BigQuery to zarządzana, bezserwerowa hurtownia danych w Google Cloud, która umożliwia skalowalną analizę petabajtów danych. Jest to platforma relacyjnej bazy danych jako usługa (PaaS), która obsługuje zapytania ANSI SQL. W związku z tym działa z oprogramowaniem IRI.
BigQuery to zarządzana, bezserwerowa hurtownia danych w Google Cloud, która umożliwia skalowalną analizę petabajtów danych. Jest to platforma relacyjnej bazy danych jako usługa (PaaS), która obsługuje zapytania ANSI SQL. W związku z tym działa z oprogramowaniem IRI.
Połączenie Google BigQuery RDB z IRI Workbench i programem do przetwarzania SortCL zaplecza jest proste i umożliwia przenoszenie i manipulowanie jego ustrukturyzowanymi danymi za pomocą zgodnych produktów IRI. Oznacza to IRI CoSort, FieldShield, NextForm i RowGen lub platformę IRI Vorcity, która obejmuje je wszystkie.
Łączność jest zgodna z tym samym paradygmatem, co wszystkie inne relacyjne bazy danych obsługiwane przez IRI. Oznacza to pobieranie i instalację sterowników ODBC i JDBC, konfigurację (używanie i testowanie przy użyciu poświadczeń), rejestrację i weryfikację.
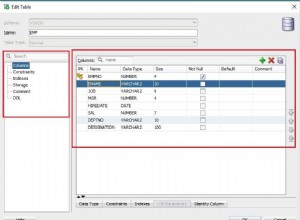
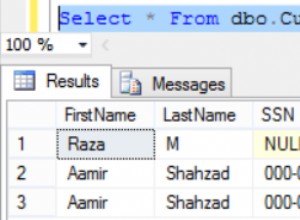
Ponieważ Workbench jest oparty na Eclipse, potrzebuje połączenia JDBC, aby wyświetlić schemat BigQuery i przeanalizować metadane tabeli. Aby przekazywać dane między BigQuery a silnikiem manipulacji danymi SortCL, potrzebny jest również sterownik ODBC. Ostateczny wynik może być następujący:

Google połączyło siły z Magnitude Simba, aby zapewnić sterowniki ODBC i JDBC do łączenia się z BigQuery. Jednak w chwili pisania tego tekstu w sterowniku JDBC brakuje kluczowych funkcji, których potrzebuje Workbench. Aby to obejść, użyj sterownika JDBC z CData.
Ten artykuł zawiera instrukcje krok po kroku dotyczące oprogramowania IRI umożliwiającego dostęp do BigQuery.
Konta usługi w BigQuery
BigQuery autoryzuje dostęp do zasobów na podstawie zweryfikowanej tożsamości, która wymaga identyfikatora użytkownika w postaci konta usługi oraz klucza/hasła. Aby utworzyć zweryfikowaną tożsamość, zaloguj się do BigQuery, przejdź do Konta usług w sekcji Uprawnienia i administracja i utwórz konto:

Pierwsze pole tworzy nazwę konta usługi, do mojej konfiguracji nazwałem je iri-simba. Drugie pole zostanie automatycznie wypełnione adresem e-mail konta usługi o wybranej przez Ciebie nazwie. Ostatnie pole można pominąć. Kliknij Utwórz i kontynuuj
Po utworzeniu konta usługi możemy przejść do typu uprawnień, jakie może mieć to konto. Kliknij Wybierz rolę i poszukaj BigQuery, aby dodać określone role do bazy danych.

Najechanie kursorem na każdą rolę daje szybki opis typu dostępu, jaki ta rola zapewni kontu usługi; bardziej szczegółowe wyjaśnienie znajdziesz tutaj. Pozwala to na większą kontrolę nad przyznawaniem określonym użytkownikom uprawnień, takich jak możliwość przeglądania tabel, tworzenia zapytań lub uruchamiania jako administrator.
Wybrałem rolę użytkownika BigQuery, która pozwoli temu kontu usługi na przeglądanie i manipulowanie tabelami. Pole „Przyznaj użytkownikowi dostęp do tego konta usługi” zostanie pominięte. Kliknięcie Gotowe przeniesie Cię z powrotem do strony głównej konta usługi, gdzie możesz zobaczyć konto:

Przechodząc do drugiej części, utwórzmy klucz, który będzie powiązany z nowym kontem usługi. W polu Akcja kliknij Zarządzaj kluczami aby utworzyć klucz dla konta usługi — dodając własny klucz lub zlecając jego utworzenie.
Jeśli Google utworzy Twój klucz, przedstawi Ci dwie opcje typu klucza, JSON lub P12. Wybierz typ JSON, ponieważ ten klucz będzie również używany dla sterownika JDBC, który używa formatu JSON.
Po utworzeniu klucza JSON zostanie on pobrany na komputer. Możesz umieścić go w dowolnym miejscu, ale pamiętaj o ścieżce, ponieważ będzie ona używana podczas konfigurowania sterownika ODBC i JDBC.
Teraz, gdy konto usługi zostało utworzone i ma klucz, który będzie działał jako hasło, przejdźmy do pobrania połączenia ODBC i jego konfiguracji.
ODBC – pobieranie i konfiguracja
Używam systemu operacyjnego Windows i wybieram 64-bitową wersję Windows, aby była kompatybilna z plikiem wykonywalnym CoSort V10.5 SortCL. Po wykonaniu instrukcji i zaakceptowaniu umowy licencyjnej dla instalatora Simba otwórz Administratora źródeł danych ODBC (64-bitowy), aby skonfigurować połączenie.

Po prostu dodaj i poszukaj sterownika o nazwie „Simba ODBC Driver for Google BigQuery”.

Po wybraniu sterownika strona konfiguracji powinna wyglądać tak:

Tutaj konfiguracja jest naprawdę prosta, zaczynając od nazwy źródła danych.
Wybrałem nazwę Google BigQuery, ale możesz wybrać dowolną nazwę dla swojego przypadku użycia.
W celu uwierzytelnienia zachowaj domyślną opcję Konto usługi i przejdź w dół do poczty e-mail. Tutaj możesz skopiować i wkleić adres e-mail konta usługi, który został utworzony wcześniej w tym artykule.
Poniższe pole (Ścieżka pliku klucza) używa ścieżki do pliku klucza JSON jako danych wejściowych. Na dole, gdzie znajduje się Katalog (Projekt), kliknij menu rozwijane. Jeśli wszystko jest poprawnie skonfigurowane, powinno pokazywać nazwę projektu i węzła zawierającego zestawy danych i tabele.
Możesz zrobić to samo dla opcji Dataset, kliknij menu rozwijane, aby wybrać określony zestaw danych lub pozostaw to pole puste, aby wyświetlić wszystkie zestawy danych w tym projekcie. Na koniec przetestuj połączenie, aby upewnić się, że wszystko działa poprawnie.
Po skonfigurowaniu ODBC możemy skonfigurować sterownik JDBC.
JDBC – pobieranie i konfiguracja
Pobierz sterownik JDBC z CData tutaj. Po zakończeniu instalacji pojawi się folder o nazwie GoogleBigQueryJDBCDriver z setup.jar w środku.
Plik setup.jar zainstaluje wszystkie pliki potrzebne do działania połączenia JDBC. Zawiera również specjalny słoik, który pomaga w tworzeniu adresu URL połączenia dla sterownika JDBC.
Po zakończeniu instalacji setup.jar, musimy mieć gotowe konfiguracje w Workbenchu. W Eksploratorze źródeł danych (wewnątrz Workbencha) dodaj nowe połączenie, klikając Nowy profil połączenia .

Pojawi się wyskakujące okienko (jak na poniższym obrazku) i poda kilka opcji dotyczących typu połączeń, które można utworzyć. Wybierz Generic JDBC i nadaj mu nazwę, taką jak BigQuery, co ułatwi jego wykrycie w Eksploratorze źródeł danych.

Następna strona poprowadzi Cię do konfiguracji sterownika i podania szczegółów połączenia. Kliknij Definicja nowego sterownika który wygląda jak kompas z zielonym znakiem plus.

Na następnej stronie można w razie potrzeby nadać sterownikowi określoną nazwę. Przechodząc do zakładki Lista JAR, w tym miejscu dodawane są wymagane pliki jar, aby sterownik JDBC działał.
Jeśli podczas instalacji plików sterownika JDBC użyto lokalizacji domyślnej, powinna ona znajdować się w folderze Program Files o nazwie CData. Wewnątrz folderu lib znajduje się plik Jar o nazwie cdata.jdbc.googlebigquery.GoogleBigQueryDriver , dodaj ten słoik do listy i przejdź do zakładki Właściwości.
*Domyślna ścieżka jest widoczna na poniższym obrazku, jeśli wystąpią jakiekolwiek problemy ze znalezieniem pliku jar*

W zakładce Właściwości musimy utworzyć adres URL połączenia, nadać nazwę Bazie danych i określić Klasę sterownika. Skupiając się najpierw na utworzeniu adresu URL połączenia, w Eksploratorze plików znajdź właśnie dodany plik jar i wykonaj go.
Pomoże to utworzyć adres URL połączenia w formacie sugerowanym przez CData. Jak widać na poniższym obrazku, po lewej stronie znajdują się właściwości, które należy ustawić, aby utworzyć adres URL połączenia.

CData ma dokumentację dotyczącą tego, które właściwości należy ustawić w zależności od tego, jak użytkownik wybrał uwierzytelnianie. Ponieważ uwierzytelniamy się za pomocą konta usługi, właściwości, które należy ustawić, są wymienione poniżej.
- AuthScheme — Ustaw na OAuthJWT
- Identyfikator projektu – znajduje się na stronie głównej BigQuery
- InitiateOAuth – Ustaw na GETANDREFRESH
- OAuthJWTCertType – Ustaw na GOOGLEJSON
- OAuthJWTCert – ścieżka do pliku .json dostarczonego przez Google
Po ustawieniu wszystkich właściwości przetestuj połączenie, aby upewnić się, że wszystko działa. Jeśli się powiedzie, skopiuj parametry połączenia na dole. Jeśli wyjdziesz bez kopiowania adresu URL połączenia, będziesz musiał ponownie ustawić właściwości.
Wróć do Workbench, wklej adres URL obok właściwości Adres URL połączenia i dodaj nazwę bazy danych dla właściwości Nazwa bazy danych. Dla właściwości Driver Class znajduje się przycisk z trzema kropkami w pustym polu.
Kliknij go, a otrzymasz opcję wprowadzenia nazwy klasy sterownika lub zeskanowania listy JAR w poszukiwaniu sterownika. Gdy wszystko zostanie zrobione, powinno wyglądać podobnie do tego:

Kliknij OK i zostaniesz odesłany z powrotem do strony "Określ sterownik i szczegóły połączenia". Nie ma potrzeby dodawania nazwy użytkownika ani hasła, ponieważ wszystkie informacje znajdują się w adresie URL połączenia. Przetestuj połączenie po raz ostatni i kliknij Zakończ.
Profil połączenia będzie teraz widoczny w Eksploratorze źródeł danych, a schematy/tabele będą widoczne po kliknięciu profilu prawym przyciskiem myszy i wybraniu opcji Połącz.

Ostatnim zadaniem jest utworzenie rejestru połączeń danych, który mapuje DSN do właśnie utworzonego profilu połączenia. Przejdź do menu IRI, wybierz preferencje i zlokalizuj rejestr połączeń danych, jak sugeruje obrazek poniżej.

Po lewej stronie znajduje się DSN, a po prawej profile połączeń. Zlokalizuj DSN utworzone w powyższej sekcji ODBC i kliknij Edytuj…. Wybierz DSN, wersję i profil połączenia.

Ponieważ DSN ma poświadczenia zapisane w adresie URL połączenia, nie ma potrzeby uwierzytelniania za pomocą użytkownika/hasła. Kliknij OK oraz Zastosuj i zamknij aby wyjść z menu.
Wszystkie czynności związane z połączeniem z bazą danych dla Google BigQuery zostały zakończone. Jeśli potrzebujesz pomocy, wyślij e-mail na adres support@iri.com.