W odejściu od mojej serii „dostrajania wydajności pod kątem szarpnięć za kolano”, chciałbym omówić, w jaki sposób fragmentacja indeksu może wkraść się na ciebie w pewnych okolicznościach.
Co to jest fragmentacja indeksu?
Większość ludzi myśli o „fragmentacji indeksu” jako o problemie, w którym strony liścia indeksu są niesprawne – strona liścia indeksu z następną wartością klucza nie jest tą, która fizycznie przylega w pliku danych do aktualnie badanej strony liścia indeksu . Nazywa się to fragmentacją logiczną (niektórzy nazywają to fragmentacją zewnętrzną – mylące określenie, którego nie lubię).
Fragmentacja logiczna ma miejsce, gdy strona liścia indeksu jest pełna i wymagane jest na niej miejsce na wstawienie lub wydłużenie istniejącego rekordu (od aktualizacji kolumny o zmiennej długości). W takim przypadku aparat pamięci masowej tworzy nową, pustą stronę i przenosi 50% wierszy (zwykle, ale nie zawsze) z pełnej strony na nową stronę. Ta operacja tworzy miejsce na obu stronach, umożliwiając kontynuowanie wstawiania lub aktualizacji i jest nazywana podziałem strony. Istnieją interesujące przypadki patologiczne obejmujące powtarzające się podziały stron w ramach jednej operacji i podziały stron, które kaskadowo zwiększają poziomy indeksu, ale wykraczają one poza zakres tego postu.
Kiedy następuje podział strony, zwykle powoduje logiczną fragmentację, ponieważ przydzielona nowa strona prawdopodobnie nie będzie fizycznie przylegała do tej, która jest dzielona. Gdy indeks ma dużą fragmentację logiczną, skanowanie indeksu jest spowolnione, ponieważ fizyczne odczyty niezbędnych stron nie mogą być wykonywane tak wydajnie (przy użyciu wielostronicowych odczytów z wyprzedzeniem), gdy strony liści nie są przechowywane w kolejności w pliku danych .
To podstawowa definicja fragmentacji indeksu, ale istnieje drugi rodzaj fragmentacji indeksu, którego większość ludzi nie bierze pod uwagę:niska gęstość stron (czasami nazywamy fragmentację wewnętrzną, znowu mylącym terminem, który mi się nie podoba).
Gęstość strony jest miarą ilości danych przechowywanych na stronie liścia indeksu. Kiedy następuje podział strony w zwykłym przypadku 50/50, każda strona liścia (podział i nowa) ma gęstość strony tylko 50%. Im mniejsze zagęszczenie stron, tym więcej pustego miejsca w indeksie, a tym samym więcej miejsca na dysku i pamięci puli buforów, które można uznać za zmarnowane. Pisałem o tym problemie na blogu kilka lat temu i możesz o tym przeczytać tutaj.
Teraz, gdy podałem podstawową definicję dwóch rodzajów fragmentacji indeksów, będę je nazywał po prostu „fragmentacją”.
W pozostałej części tego postu chciałbym omówić trzy przypadki, w których klastrowane indeksy mogą ulec fragmentacji, nawet jeśli unikasz operacji, które w oczywisty sposób powodowałyby fragmentację (tj. losowe wstawianie i aktualizowanie rekordów, aby były dłuższe).
Fragmentacja z usuniętych
„W jaki sposób usunięcie z klastrowanej strony liścia indeksu może spowodować podział strony?” możesz zapytać. W normalnych okolicznościach tak się nie stanie (i zastanawiałem się nad tym przez kilka minut, aby upewnić się, że nie ma jakiegoś dziwnego, patologicznego przypadku! Ale zobacz sekcję poniżej…). Jednak usuwanie może powodować stopniowe zmniejszanie gęstości stron.
Wyobraź sobie przypadek, w którym indeks klastrowy ma wartość klucza tożsamości Bigint, więc wstawki zawsze będą przechodzić na prawą stronę indeksu i nigdy, przenigdy nie zostaną wstawione do wcześniejszej części indeksu (z wyjątkiem ponownego umieszczenia wartości tożsamości – potencjalnie bardzo problematyczne!). Teraz wyobraź sobie, że obciążenie usuwa z tabeli rekordy, które nie są już potrzebne, po czym zadanie czyszczenia ducha w tle odzyska miejsce na stronie i stanie się ono wolnym miejscem.
W przypadku braku jakichkolwiek losowych wstawek (niemożliwe w naszym scenariuszu, chyba że ktoś ponownie wstawi tożsamość lub określi wartość klucza do użycia po włączeniu opcji SET IDENTITY INSERT dla tabeli), żadne nowe rekordy nigdy nie będą korzystać z miejsca, które zostało zwolnione z usuniętych rekordów. Oznacza to, że średnia gęstość stron wcześniejszych części indeksu klastrowego będzie się stale zmniejszać, prowadząc do coraz większej ilości marnowanego miejsca na dysku i pamięci puli buforów, jak opisałem wcześniej.
Usunięcie może spowodować fragmentację, o ile gęstość stron uznasz za część „fragmentacji”.
Fragmentacja z izolacji migawki
W SQL Server 2005 wprowadzono dwa nowe poziomy izolacji:izolację migawek i izolację migawek odczytanych. Te dwa mają nieco inną semantykę, ale zasadniczo umożliwiają zapytaniom widok bazy danych z punktu w czasie i wybór bez kolizji. To ogromne uproszczenie, ale do moich celów wystarczy.
Aby ułatwić te poziomy izolacji, zespół programistów w firmie Microsoft, którym kierowałem, wdrożył mechanizm zwany wersjonowaniem. Sposób działania wersjonowania polega na tym, że za każdym razem, gdy rekord się zmieni, wersja przed zmianą rekordu jest kopiowana do magazynu wersji w tempdb, a zmieniony nagrany otrzymuje 14-bajtowy tag wersjonowania dodawany na końcu. Znacznik zawiera wskaźnik do poprzedniej wersji rekordu oraz znacznik czasu, którego można użyć do określenia, jaka jest poprawna wersja rekordu do odczytania przez dane zapytanie. Ponownie, bardzo uproszczone, ale interesuje nas tylko dodanie 14-bajtów.
Tak więc za każdym razem, gdy rekord zmienia się, gdy obowiązuje jeden z tych poziomów izolacji, może on rozszerzyć się o 14 bajtów, jeśli nie ma jeszcze znacznika wersji dla rekordu. Co zrobić, jeśli na stronie liścia indeksu nie ma wystarczająco dużo miejsca na dodatkowe 14 bajtów? Zgadza się, nastąpi podział strony, powodując fragmentację.
Można by pomyśleć, że to wielka sprawa, ponieważ rekord i tak się zmienia, więc gdyby i tak zmieniał rozmiar, prawdopodobnie doszłoby do podziału strony. Nie – ta logika obowiązuje tylko wtedy, gdy zmiana rekordu miała na celu zwiększenie rozmiaru kolumny o zmiennej długości. Znacznik wersjonowania zostanie dodany, nawet jeśli zaktualizowana zostanie kolumna o stałej długości!
Zgadza się — gdy w grę wchodzi wersjonowanie, aktualizacje kolumn o stałej długości mogą spowodować rozszerzenie rekordu, potencjalnie powodując podział strony i fragmentację. Jeszcze ciekawsze jest to, że usunięcie spowoduje również dodanie 14-bajtowego tagu, więc usunięcie w indeksie klastrowym może spowodować podział strony podczas używania wersji!
Najważniejsze jest to, że włączenie dowolnej formy izolacji migawki może prowadzić do nagłej fragmentacji w indeksach klastrowych, w których wcześniej nie było możliwości fragmentacji.
Fragmentacja z czytelnych plików pomocniczych
Ostatnim przypadkiem, który chcę omówić, jest użycie czytelnych plików pomocniczych, części funkcji grupy dostępności, która została dodana w SQL Server 2012.
Po włączeniu odczytu pomocniczego wszystkie zapytania, które wykonujesz względem repliki pomocniczej, są konwertowane na użycie izolacji migawki pod osłonami. Zapobiega to blokowaniu przez zapytania ciągłego odtwarzania rekordów dziennika z repliki podstawowej, ponieważ kod odzyskiwania blokuje się w miarę postępu.
Aby to zrobić, rekordy w replice pomocniczej muszą zawierać 14-bajtowe znaczniki wersji. Jest problem, ponieważ wszystkie repliki muszą być identyczne, aby odtwarzanie dziennika działało. Cóż, nie do końca. Zawartość znacznika wersjonowania nie ma znaczenia, ponieważ jest używana tylko w instancji, która je utworzyła. Ale replika pomocnicza nie może dodawać znaczników wersjonowania, wydłużając rekordy, ponieważ zmieniłoby to fizyczny układ rekordów na stronie i zepsułoby odtwarzanie dziennika. Jeśli jednak znaczniki wersjonowania już tam były, może wykorzystać przestrzeń bez uszkadzania czegokolwiek.
Tak właśnie się dzieje. Mechanizm pamięci masowej zapewnia, że wszystkie potrzebne znaczniki wersji dla repliki pomocniczej już tam są, dodając je do repliki głównej!
Po utworzeniu czytelnej repliki wtórnej bazy danych każda aktualizacja rekordu w replice podstawowej powoduje dodanie do rekordu pustego 14-bajtowego znacznika, dzięki czemu 14-bajty są prawidłowo uwzględniane we wszystkich rekordach dziennika . Tag nie jest używany do niczego (chyba że izolacja migawki jest włączona w samej replice podstawowej), ale fakt, że został utworzony, powoduje rozszerzenie rekordu, a jeśli strona jest już pełna, to…
Tak, włączenie czytelnego pliku pomocniczego ma taki sam wpływ na replikę główną, jak włączenie na niej izolacji migawki — fragmentacja.
Podsumowanie
Nie myśl, że ponieważ unikasz używania identyfikatorów GUID jako kluczy klastrowych i unikasz aktualizacji kolumn o zmiennej długości w tabelach, indeksy klastrowane będą odporne na fragmentację. Jak opisałem powyżej, istnieją inne czynniki związane z obciążeniem pracą i środowiskiem, które mogą powodować problemy z fragmentacją w indeksach klastrowanych, o których należy pamiętać.
Teraz nie szarpnij się i nie myśl, że nie powinieneś usuwać rekordów, nie powinieneś używać izolacji migawek i nie powinieneś używać czytelnych plików pomocniczych. Musisz tylko mieć świadomość, że wszystkie mogą powodować fragmentację i wiedzieć, jak ją wykryć, usunąć i złagodzić.
SQL Sentry ma fajne narzędzie, Menedżer fragmentacji, którego można użyć jako dodatku do Doradcy wydajności, aby pomóc ustalić, gdzie występują problemy z fragmentacją, a następnie je rozwiązać. Możesz być zaskoczony fragmentacją, którą znajdziesz podczas sprawdzania! Jako szybki przykład, tutaj mogę wizualnie zobaczyć – aż do poziomu poszczególnych partycji – jak bardzo istnieje fragmentacja, jak szybko się to stało, wszelkie istniejące wzorce i rzeczywisty wpływ, jaki ma to na zmarnowaną pamięć w systemie:
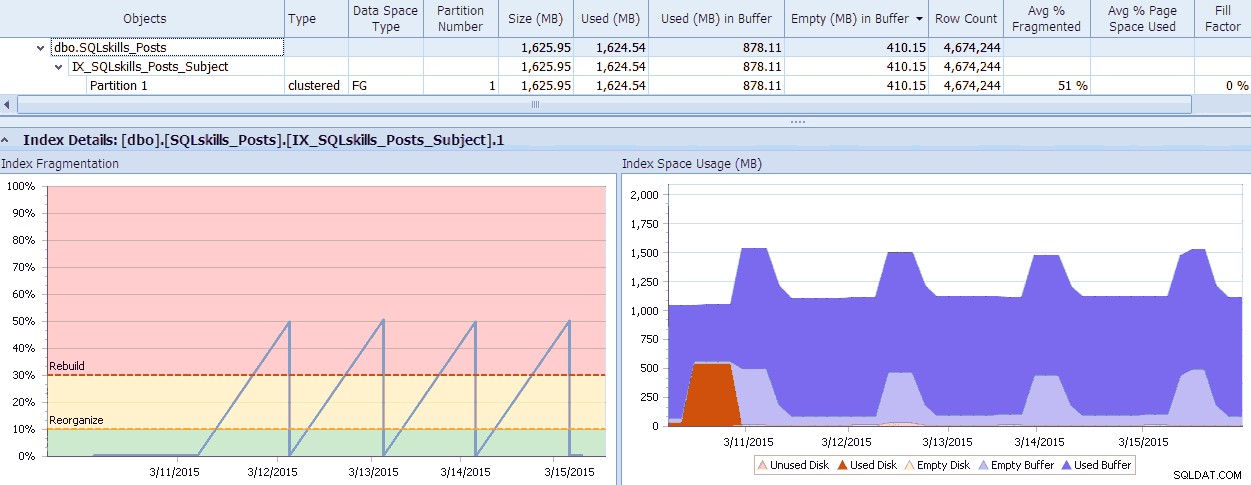 Dane menedżera fragmentacji danych SQL Sentry (kliknij, aby powiększyć)
Dane menedżera fragmentacji danych SQL Sentry (kliknij, aby powiększyć)
W następnym poście omówię więcej o fragmentacji i o tym, jak ją złagodzić, aby była mniej problematyczna.