisania danych. Wartości tagów są indeksowane. Są reprezentowane jako ciągi i nie mogą być aktualizowane.
InfluxDB jest dość łatwy do rozpoczęcia, ponieważ nie musisz się martwić tworzeniem schematów lub indeksów. Jest jednak dość sztywny i ograniczony, bez możliwości tworzenia dodatkowych indeksów, indeksów na polach ciągłych, aktualizacji metadanych po fakcie, wymuszania walidacji danych itp.
Nie jest pozbawiony schematu. Istnieje podstawowy schemat, który jest tworzony automatycznie na podstawie danych wejściowych.
InfluxDB musi zaimplementować od podstaw kilka narzędzi zapewniających odporność na awarie, takich jak replikacja, wysoka dostępność i tworzenie kopii zapasowych/przywracanie, a także odpowiada za niezawodność na dysku. Ograniczamy się do korzystania z tych narzędzi, a wiele z tych funkcji, takich jak HA, jest dostępnych tylko w wersji Enterprise.
Narzędzie do tworzenia kopii zapasowych InfluxDB może wykonać pełną lub przyrostową kopię zapasową i może być używane do odzyskiwania do określonego momentu.
InfluxDB oferuje również znacznie lepszą kompresję na dysku niż PostgreSQL i TimescaleDB.
Baza danych skali czasu
TimescaleDB to baza danych szeregów czasowych typu open source zoptymalizowana pod kątem szybkiego pozyskiwania i złożonych zapytań, która obsługuje pełny SQL. Jest oparty na PostgreSQL i oferuje najlepsze ze światów NoSQL i relacyjnych dla danych szeregów czasowych.
To jest przykład zapytania TimescaleDB:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, jako rozszerzenie PostgreSQL, jest relacyjną bazą danych. Pozwala to na uzyskanie krótkiej krzywej uczenia się dla nowych użytkowników i dziedziczenie narzędzi, takich jak pg_dump lub pg_backup do tworzenia kopii zapasowych, oraz narzędzi wysokiej dostępności, co jest zaletą w porównaniu z innymi bazami danych szeregów czasowych. Obsługuje również replikację strumieniową jako podstawową metodę replikacji, która może być używana w konfiguracji o wysokiej dostępności. Jeśli chodzi o przełączanie awaryjne i tworzenie kopii zapasowych, możesz zautomatyzować ten proces, korzystając z zewnętrznego systemu, takiego jak ClusterControl.
W TimescaleDB każdy pomiar szeregu czasowego jest rejestrowany w osobnym wierszu, z polem czasu, po którym następuje dowolna liczba innych pól, które mogą być zmiennoprzecinkowe, wartości wewnętrzne, łańcuchy, wartości logiczne, tablice, obiekty blob JSON, wymiary geoprzestrzenne, data/godzina/ znaczniki czasu, waluty, dane binarne i inne.
Możesz tworzyć indeksy dla dowolnego pola (indeksy standardowe) lub wielu pól (indeksy złożone) lub wyrażeń takich jak funkcje, a nawet ograniczyć indeks do podzbioru wierszy (indeks częściowy). Każde z tych pól może być używane jako klucz obcy do tabel wtórnych, w których można następnie przechowywać dodatkowe metadane.
W ten sposób musisz wybrać schemat i zdecydować, które indeksy będą potrzebne w Twoim systemie.
Wydajność
Jeśli mówimy o wydajności, możemy sprawdzić świetny blog porównujący TimescaleDB. Tam masz szczegółowe porównanie wydajności obu baz danych z wykresami i metrykami. Zobaczmy niektóre z najważniejszych informacji z tego bloga.
Wkładki
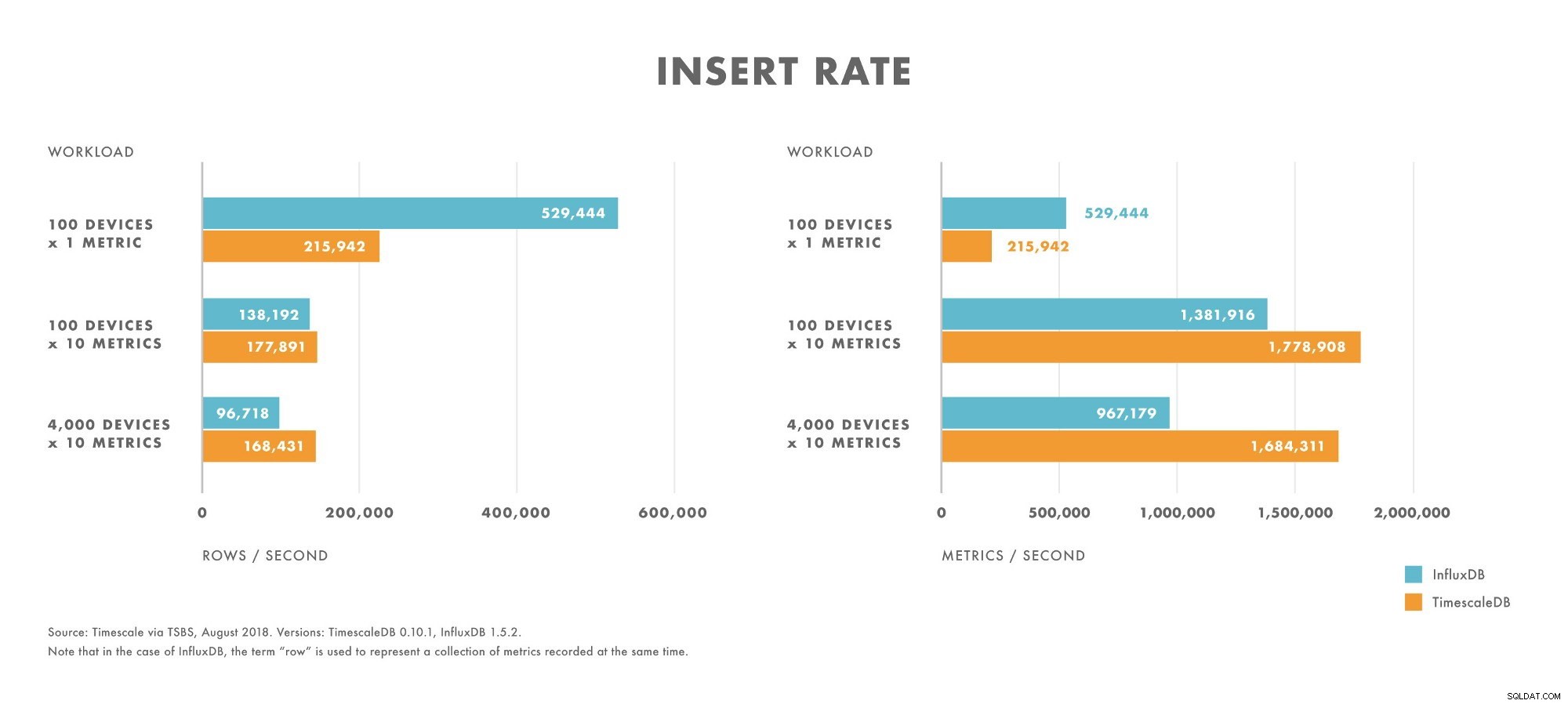
- W przypadku obciążeń o bardzo niskiej kardynalności (np. 100 urządzeń) InfluxDB przewyższa TimescaleDB.
- Wraz ze wzrostem kardynalności wydajność wstawiania InfluxDB spada szybciej niż w TimescaleDB.
- W przypadku obciążeń o średniej do wysokiej kardynalności (np. 100 urządzeń wysyłających 10 metryk) TimescaleDB przewyższa InfluxDB.

Opóźnienie odczytu
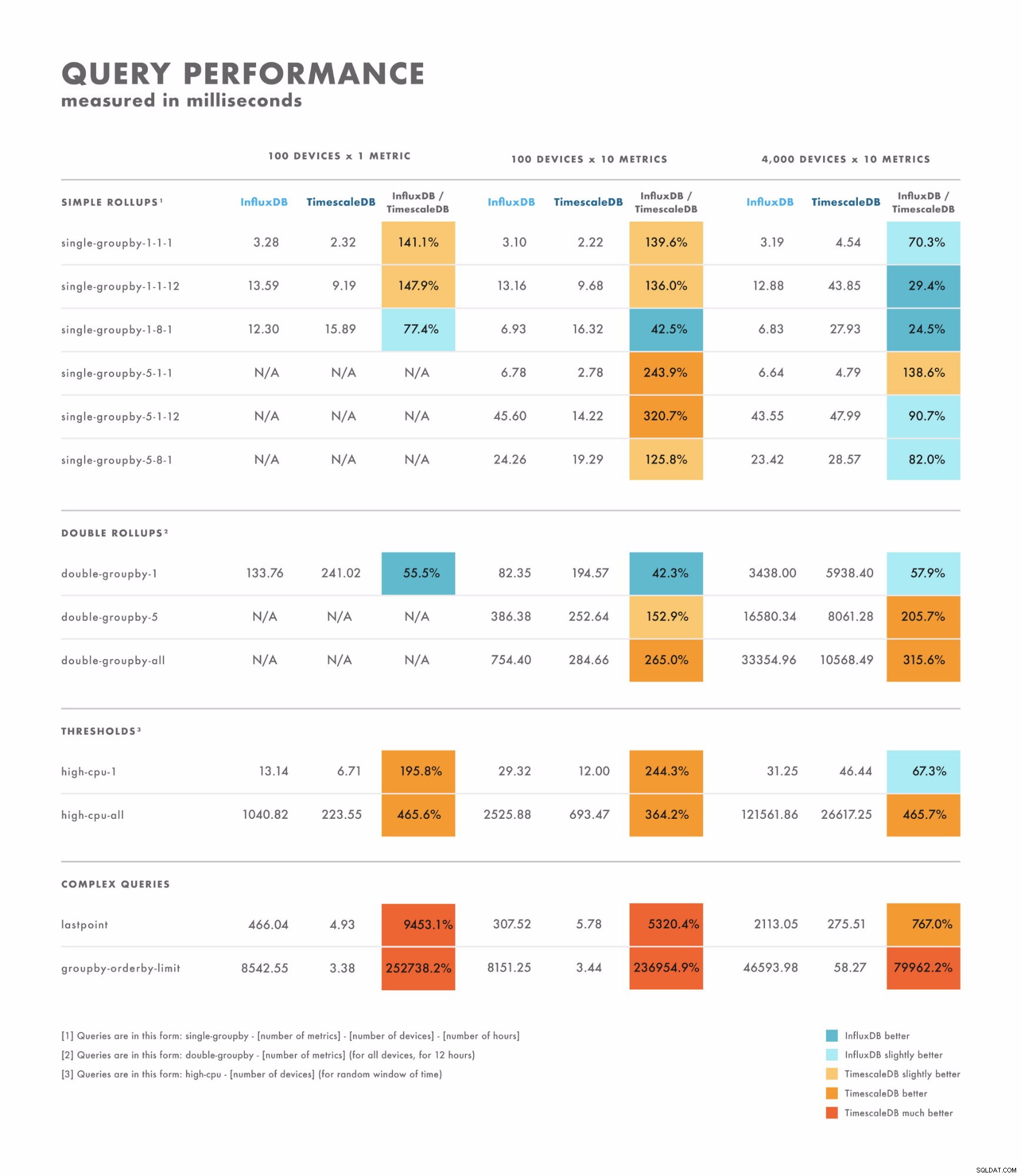
- W przypadku prostych zapytań wyniki różnią się nieco:w niektórych przypadkach jedna baza danych jest wyraźnie lepsza od drugiej, podczas gdy inne zależą od liczności zbioru danych. Różnica często mieści się w zakresie od jednocyfrowych do dwucyfrowych milisekund.
- W przypadku złożonych zapytań TimescaleDB znacznie przewyższa InfluxDB i obsługuje szerszy zakres typów zapytań. Różnica często waha się od kilku sekund do kilkudziesięciu sekund.
- Mając to na uwadze, najlepszym sposobem prawidłowego testowania jest porównanie z zapytaniami, które planujesz wykonać.
Problemy ze stabilnością
- InfluxDB ma problemy ze stabilnością i wydajnością przy wysokich kardynalnościach (100K+).
Wniosek
Jeśli Twoje dane pasują do modelu danych InfluxDB i nie spodziewasz się zmian w przyszłości, powinieneś rozważyć użycie InfluxDB, ponieważ ten model jest łatwiejszy do rozpoczęcia i podobnie jak większość baz danych, które używają podejścia zorientowanego na kolumny, oferuje lepszą kompresję na dysku niż PostgreSQL i TimescaleDB.
Jednak model relacyjny jest bardziej wszechstronny i oferuje większą funkcjonalność, elastyczność i kontrolę niż model InfluxDB. Jest to szczególnie ważne, gdy Twoja aplikacja ewoluuje. Planując swój system, należy wziąć pod uwagę zarówno jego obecne, jak i przyszłe potrzeby.
Na tym blogu mogliśmy zobaczyć krótkie porównanie między TimescaleDB i InfluxDB i możemy powiedzieć, że TimescaleDB jako rozszerzenie PostgreSQL wygląda dość dojrzale i ma wiele funkcji, ponieważ dziedziczy wiele z PostgreSQL. Ale możesz podjąć własną decyzję w oparciu o zalety i wady wspomniane wcześniej na tym blogu i upewnić się, że porównałeś własne obciążenie pracą. Powodzenia w tym nowym świecie baz danych szeregów czasowych!