Rosnące zapotrzebowanie na systemy o wysokiej dostępności i napięte umowy SLA skłania nas do zastępowania procedur ręcznych rozwiązaniami zautomatyzowanymi. Ale czy masz czas i niezbędne zasoby, aby samodzielnie zająć się złożonością operacji przełączania awaryjnego? Czy poświęcisz przestój produkcyjnej bazy danych, aby nauczyć się tego na własnej skórze?
ClusterControl zapewnia zaawansowaną obsługę wykrywania i obsługi awarii. Jest używany przez wiele organizacji korporacyjnych, utrzymując najbardziej krytyczne systemy produkcyjne w trybie 24/7.
To rozwiązanie do zarządzania bazą danych wspiera również wdrażanie różnych serwerów proxy obciążenia. Te serwery proxy odgrywają kluczową rolę w stosie HA, więc nie ma potrzeby dostosowywania ciągu połączenia aplikacji lub wpisu DNS w celu przekierowywania połączeń aplikacji do nowego węzła głównego.
Po wykryciu awarii ClusterControl wykonuje całą pracę w tle, aby wybrać nowego mastera, wdrożyć awaryjne serwery slave i skonfigurować systemy równoważenia obciążenia. W tym blogu dowiesz się, jak osiągnąć automatyczne przełączanie awaryjne TimescaleDB w swoich systemach produkcyjnych.
Wdrażanie całych topologii replikacji
Począwszy od ClusterControl 1.7.2, możesz wdrożyć całą konfigurację replikacji TimescaleDB w taki sam sposób, jak wdrażasz PostgreSQL:możesz użyć menu "Deploy Cluster", aby wdrożyć podstawowy i jeden lub więcej serwerów rezerwowych TimescaleDB. Zobaczmy, jak to wygląda.
Najpierw musisz zdefiniować szczegóły dostępu podczas wdrażania nowych klastrów przy użyciu ClusterControl. Wymaga dostępu do hasła root lub hasła sudo do wszystkich węzłów, na których zostanie wdrożony nowy klaster.
 ClusterControl:wdrażanie nowego klastra
ClusterControl:wdrażanie nowego klastra Następnie musimy zdefiniować użytkownika i hasło dla użytkownika TimescaleDB.
 ClusterControl:wdrażanie klastra bazy danych
ClusterControl:wdrażanie klastra bazy danych Na koniec chcesz zdefiniować topologię — który host powinien być podstawowym, a który powinien być skonfigurowany jako rezerwowy. Podczas definiowania hostów w topologii ClusterControl sprawdzi, czy dostęp ssh działa zgodnie z oczekiwaniami — pozwala to na wczesne wyłapanie wszelkich problemów z łącznością. Na ostatnim ekranie zostaniesz zapytany o typ replikacji synchronicznej lub asynchronicznej.
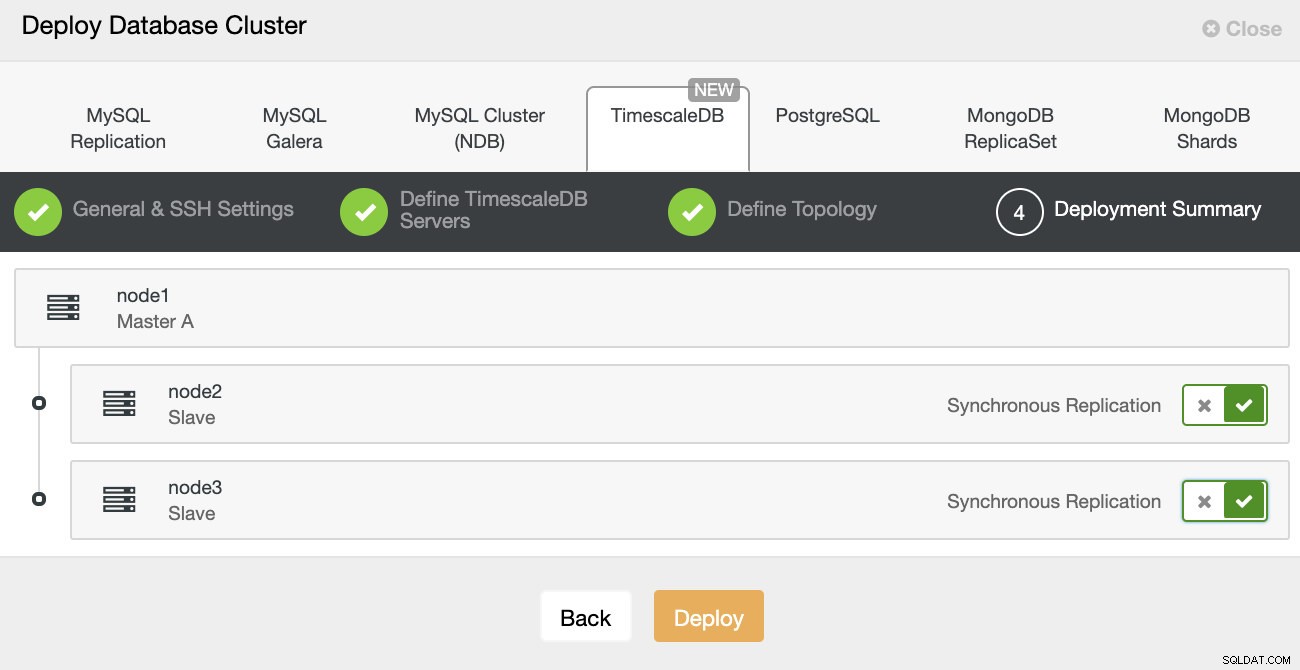 Wdrożenie ClusterControl
Wdrożenie ClusterControl To wszystko, to jest kwestia rozpoczęcia wdrożenia. Zadanie jest tworzone w ClusterControl i będziesz mógł śledzić postępy.
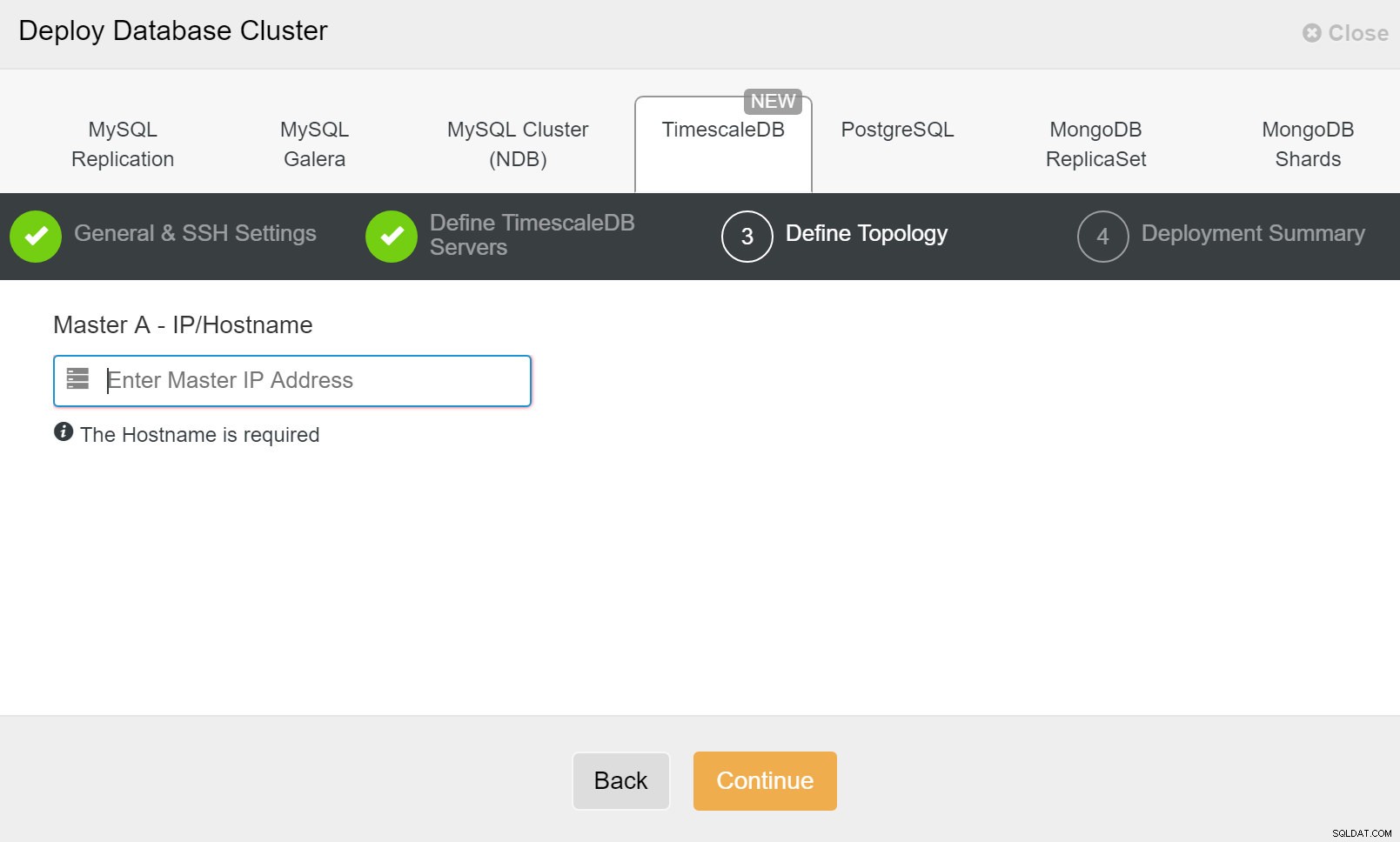 ClusterControl:Zdefiniuj topologię dla klastra TimescleDb
ClusterControl:Zdefiniuj topologię dla klastra TimescleDb Po zakończeniu zobaczysz konfigurację topologii z rolami w klastrze. Zwróć uwagę, że dodaliśmy również system równoważenia obciążenia (HAProxy) przed instancjami bazy danych, aby automatyczne przełączanie awaryjne nie wymagało zmian w ustawieniach połączenia z bazą danych.
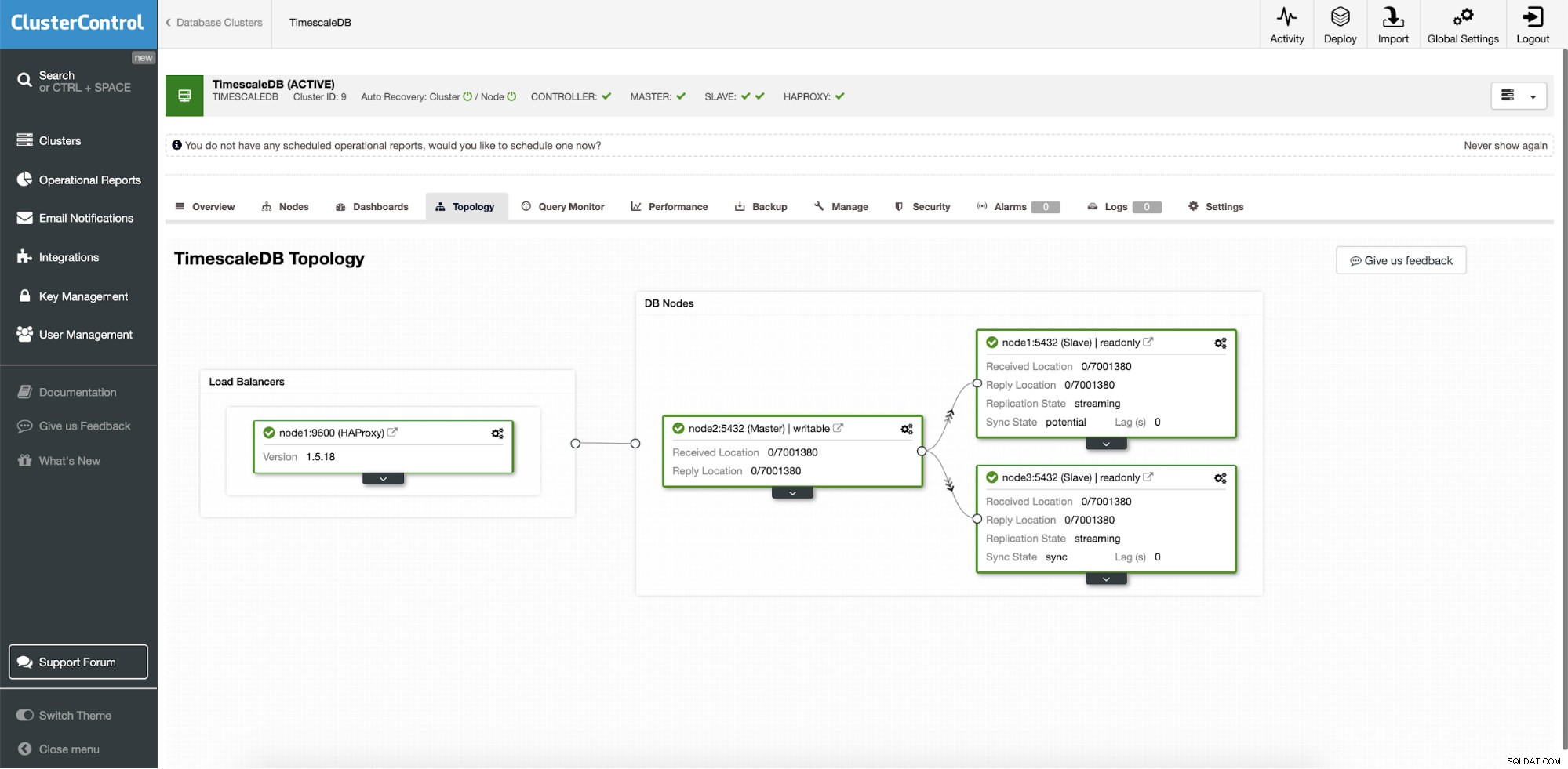 ClusterControl:topologia
ClusterControl:topologia Gdy skala czasu jest wdrożona przez ClusterControl, automatyczne odzyskiwanie jest domyślnie włączone. Stan można sprawdzić na pasku klastra.
 ClusterControl:stan klastra i węzła automatycznego odzyskiwania
ClusterControl:stan klastra i węzła automatycznego odzyskiwania Konfiguracja przełączania awaryjnego
Po wdrożeniu konfiguracji replikacji, ClusterControl jest w stanie monitorować konfigurację i automatycznie odzyskiwać wszystkie uszkodzone serwery. Może również aranżować zmiany w topologii.
Automatyczne przełączanie awaryjne ClusterControl zostało zaprojektowane zgodnie z następującymi zasadami:
- Upewnij się, że master naprawdę nie żyje, zanim przełączysz się w tryb awaryjny
- Przełączanie awaryjne tylko raz
- Nie przełączaj awaryjnie na niespójne urządzenie podrzędne
- Tylko pisz do mistrza
- Nie przywracaj automatycznie uszkodzonego wzorca
Dzięki wbudowanym algorytmom przełączanie awaryjne można często wykonać dość szybko, dzięki czemu można zapewnić najwyższe SLA dla środowiska bazy danych.
Proces jest konfigurowalny. Zawiera wiele parametrów, których możesz użyć, aby dostosować odzyskiwanie do specyfiki swojego środowiska.
| max_replication_lag | Maksymalne opóźnienie replikacji w sekundach przed |
| replication_stop_on_error | Procedury przełączania awaryjnego/przełączania zakończą się niepowodzeniem, jeśli wystąpią błędy, które mogą spowodować utratę danych. Domyślnie włączone. 0 oznacza wyłączenie, |
| replication_auto_rebuild_slave | Jeśli wątek SQL zostanie zatrzymany, a kod błędu jest niezerowy, urządzenie podrzędne zostanie automatycznie odbudowane. 1 oznacza włączenie, 0 oznacza wyłączenie (domyślnie). |
| replication_failover_blacklist | Rozdzielana przecinkami lista par nazwa hosta:port. Serwery umieszczone na czarnej liście nie będą brane pod uwagę podczas przełączania awaryjnego. replication_failover_blacklist jest ignorowana, jeśli ustawiono replication_failover_whitelist. |
| replication_failover_whitelist | Lista rozdzielonych przecinkami par nazwa hosta:port. Tylko serwery z białej listy będą brane pod uwagę podczas przełączania awaryjnego. Jeśli żaden serwer na białej liście nie jest dostępny (podłączony/podłączony), przełączanie awaryjne nie powiedzie się. replication_failover_blacklist jest ignorowana, jeśli ustawiono replication_failover_whitelist. |
Obsługa przełączania awaryjnego
Po wykryciu awarii wzorca tworzona jest lista kandydatów na wzorce, z których jeden jest wybierany jako nowy wzorzec. Możliwe jest posiadanie białej listy serwerów, które można awansować na podstawowy, a także czarnej listy serwerów, których nie można awansować na podstawowy. Pozostałe urządzenia podrzędne są teraz podporządkowane nowej podstawowej, a stara podstawowa nie jest restartowana.
Poniżej możemy zobaczyć symulację awarii węzła.
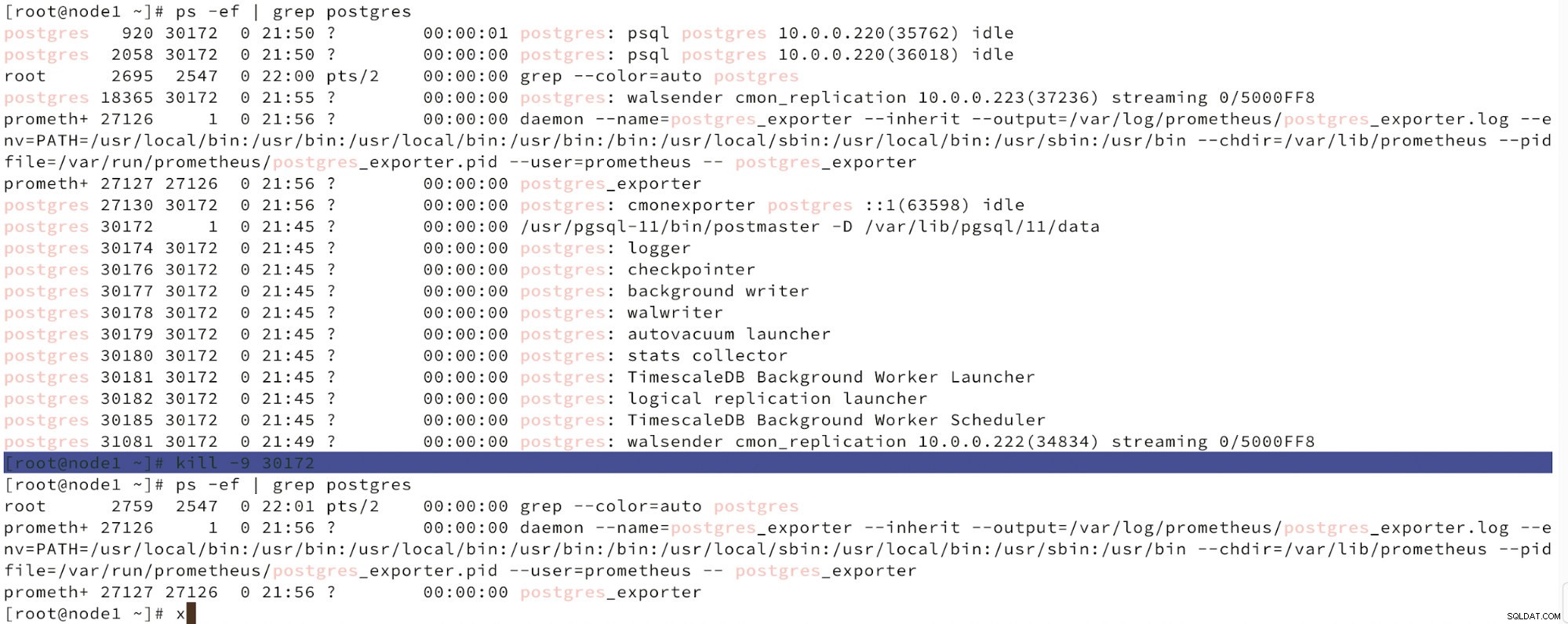 Symuluj awarię węzła głównego za pomocą kill
Symuluj awarię węzła głównego za pomocą kill Po wykryciu awarii węzłów i wykryciu automatycznego przywracania, ClusterControl uruchamia zadanie w celu wykonania przełączenia awaryjnego. Poniżej możemy zobaczyć działania podjęte w celu odzyskania klastra.
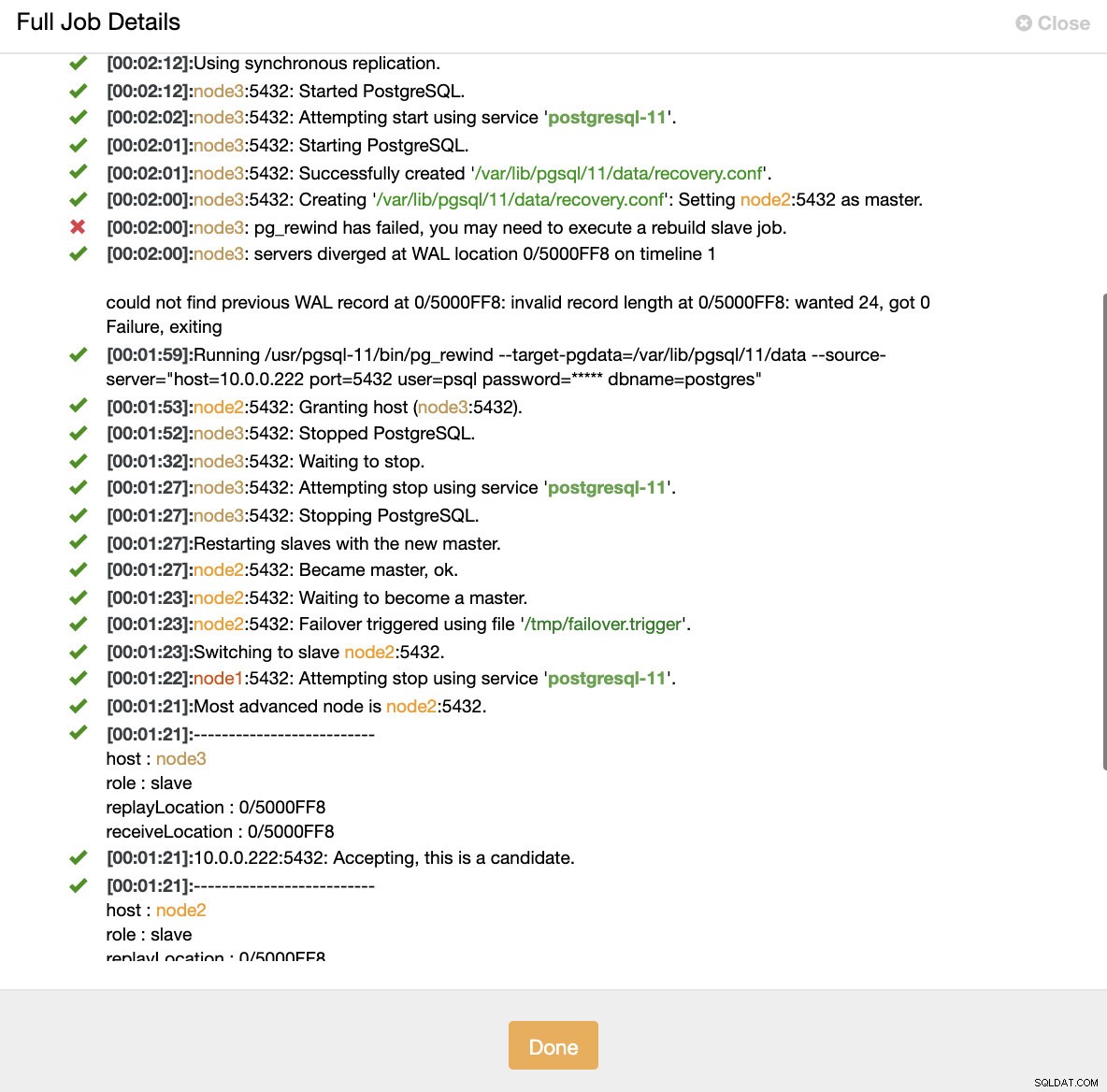 ClusterControl:zadanie wyzwalane w celu odbudowania klastra
ClusterControl:zadanie wyzwalane w celu odbudowania klastra ClusterControl celowo utrzymuje stary serwer podstawowy w trybie offline, ponieważ może się zdarzyć, że niektóre dane nie zostały przesłane do serwerów rezerwowych. W takim przypadku host podstawowy jest jedynym hostem zawierającym te dane i możesz chcieć odzyskać brakujące dane ręcznie. Dla tych, którzy chcą automatycznie odbudować uszkodzony podstawowy, istnieje opcja w pliku konfiguracyjnym cmon:replication_auto_rebuild_slave. Domyślnie jest wyłączony, ale gdy użytkownik go włączy, uszkodzony podstawowy zostanie odbudowany jako niewolnik nowego podstawowego. Oczywiście, jeśli brakuje jakichkolwiek danych, które istnieją tylko na uszkodzonym serwerze podstawowym, dane te zostaną utracone.
Odbudowa serwerów w trybie gotowości
Inną funkcją jest zadanie „Odbuduj urządzenie podrzędne replikacji”, które jest dostępne dla wszystkich urządzeń podrzędnych (lub serwerów rezerwowych) w konfiguracji replikacji. Ma to być używane na przykład, gdy chcesz wyczyścić dane w trybie gotowości i odbudować je ponownie za pomocą nowej kopii danych podstawowego. Może być korzystne, jeśli z jakiegoś powodu serwer rezerwowy nie jest w stanie połączyć się i replikować z serwera podstawowego.
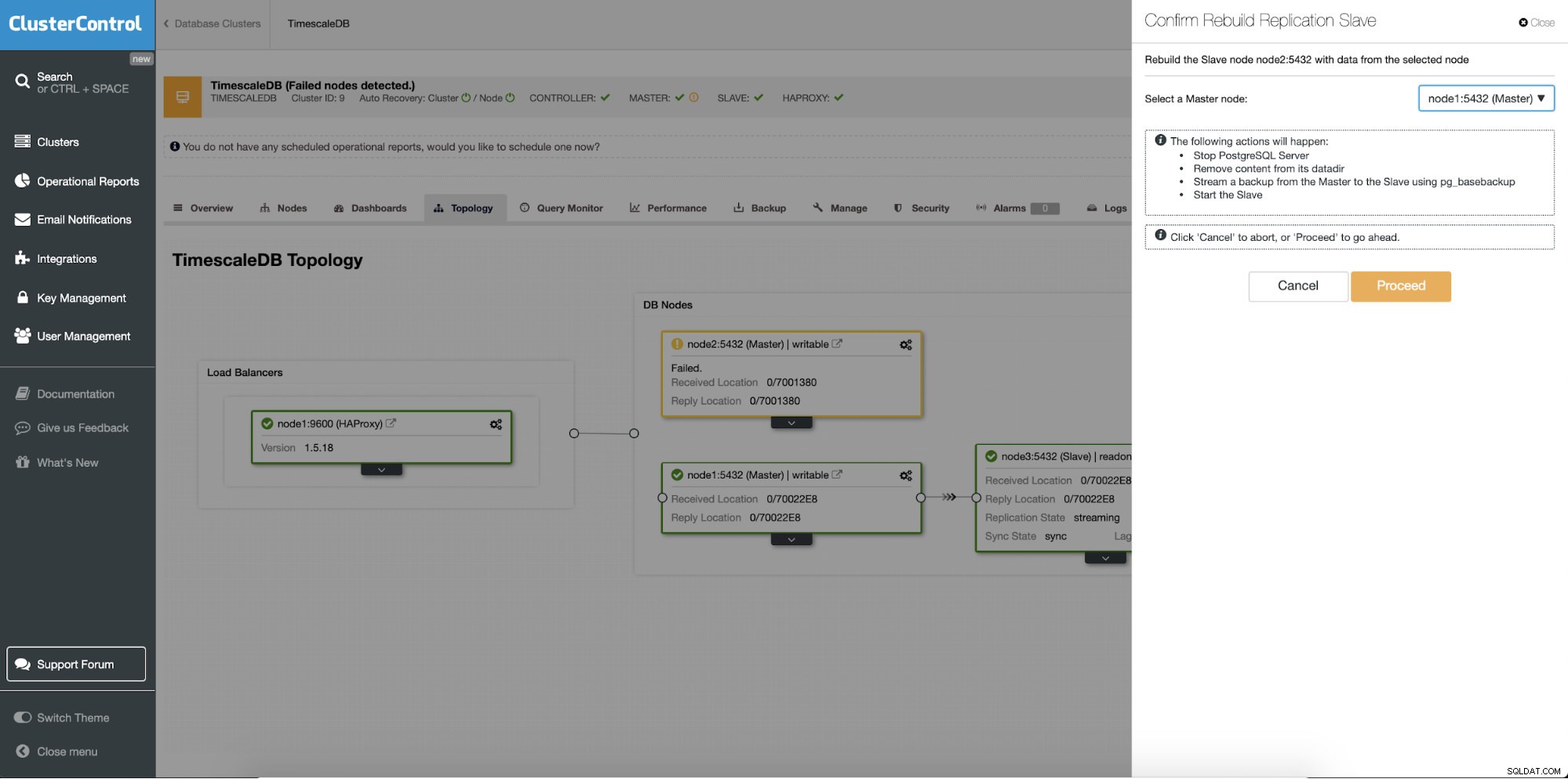 ClusterControl:odbuduj urządzenie podrzędne replikacji
ClusterControl:odbuduj urządzenie podrzędne replikacji 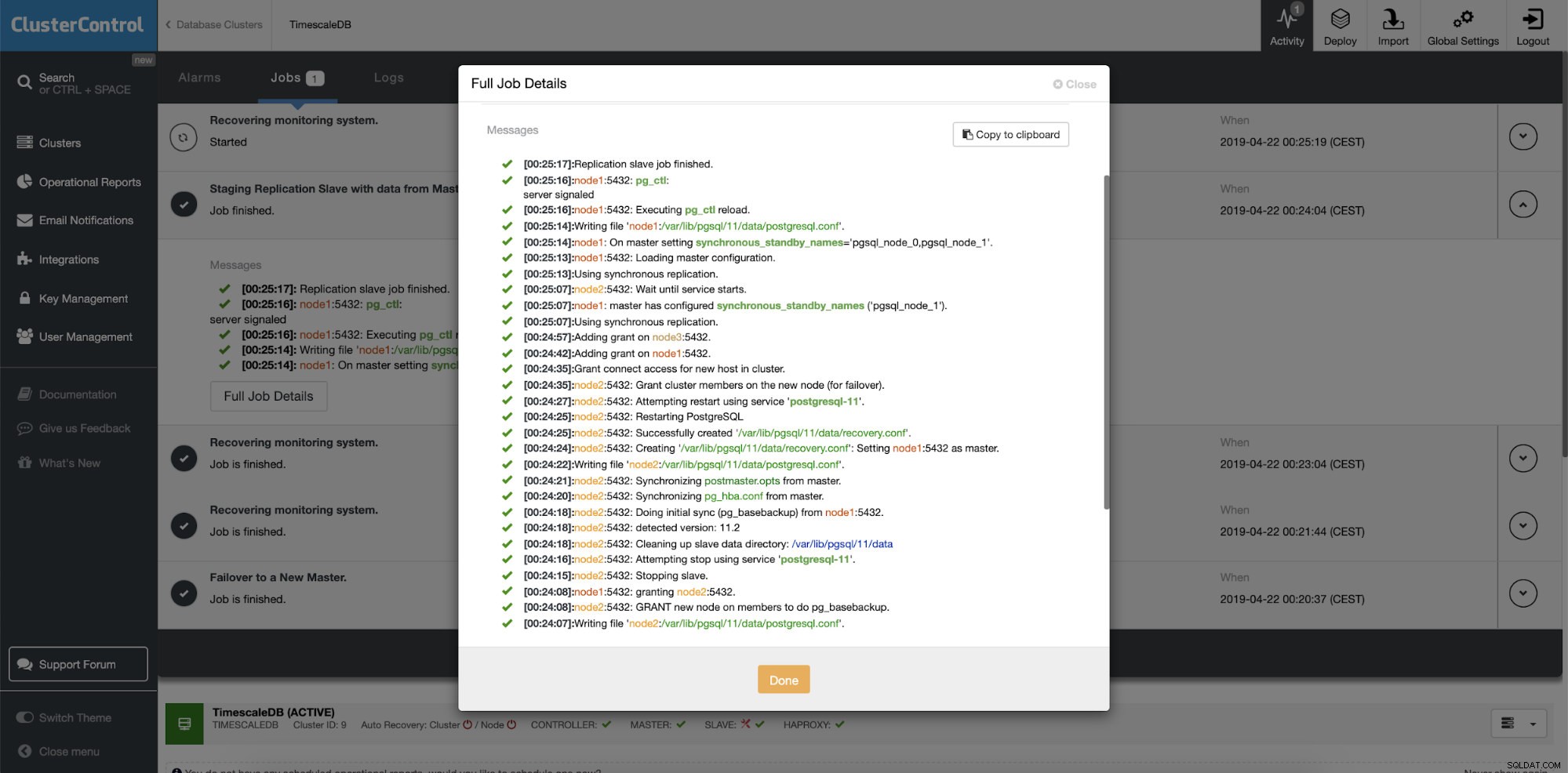 ClusterControl:odbuduj urządzenie podrzędne
ClusterControl:odbuduj urządzenie podrzędne