W dzisiejszych czasach replikacja jest zapewniona w środowisku o wysokiej dostępności i odpornym na błędy w przypadku prawie każdej używanej technologii baz danych. Jest to temat, który wielokrotnie widzieliśmy, ale nigdy się nie starzeje.
Jeśli używasz TimescaleDB, najpopularniejszym typem replikacji jest replikacja strumieniowa, ale jak to działa?
W tym blogu omówimy niektóre koncepcje związane z replikacją i skupimy się na replikacji strumieniowej dla TimescaleDB, która jest funkcją odziedziczoną z bazowego silnika PostgreSQL. Następnie zobaczymy, jak ClusterControl może nam pomóc w jego konfiguracji.
Tak więc replikacja strumieniowa opiera się na przesłaniu rekordów WAL i zastosowaniu ich do serwera rezerwowego. Więc najpierw zobaczmy, czym jest WAL.
WAL
Dziennik zapisu z wyprzedzeniem (WAL) to standardowa metoda zapewniania integralności danych, która jest domyślnie włączona automatycznie.
WAL to dzienniki REDO w TimescaleDB. Ale czym są dzienniki REDO?
Dzienniki REDO zawierają wszystkie zmiany, które zostały wprowadzone w bazie danych i są wykorzystywane przez replikację, odzyskiwanie, tworzenie kopii zapasowych online oraz odzyskiwanie do punktu w czasie (PITR). Wszelkie zmiany, które nie zostały zastosowane na stronach danych, można ponownie wykonać w dziennikach REDO.
Użycie WAL skutkuje znacznie zmniejszoną liczbą zapisów na dysku, ponieważ tylko plik dziennika musi zostać opróżniony na dysk, aby zagwarantować, że transakcja jest zatwierdzona, a nie każdy plik danych zmieniony przez transakcję.
Rekord WAL będzie określał, bit po bicie, zmiany dokonane w danych. Każdy rekord WAL zostanie dołączony do pliku WAL. Pozycja wstawiania to numer sekwencji dziennika (LSN), który jest bajtowym przesunięciem w dziennikach, rosnącym z każdym nowym rekordem.
WAL są przechowywane w katalogu pg_wal, w katalogu danych. Pliki te mają domyślny rozmiar 16 MB (rozmiar można zmienić, zmieniając opcję konfiguracji --with-wal-segsize podczas budowania serwera). Mają unikalną nazwę przyrostową w następującym formacie:„0000001 00000000 00000000”.
Liczba plików WAL zawartych w pg_wal będzie zależeć od wartości przypisanej do parametrów min_wal_size i max_wal_size w pliku konfiguracyjnym postgresql.conf.
Jednym z parametrów, który musimy ustawić podczas konfigurowania wszystkich naszych instalacji TimescaleDB, jest wal_level. Określa, ile informacji jest zapisywanych w WAL. Wartość domyślna to minimalna, która zapisuje tylko informacje potrzebne do odzyskania systemu po awarii lub natychmiastowym zamknięciu. Archiwum dodaje rejestrowanie wymagane do archiwizacji WAL; hot_standby dodatkowo dodaje informacje wymagane do uruchamiania zapytań tylko do odczytu na serwerze rezerwowym; i wreszcie logiczne dodaje informacje niezbędne do obsługi logicznego dekodowania. Ten parametr wymaga ponownego uruchomienia, więc jeśli o tym zapomnieliśmy, zmiana może być trudna przy uruchomionych produkcyjnych bazach danych.
Replikacja strumieniowa
Replikacja strumieniowa jest oparta na metodzie przesyłania dziennika. Rekordy WAL są przenoszone bezpośrednio z jednego serwera bazy danych na inny w celu zastosowania. Można powiedzieć, że jest to ciągły PITR.
Ten transfer jest wykonywany na dwa różne sposoby, poprzez przesyłanie rekordów WAL do jednego pliku (segment WAL) na raz (przesyłanie dziennika opartego na plikach) oraz przez przesyłanie rekordów WAL (plik WAL składa się z rekordów WAL) w locie (na podstawie rekordów). przesyłanie dziennika), między serwerem głównym a jednym lub kilkoma serwerami podrzędnymi, bez oczekiwania na wypełnienie pliku WAL.
W praktyce proces zwany odbiornikiem WAL, działający na serwerze podrzędnym, połączy się z serwerem głównym za pomocą połączenia TCP/IP. Na serwerze głównym istnieje inny proces o nazwie WAL sender, który odpowiada za wysyłanie rejestrów WAL do serwera podrzędnego na bieżąco.
Replikację strumieniową można przedstawić w następujący sposób:
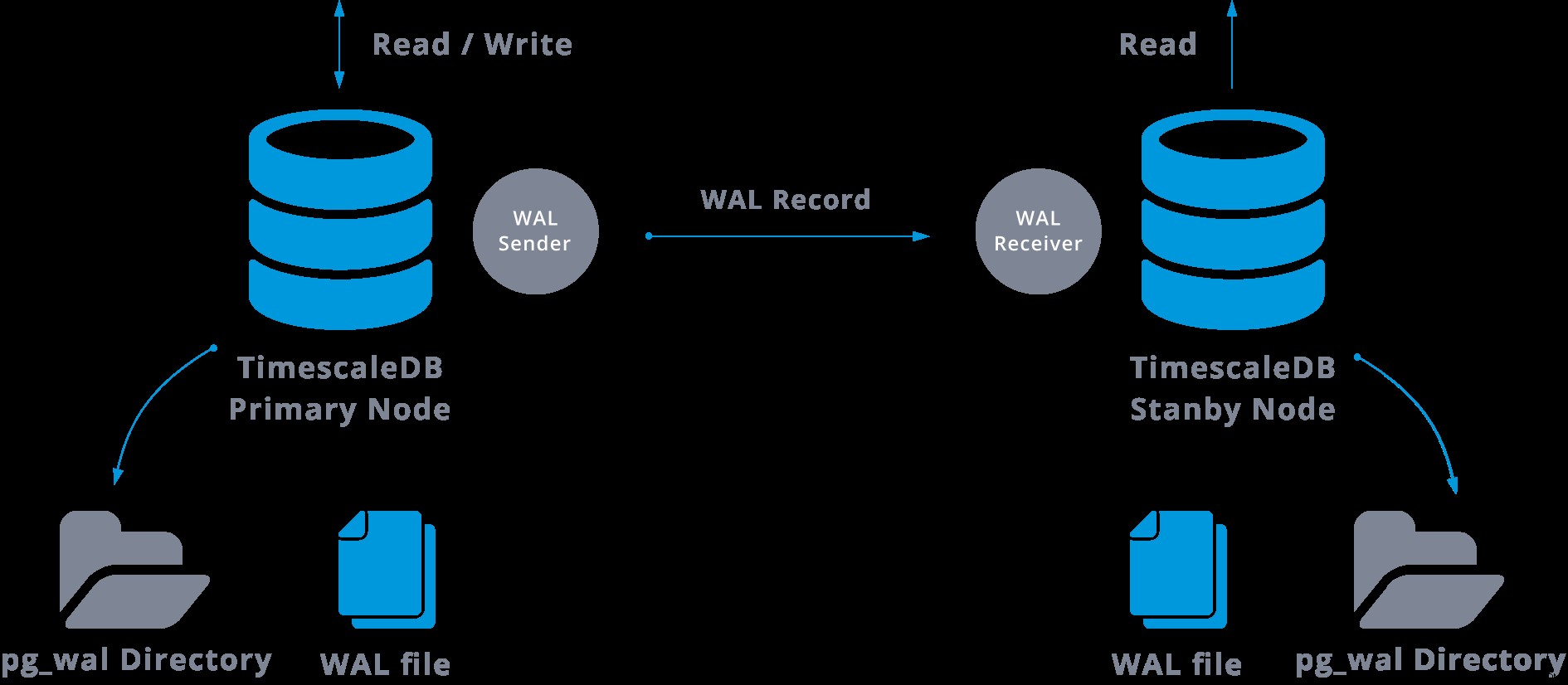
Patrząc na powyższy diagram, możemy pomyśleć, co się stanie, gdy komunikacja między nadawcą WAL a odbiorcą WAL zawiedzie?
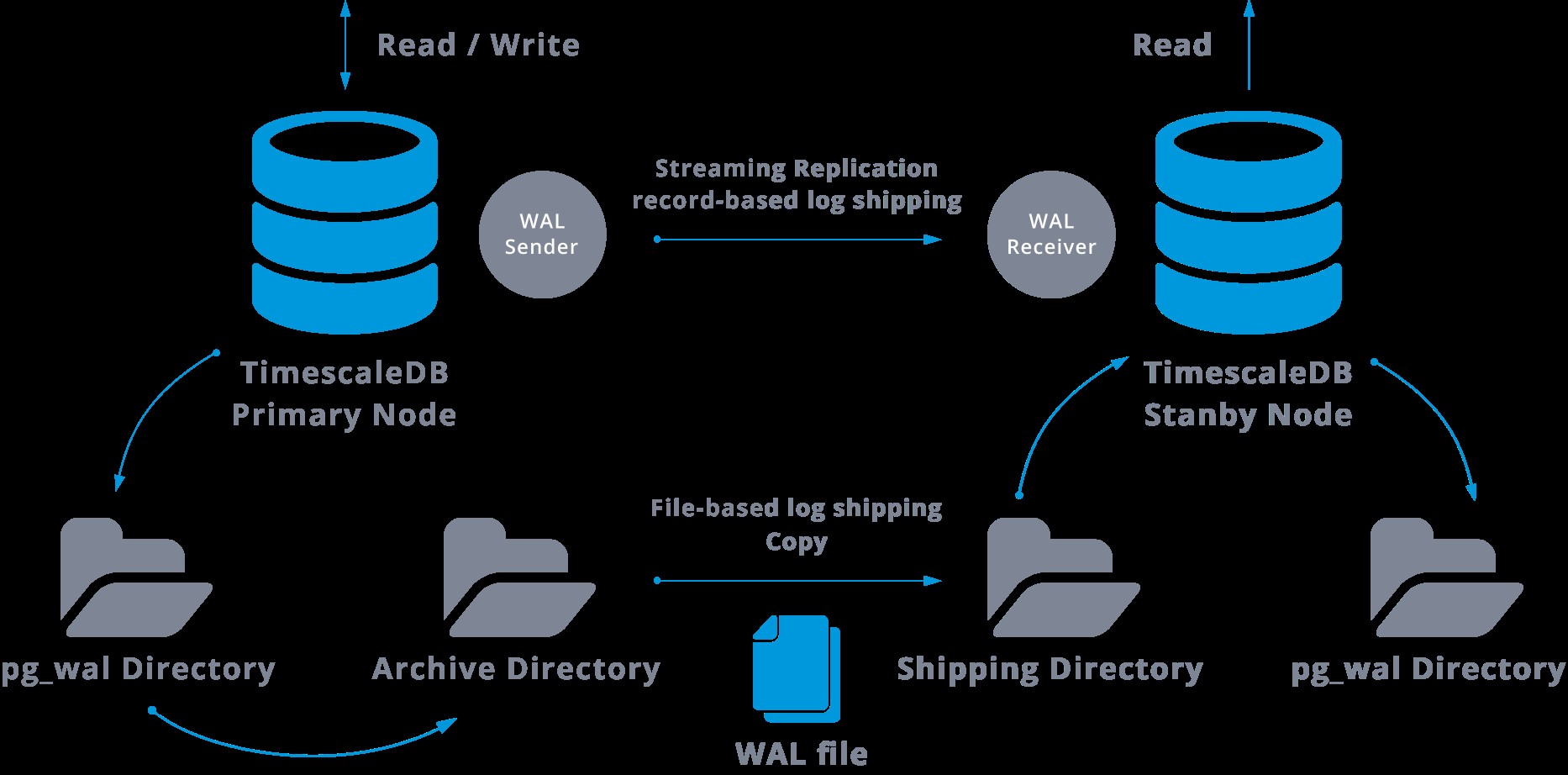
Podczas konfigurowania replikacji strumieniowej mamy możliwość włączenia archiwizacji WAL.
Ten krok w rzeczywistości nie jest obowiązkowy, ale jest niezwykle ważny dla niezawodnej konfiguracji replikacji, ponieważ konieczne jest uniknięcie ponownego wykorzystywania przez serwer główny starych plików WAL, które nie zostały jeszcze zastosowane do urządzenia podrzędnego. Jeśli tak się stanie, będziemy musieli odtworzyć replikę od zera.
Konfigurując replikację z ciągłą archiwizacją, zaczynamy od kopii zapasowej i aby osiągnąć stan synchronizacji z urządzeniem głównym, musimy zastosować wszystkie zmiany hostowane w warstwie WAL, które nastąpiły po wykonaniu kopii zapasowej. Podczas tego procesu stan gotowości najpierw odtworzy wszystkie pliki WAL dostępne w lokalizacji archiwum (wywołując polecenie restore_command). Restore_command nie powiedzie się, gdy dotrzemy do ostatniego zarchiwizowanego rekordu WAL, więc następnie rezerwa będzie sprawdzać w katalogu pg_wal, czy istnieje tam zmiana (jest to faktycznie wykonywane, aby uniknąć utraty danych w przypadku awarii serwerów głównych i niektórych zmiany, które zostały już przeniesione do repliki i tam zastosowane, nie zostały jeszcze zarchiwizowane).
Jeśli to się nie powiedzie, a żądany rekord tam nie istnieje, rozpocznie komunikację z urządzeniem głównym poprzez replikację strumieniową.
W przypadku niepowodzenia replikacji strumieniowej nastąpi powrót do kroku 1 i ponowne przywrócenie rekordów z archiwum. Ta pętla pobierania danych z archiwum, pg_wal i replikacji strumieniowej trwa do momentu zatrzymania serwera lub wyzwolenia pracy awaryjnej przez plik wyzwalacza.
To będzie diagram takiej konfiguracji:
Replikacja strumieniowa jest domyślnie asynchroniczna, więc w pewnym momencie możemy mieć pewne transakcje, które mogą zostać zatwierdzone w urządzeniu głównym, a które nie zostały jeszcze zreplikowane na serwer rezerwowy. Oznacza to potencjalną utratę danych.
Jednak to opóźnienie między zatwierdzeniem a wpływem zmian w replice powinno być naprawdę małe (kilka milisekund), oczywiście przy założeniu, że serwer replik jest wystarczająco mocny, aby nadążyć za obciążeniem.
W przypadkach, gdy nawet ryzyko małej utraty danych nie jest tolerowane, możemy użyć funkcji replikacji synchronicznej.
W replikacji synchronicznej każde zatwierdzenie transakcji zapisu będzie czekać do momentu otrzymania potwierdzenia, że zatwierdzenie zostało zapisane w dzienniku zapisu z wyprzedzeniem na dysku zarówno serwera podstawowego, jak i rezerwowego.
Ta metoda minimalizuje możliwość utraty danych, ponieważ aby tak się stało, będziemy potrzebować awarii zarówno mastera, jak i standby.
Oczywistą wadą tej konfiguracji jest to, że wydłuża się czas odpowiedzi dla każdej transakcji zapisu, ponieważ musimy czekać, aż wszystkie strony odpowiedzą. Tak więc czas na zatwierdzenie to co najmniej podróż w obie strony między masterem a repliką. Nie będzie to miało wpływu na transakcje tylko do odczytu.
Aby skonfigurować replikację synchroniczną, każdy z serwerów rezerwowych musi określić nazwę_aplikacji w primary_conninfo pliku recovery.conf:primary_conninfo ='...aplication_name=slaveX' .
Musimy również określić listę serwerów rezerwowych, które będą brać udział w replikacji synchronicznej:synchronous_standby_name ='slaveX,slaveY'.
Możemy skonfigurować jeden lub kilka serwerów synchronicznych, a ten parametr określa również, którą metodę (PIERWSZĄ i DOWOLNĄ) wybrać synchroniczne tryby gotowości spośród wymienionych.
Aby wdrożyć TimescaleDB z ustawieniami replikacji strumieniowej (synchronicznej lub asynchronicznej), możemy użyć ClusterControl, jak widać tutaj.
Po skonfigurowaniu naszej replikacji i uruchomieniu jej będziemy potrzebować dodatkowych funkcji monitorowania i zarządzania kopiami zapasowymi. ClusterControl pozwala nam monitorować i zarządzać kopiami zapasowymi/przechowywaniem naszego klastra TimescaleDB z tego samego miejsca bez żadnego zewnętrznego narzędzia.
Jak skonfigurować replikację strumieniową w TimescaleDB
Konfigurowanie replikacji strumieniowej to zadanie, które wymaga dokładnego wykonania kilku kroków. Jeśli chcesz skonfigurować go ręcznie, możesz śledzić nasz blog na ten temat.
Możesz jednak wdrożyć lub zaimportować bieżącą bazę danych TimescaleDB w ClusterControl, a następnie za pomocą kilku kliknięć skonfigurować replikację strumieniową. Zobaczmy, jak możemy to zrobić.
W tym zadaniu założymy, że masz klaster TimescaleDB zarządzany przez ClusterControl. Przejdź do ClusterControl -> Wybierz Cluster -> Cluster Actions -> Add Replication Slave.
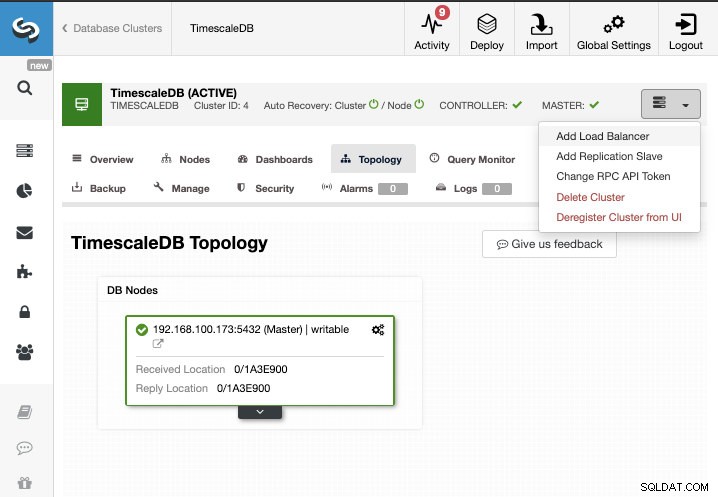
Możemy utworzyć nowe urządzenie podrzędne replikacji (w trybie gotowości) lub możemy zaimportować już istniejące. W takim przypadku utworzymy nowy.
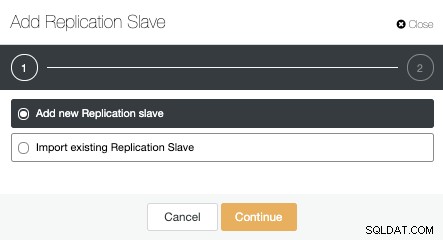
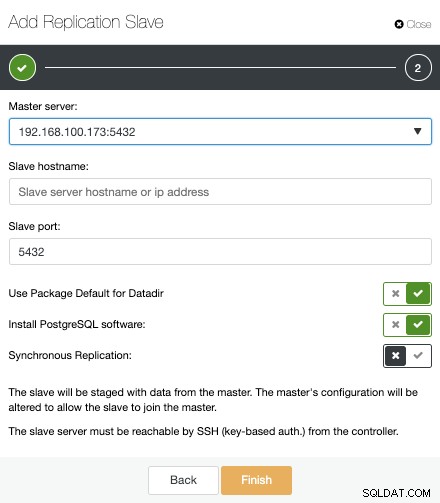
Teraz musimy wybrać węzeł główny, dodać adres IP lub nazwę hosta dla nowego serwera rezerwowego oraz port bazy danych. Możemy również określić, czy chcemy, aby ClusterControl zainstalował oprogramowanie i czy chcemy skonfigurować synchroniczną czy asynchroniczną replikację strumieniową.
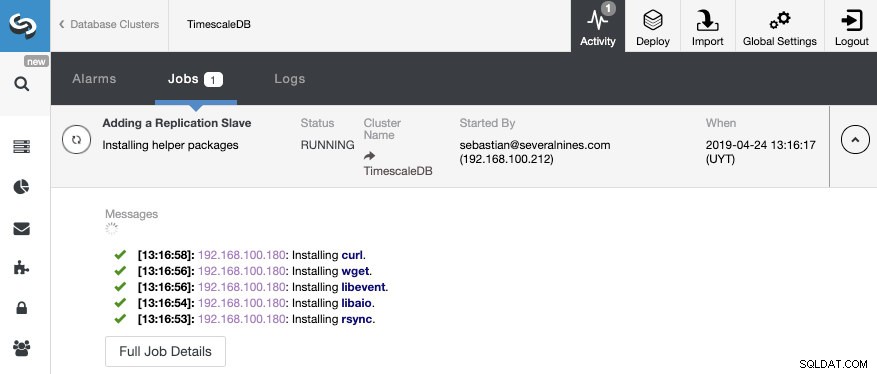
To wszystko. Musimy tylko poczekać, aż ClusterControl zakończy pracę. Możemy monitorować status z sekcji Aktywność.
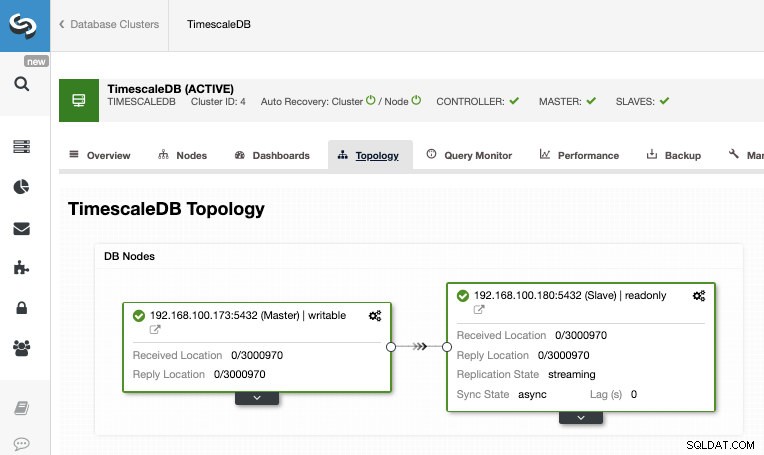
Po zakończeniu zadania powinniśmy mieć skonfigurowaną replikację strumieniową i możemy sprawdzić nową topologię w sekcji ClusterControl Topology View.
Korzystając z ClusterControl, możesz również wykonywać kilka zadań zarządzania w bazie danych TimescaleDB, takich jak tworzenie kopii zapasowych, monitorowanie i alerty, automatyczne przełączanie awaryjne, dodawanie węzłów, dodawanie systemów równoważenia obciążenia i wiele więcej.
Przełączanie awaryjne
Jak widzieliśmy, TimescaleDB używa strumienia rekordów dziennika zapisu z wyprzedzeniem (WAL), aby zachować synchronizację rezerwowych baz danych. Jeśli serwer główny ulegnie awarii, rezerwa zawiera prawie wszystkie dane serwera głównego i można ją szybko przekształcić w nowy główny serwer bazy danych. Może to być synchroniczne lub asynchroniczne i można to zrobić tylko dla całego serwera bazy danych.
Aby skutecznie zapewnić wysoką dostępność, nie wystarczy mieć architektura master-standby. Musimy również włączyć automatyczną formę przełączania awaryjnego, więc jeśli coś zawiedzie, możemy mieć najmniejsze możliwe opóźnienie w wznowieniu normalnej funkcjonalności.
TimescaleDB nie zawiera automatycznego mechanizmu przełączania awaryjnego do identyfikowania błędów w głównej bazie danych i powiadamiania podrzędnego o przejęciu na własność, więc będzie to wymagało trochę pracy po stronie DBA. Będziesz mieć również działający tylko jeden serwer, więc trzeba będzie odtworzyć architekturę master-standby, więc wrócimy do tej samej normalnej sytuacji, którą mieliśmy przed tym problemem.
ClusterControl zawiera funkcję automatycznego przełączania awaryjnego dla TimescaleDB, aby skrócić średni czas naprawy (MTTR) w środowisku wysokiej dostępności. W przypadku awarii, ClusterControl przeniesie najbardziej zaawansowane urządzenie podrzędne do nadrzędnego i ponownie skonfiguruje pozostałe podrzędne, aby połączyć się z nowym nadrzędnym. HAProxy można również automatycznie wdrożyć w celu zaoferowania aplikacjom pojedynczego punktu końcowego bazy danych, dzięki czemu zmiana serwera głównego nie ma na nie wpływu.
Ograniczenia
Powiązane zasoby ClusterControl for TimescaleDB Jak łatwo wdrożyć replikację przesyłania strumieniowego PostgreSQL w usłudze TimescaleDB — szczegółowe informacjePodczas korzystania z replikacji strumieniowej mamy pewne dobrze znane ograniczenia:
- Nie możemy replikować do innej wersji lub architektury
- Nie możemy niczego zmienić na serwerze rezerwowym
- Nie mamy dużej szczegółowości tego, co możemy replikować
Aby przezwyciężyć te ograniczenia, mamy funkcję logicznej replikacji. Aby dowiedzieć się więcej o tym typie replikacji, odwiedź następujący blog.
Wniosek
Topologia master-standby ma wiele różnych zastosowań, takich jak analityka, tworzenie kopii zapasowych, wysoka dostępność, przełączanie awaryjne. W każdym razie konieczne jest zrozumienie, jak działa replikacja strumieniowa w TimescaleDB. Przydatne jest również posiadanie systemu do zarządzania całym klastrem i łatwego tworzenia tej topologii. W tym blogu zobaczyliśmy, jak to osiągnąć za pomocą ClusterControl, i omówiliśmy kilka podstawowych koncepcji dotyczących replikacji strumieniowej.