W poprzednich blogach moi koledzy i ja pokazaliśmy, jak można monitorować wydajność, zarządzać klastrami i wdrażać je, uruchamiać kopie zapasowe, a nawet włączać automatyczne przełączanie awaryjne dla TimescaleDB.
W tym blogu pokażemy, jak w kilku prostych krokach przeskalować pojedynczą instancję TimescaleDB do klastra wielowęzłowego.
Zaczniemy od wspólnej konfiguracji, instancji z pojedynczym węzłem działającej na CentosOS. Węzeł działa i jest już monitorowany i zarządzany przez ClusterControl.
Jeśli chcesz dowiedzieć się, jak wdrożyć lub zaimportować instancję TimescaleDB, zapoznaj się z blogiem mojego kolegi Sebastiana Insausti, „Jak łatwo wdrożyć TimescaleDB”.
Konfiguracja wygląda następująco...
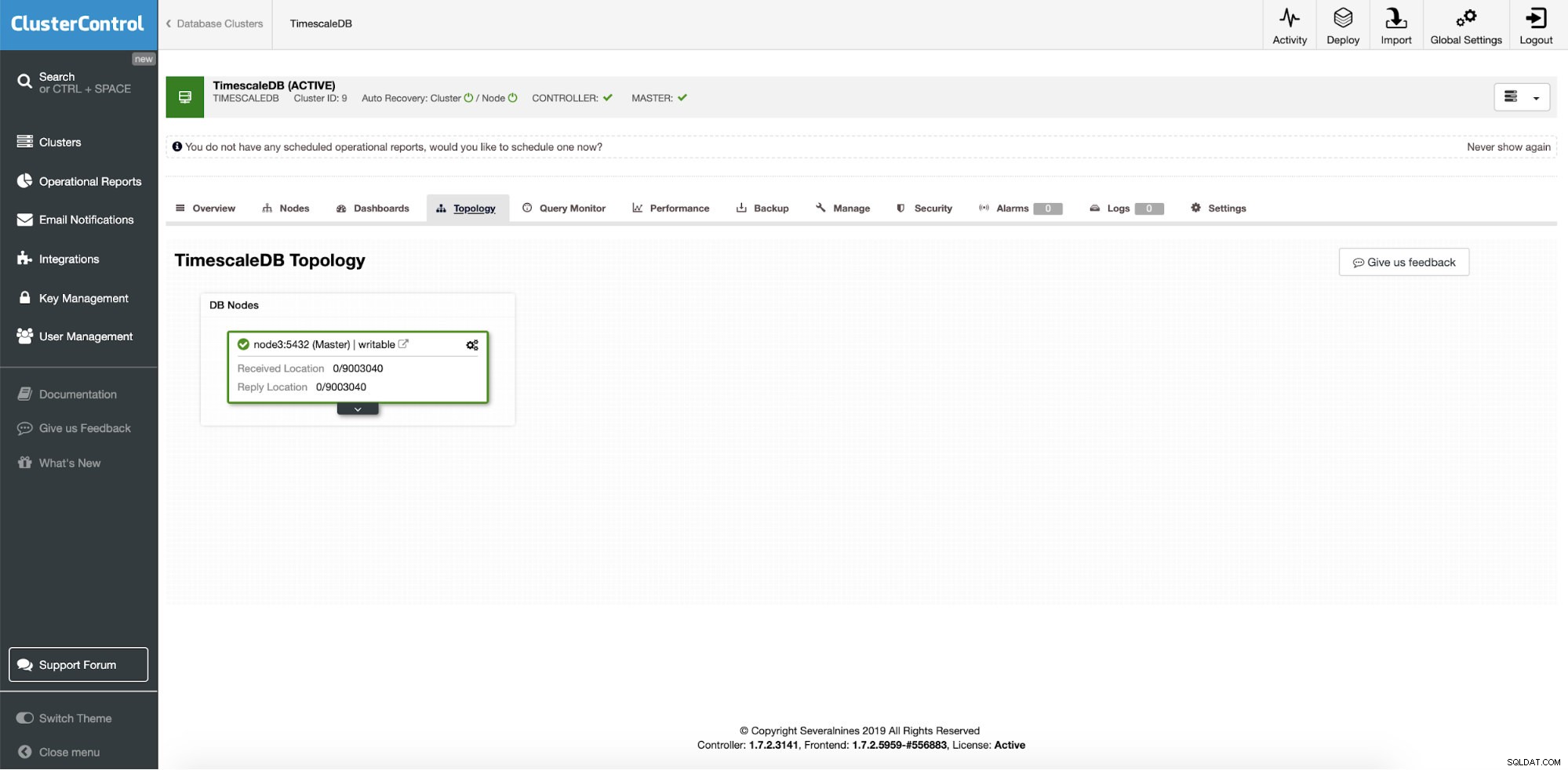 ClusterControl:pojedyncza instancja TimescaleDB
ClusterControl:pojedyncza instancja TimescaleDB Jest to więc pojedyncza instancja produkcyjna i chcemy ją przekonwertować na klaster bez przestojów. Naszym głównym celem jest skalowanie operacji odczytu aplikacji na inne komputery z opcją użycia ich jako pomostowych serwerów HA podczas pisania awarii serwera.
Więcej węzłów powinno również skrócić przestoje związane z konserwacją aplikacji. Podobnie jak łatanie stosowane w trybie restartu kroczącego - jeden węzeł załatany w danym momencie, podczas gdy inne węzły obsługują połączenia z bazą danych.
Ostatnim wymaganiem jest utworzenie jednego adresu dla naszego nowego klastra, aby nasze nowe węzły były widoczne dla aplikacji z jednego miejsca.

Nasz plan działania możemy podsumować w dwóch głównych krokach:
- Dodawanie odczytów repliki
- Zainstaluj i skonfiguruj Haproxy
Dodawanie odczytów repliki
Jeśli przejdziemy do działań klastrowych i wybierzemy „Dodaj niewolnik replikacji”, możemy albo utworzyć nową replikę od zera, albo dodać istniejącą bazę danych TimescaleDB jako replikę.
 ClusterControl:dodaj urządzenie podrzędne replikacji
ClusterControl:dodaj urządzenie podrzędne replikacji  ClusterControl:Dodaj nowe urządzenie podrzędne replikacji, zaimportuj istniejące urządzenie podrzędne replikacji
ClusterControl:Dodaj nowe urządzenie podrzędne replikacji, zaimportuj istniejące urządzenie podrzędne replikacji Jak widać na poniższym obrazku, musimy tylko wybrać nasz serwer główny, wprowadzić adres IP naszego nowego serwera podrzędnego i port bazy danych.
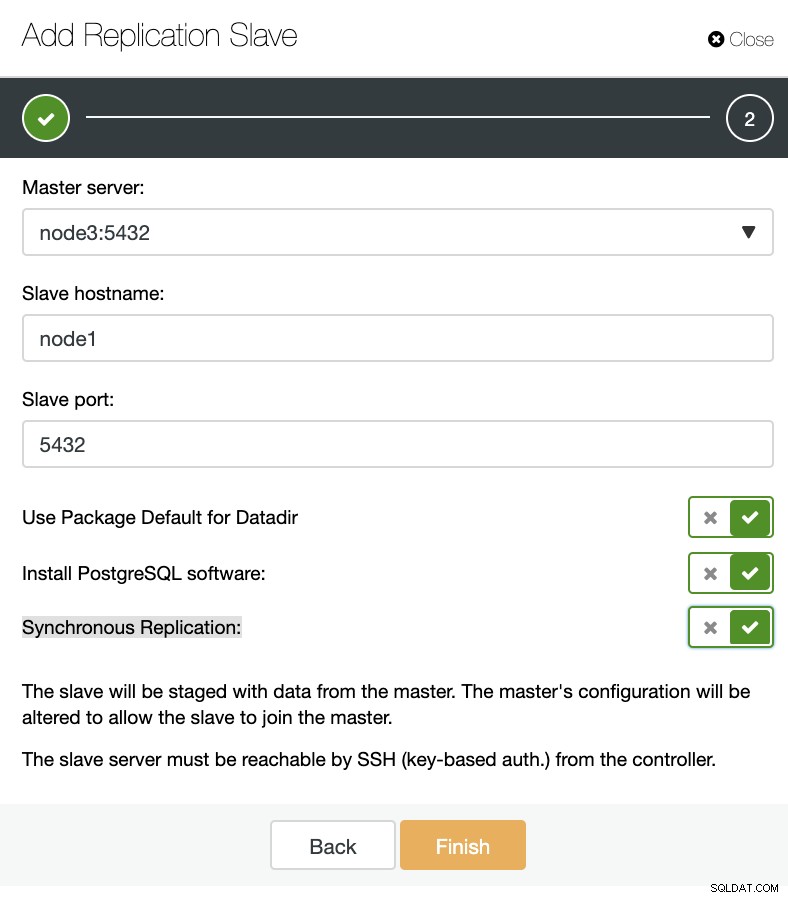 ClusterControl:Dodaj urządzenie podrzędne replikacji
ClusterControl:Dodaj urządzenie podrzędne replikacji Następnie możemy wybrać, czy chcemy, aby ClusterControl zainstalował oprogramowanie za nas i czy urządzenie podrzędne replikacji powinno być synchroniczne czy asynchroniczne. Podczas importowania istniejącego serwera podrzędnego możesz użyć opcji importu w następujący sposób:
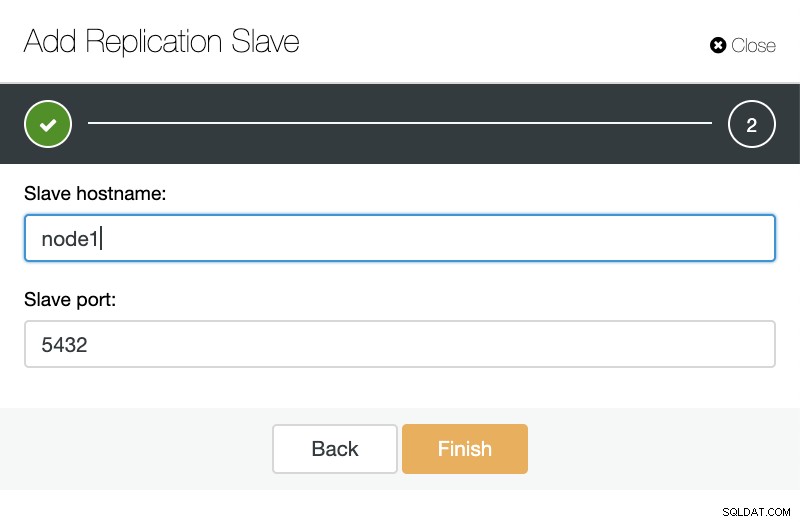 ClusterControl:Importuj urządzenie podrzędne replikacji dla TimescaleDB
ClusterControl:Importuj urządzenie podrzędne replikacji dla TimescaleDB W obie strony możemy dodać tyle replik, ile chcemy. W naszym przykładzie dodamy dwa węzły. CusterControl utworzy wewnętrzne zadanie i zajmie się wszystkimi niezbędnymi krokami, nie robiąc żadnego na raz.
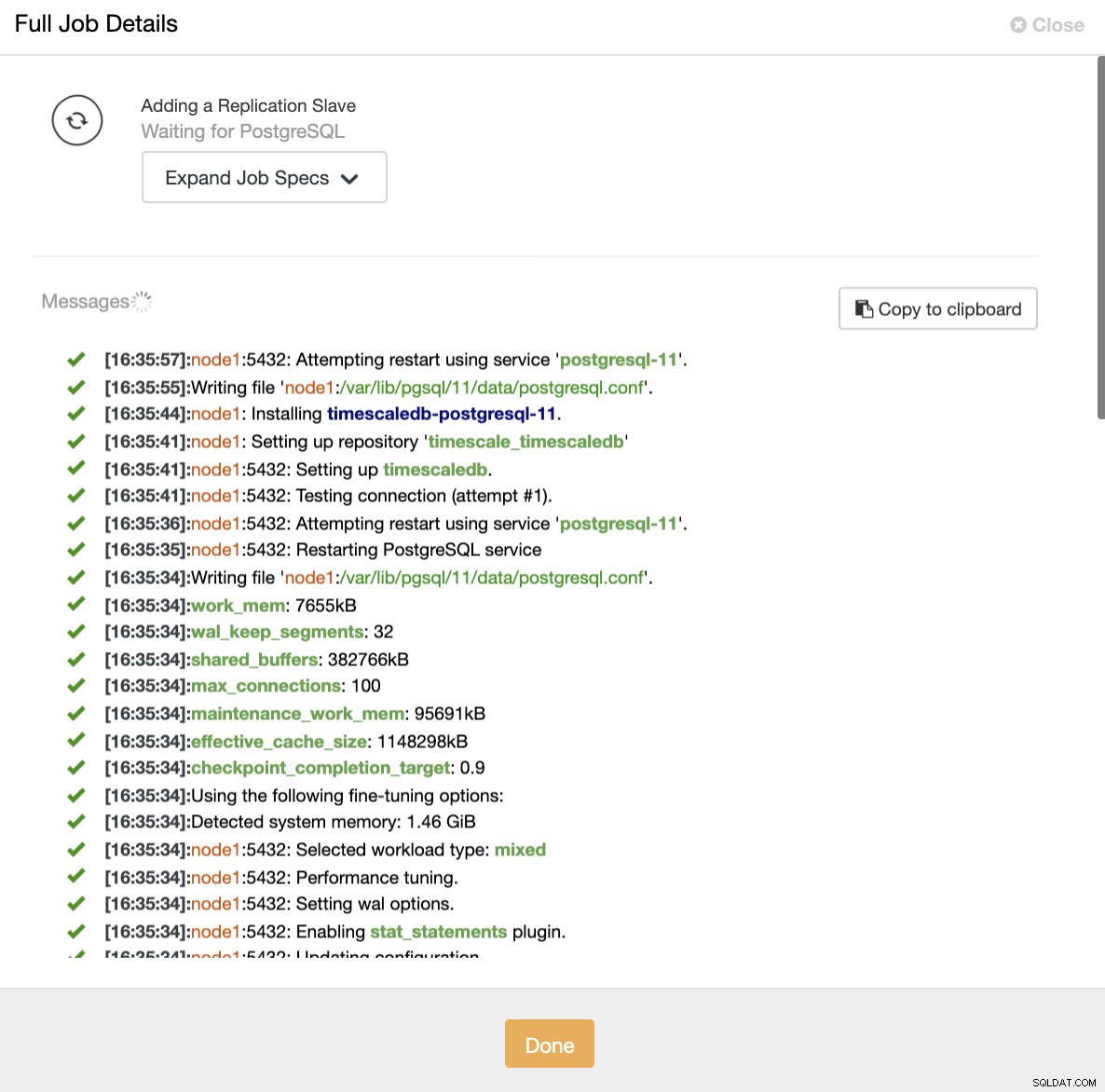 ClusterControl:dodaj replikę do odczytu
ClusterControl:dodaj replikę do odczytu Dodawanie Load Balancer do TimescaleDB
W tym momencie nasze dane są dystrybuowane w wielu węzłach lub centrach danych, jeśli zdecydujesz się dodać węzły podrzędne replikacji w innej lokalizacji. Klaster jest skalowany z dwoma dodatkowymi węzłami repliki do odczytu.
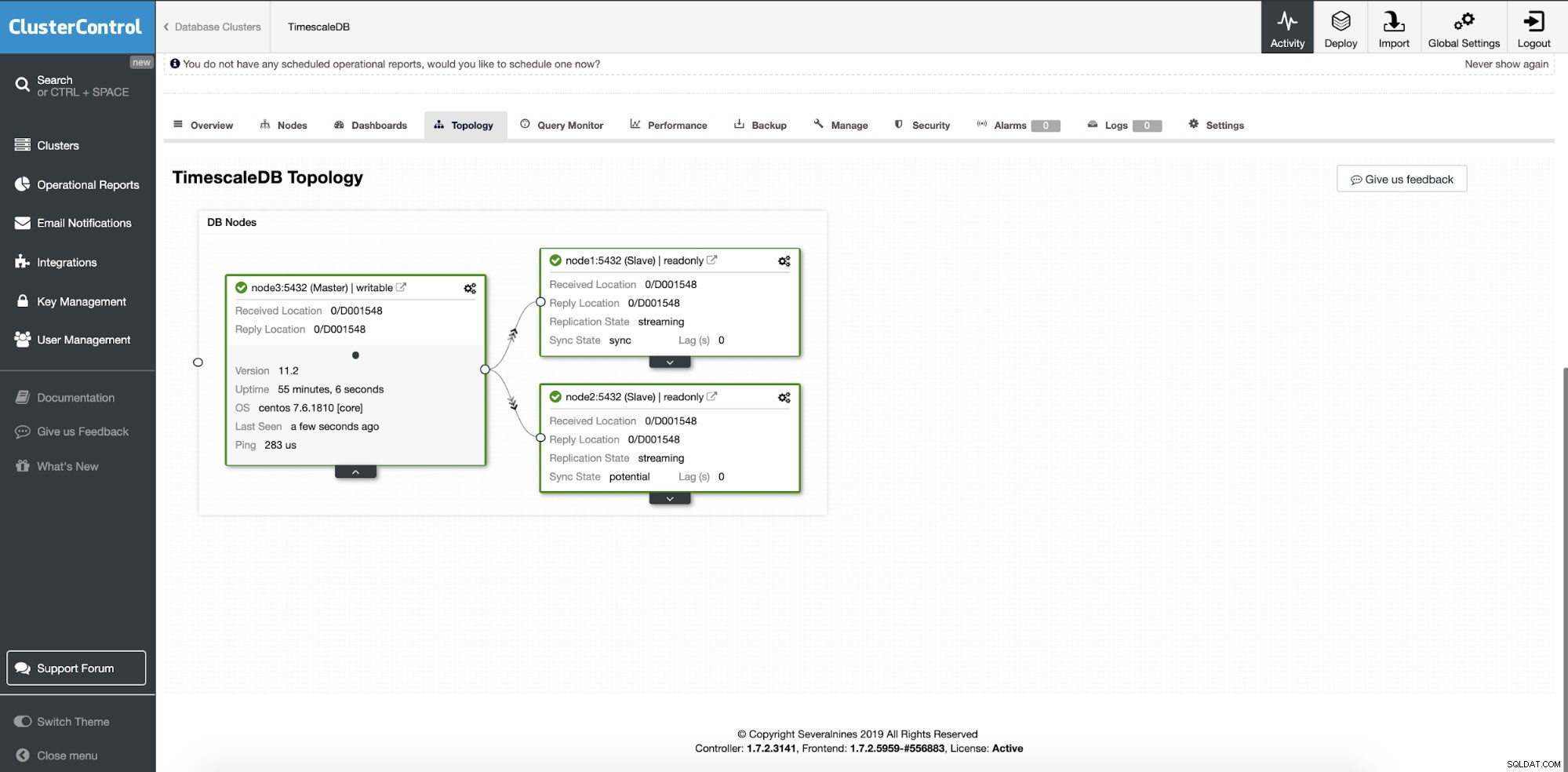 ClusterControl:dodano dwa węzły
ClusterControl:dodano dwa węzły Pytanie brzmi, skąd aplikacja wie, do którego węzła bazy danych ma uzyskać dostęp? Do operacji zapisu i odczytu użyjemy HAProxy i innych portów.
Z klastra TimescaleDB wybierz menu kontekstowe, aby dodać system równoważenia obciążenia.

Teraz musimy podać lokalizację serwera, na którym powinno być zainstalowane Haproxy, jakiej polityki chcemy użyć dla połączeń z bazą danych i które węzły biorą udział w konfiguracji Haproxy.
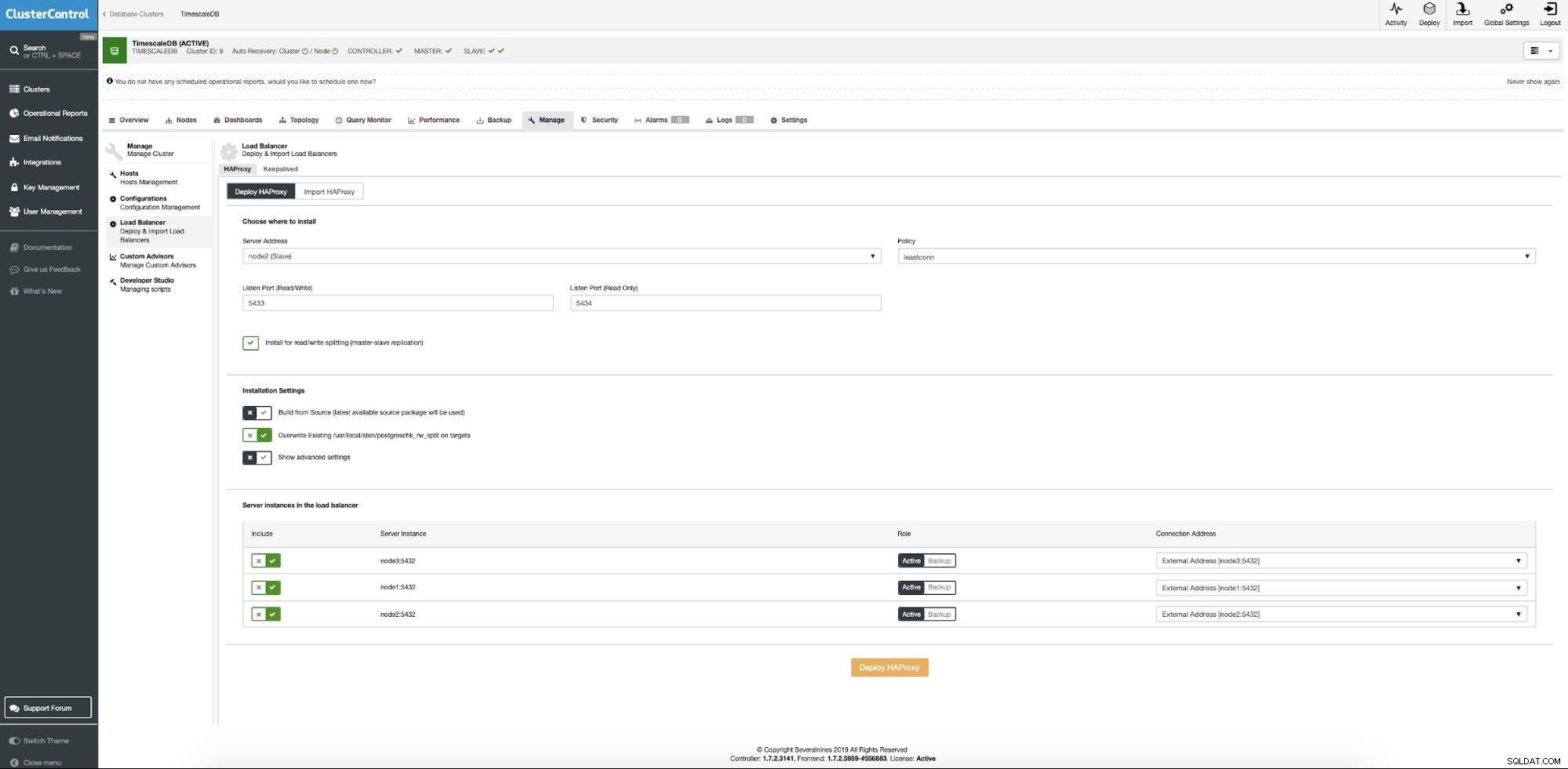
Gdy wszystko jest ustawione, naciśnij przycisk wdrażania. Po kilku minutach powinniśmy przygotować konfigurację naszego klastra. ClusterControl zadba o wszystkie wymagania wstępne i konfiguracje w celu wdrożenia systemu równoważenia obciążenia.
Po pomyślnym wdrożeniu możemy zobaczyć topologię naszego nowego klastra; z równoważeniem obciążenia i dodatkowymi węzłami odczytu. Dzięki większej liczbie węzłów ClusterControl automatycznie włącza automatyczne przywracanie. W ten sposób, gdy węzeł główny zostanie wyłączony, operacja przełączania awaryjnego rozpocznie się sama.
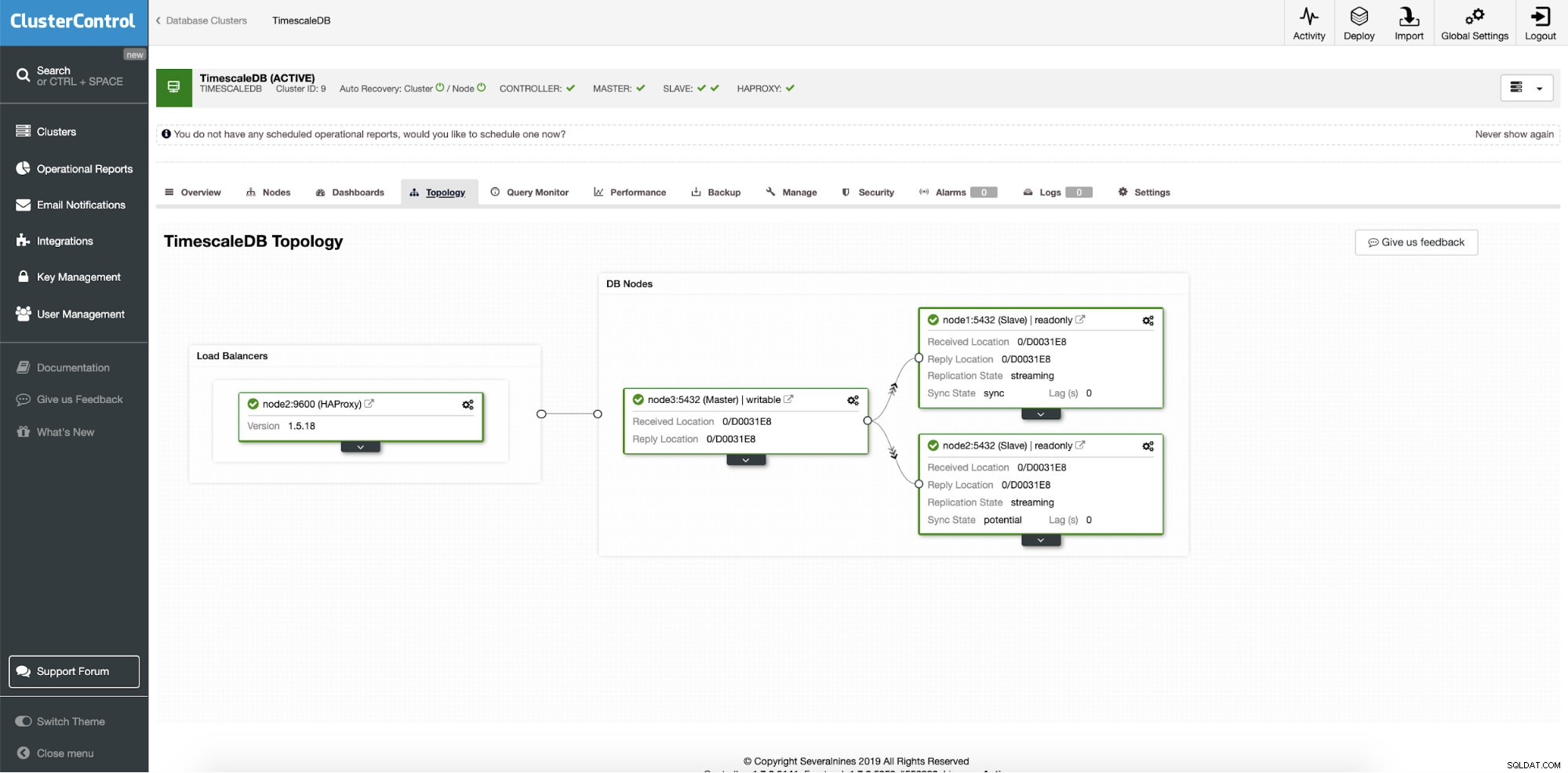 ClusterControl:ostateczna topologia
ClusterControl:ostateczna topologia Wniosek
TimescaleDB to baza danych typu open source wymyślona w celu skalowania SQL dla danych szeregów czasowych. Posiadanie zautomatyzowanego sposobu na rozszerzenie klastra jest kluczem do osiągnięcia wydajności i efektywności. Jak widzieliśmy powyżej, możesz teraz z łatwością skalować TimescaleDB za pomocą ClusterControl.