Prawdopodobnie wiesz, jak wstawiać rekordy do tabeli za pomocą jednej lub wielu klauzul VALUES. Wiesz również, jak wykonać wstawianie zbiorcze za pomocą SQL INSERT INTO SELECT. Ale nadal kliknąłeś artykuł. Czy chodzi o obsługę duplikatów?
Wiele artykułów dotyczy SQL INSERT INTO SELECT. Google lub Bing it i wybierz nagłówek, który najbardziej Ci się podoba – to wystarczy. Nie będę też omawiał podstawowych przykładów tego, jak to się robi. Zamiast tego zobaczysz przykłady, jak z niego korzystać ORAZ jednocześnie obsługiwać duplikaty . Tak więc możesz wykorzystać tę znajomą wiadomość ze swoich wysiłków INSERT:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Ale najpierw najważniejsze.

[sendpulse-form id=”12989″]
Przygotuj dane testowe dla SQL INSERT INTO SELECT Próbki kodu
Tym razem myślę o makaronie. Wykorzystam więc dane o daniach z makaronu. Znalazłem dobrą listę dań z makaronu w Wikipedii, które możemy wykorzystać i wyodrębnić w Power BI za pomocą internetowego źródła danych. Wpisałem adres URL Wikipedii. Następnie określiłem dane 2-tabelowe ze strony. Posprzątałem trochę i skopiowałem dane do Excela.
Teraz mamy dane – możesz je pobrać stąd. Jest surowy, ponieważ zrobimy z niego 2 tabele relacyjne. Użycie INSERT INTO SELECT pomoże nam wykonać to zadanie,
Importuj dane do serwera SQL
Możesz użyć SQL Server Management Studio lub dbForge Studio dla SQL Server, aby zaimportować 2 arkusze do pliku Excel.
Utwórz pustą bazę danych przed zaimportowaniem danych. Nazwałem tabele dbo.Italian PastaDishes i dbo.Niewłoskie dania z makaronem .
Utwórz 2 kolejne stoły
Zdefiniujmy dwie tabele wyjściowe za pomocą polecenia SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Uwaga:Na dwóch tabelach tworzone są unikalne indeksy. Uniemożliwi nam to późniejsze wstawianie zduplikowanych rekordów. Ograniczenia sprawią, że ta podróż będzie nieco trudniejsza, ale ekscytująca.
Teraz, gdy jesteśmy gotowi, zanurkujmy.
5 łatwych sposobów obsługi duplikatów za pomocą SQL INSERT INTO SELECT
Najłatwiejszym sposobem obsługi duplikatów jest usunięcie unikalnych ograniczeń, prawda?
Źle!
Gdy znikną unikalne ograniczenia, łatwo popełnić błąd i wstawić dane dwa lub więcej razy. Nie chcemy tego. A co jeśli mamy interfejs użytkownika z rozwijaną listą do wyboru pochodzenia dania makaronowego? Czy duplikaty uszczęśliwią Twoich użytkowników?
Dlatego usunięcie ograniczeń przez unikalność nie jest jednym z pięciu sposobów obsługi lub usuwania zduplikowanych rekordów w SQL. Mamy lepsze opcje.
1. Używanie INSERT IN TO SELECT DISTINCT
Pierwszą opcją identyfikacji rekordów SQL w SQL jest użycie DISTINCT w SELECT. Aby zbadać sprawę, wypełnimy Pochodzenie stół. Ale najpierw użyjmy niewłaściwej metody:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Spowoduje to następujące zduplikowane błędy:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Podczas próby wybrania zduplikowanych wierszy w SQL pojawia się problem. Aby rozpocząć sprawdzanie SQL pod kątem duplikatów, które istniały wcześniej, uruchomiłem część SELECT instrukcji INSERT INTO SELECT:
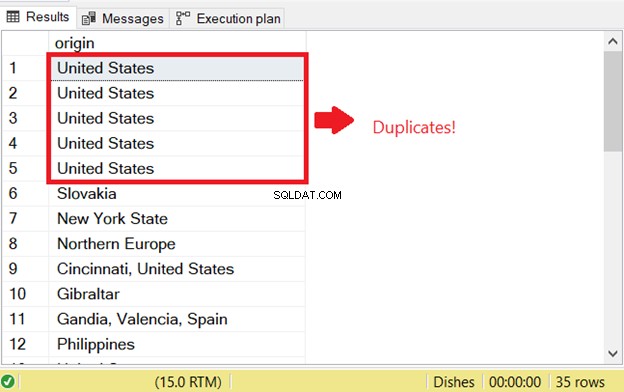
To jest powód pierwszego błędu duplikacji SQL. Aby temu zapobiec, dodaj słowo kluczowe DISTINCT, aby zestaw wyników był unikalny. Oto poprawny kod:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Pomyślnie wstawia rekordy. I skończyliśmy z Pochodzeniem tabela.
Użycie DISTINCT utworzy unikalne rekordy z instrukcji SELECT. Nie gwarantuje to jednak, że w tabeli docelowej nie ma duplikatów. Dobrze jest, gdy masz pewność, że tabela docelowa nie zawiera wartości, które chcesz wstawić.
Dlatego nie uruchamiaj tych instrukcji więcej niż raz.
2. Korzystanie GDZIE NIE W
Następnie wypełniamy PastaDishes stół. W tym celu musimy najpierw wstawić rekordy z ItalianPastaDishes stół. Oto kod:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Od włoskich dań z makaronem zawiera surowe dane, musimy dołączyć do Pochodzenia tekst zamiast Identyfikatora pochodzenia . Teraz spróbuj dwukrotnie uruchomić ten sam kod. Drugie uruchomienie nie będzie miało wstawionych rekordów. Dzieje się tak z powodu klauzuli WHERE z operatorem NOT IN. Odfiltrowuje rekordy, które już istnieją w tabeli docelowej.
Następnie musimy wypełnić Dishy z makaronem tabela z NonItalian PastaDishes stół. Ponieważ jesteśmy dopiero w drugim punkcie tego postu, nie wstawimy wszystkiego.
Wybraliśmy dania z makaronu ze Stanów Zjednoczonych i Filipin. Oto idzie:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Z tego oświadczenia wstawiono 9 rekordów – patrz Rysunek 2 poniżej:
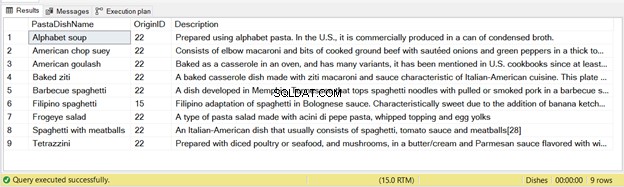
Ponownie, jeśli uruchomisz powyższy kod dwa razy, drugi przebieg nie będzie zawierał rekordów.
3. Korzystanie GDZIE NIE ISTNIEJE
Innym sposobem na znalezienie duplikatów w SQL jest użycie NOT EXISTS w klauzuli WHERE. Wypróbujmy to z tymi samymi warunkami z poprzedniej sekcji:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
Powyższy kod wstawi te same 9 rekordów, które widziałeś na Rysunku 2. Pozwoli to uniknąć wstawiania tych samych rekordów więcej niż raz.
4. Używanie JEŚLI NIE ISTNIEJE
Czasami może być konieczne wdrożenie tabeli do bazy danych i konieczne jest sprawdzenie, czy tabela o tej samej nazwie już istnieje, aby uniknąć duplikatów. W takim przypadku bardzo pomocne może być polecenie SQL DROP TABLE IF EXISTS. Innym sposobem na zapewnienie, że nie wstawisz duplikatów, jest użycie opcji JEŚLI NIE ISTNIEJE. Ponownie użyjemy tych samych warunków z poprzedniej sekcji:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Powyższy kod najpierw sprawdzi, czy istnieje 9 rekordów. Jeśli zwróci true, INSERT będzie kontynuowane.
5. Używając LICZBA(*) =0
Wreszcie, użycie COUNT(*) w klauzuli WHERE może również zapewnić, że nie wstawisz duplikatów. Oto przykład:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Aby uniknąć duplikatów, LICZBA lub rekordy zwrócone przez powyższe podzapytanie powinno wynosić zero.
Uwaga :Możesz zaprojektować dowolne zapytanie wizualnie na diagramie za pomocą funkcji Query Builder w dbForge Studio dla SQL Server.
Porównanie różnych sposobów obsługi duplikatów za pomocą SQL INSERT INTO SELECT
4 sekcje wykorzystywały te same dane wyjściowe, ale różne podejścia do wstawiania rekordów zbiorczych za pomocą instrukcji SELECT. Możesz się zastanawiać, czy różnica jest tylko powierzchowna. Możemy sprawdzić ich logiczne odczyty w STATISTICS IO, aby zobaczyć, jak bardzo się różnią.
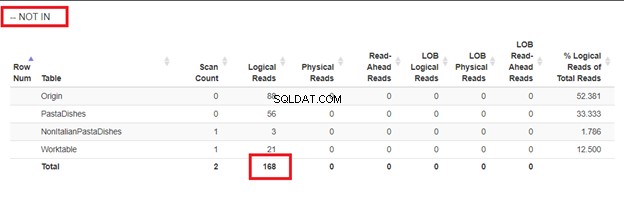
Używając GDZIE NIE W:
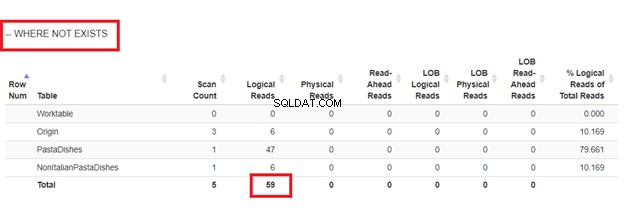
Korzystanie NIE ISTNIEJE:
Korzystanie z opcji JEŚLI NIE ISTNIEJE:
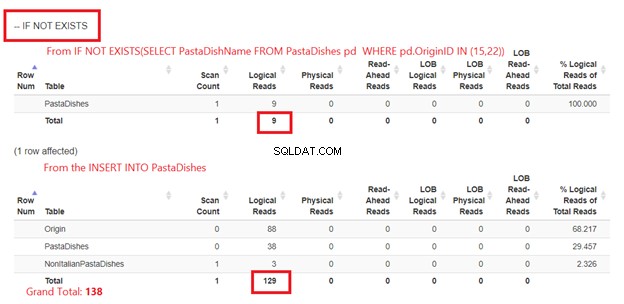
Rysunek 5 jest nieco inny. Pojawiają się 2 logiczne odczyty dla PastaDishes stół. Pierwszy z nich pochodzi z IF NOT EXISTS(SELECT Nazwa dania makaronu z Dania Makaronu GDZIE Identyfikator pochodzenia W (15,22)). Drugi pochodzi z instrukcji INSERT.
Wreszcie, używając COUNT(*) =0
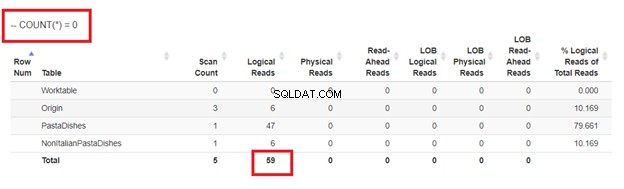
Z logicznych odczytów 4 podejść, które mieliśmy, najlepszym wyborem jest WHERE NOT EXISTS lub COUNT(*) =0. Kiedy sprawdzamy ich plany wykonania, widzimy, że mają ten sam QueryHashPlan . Mają więc podobne plany. Tymczasem najmniej wydajnym jest używanie NOT IN.
Czy to znaczy, że WHERE NOT EXISTS jest zawsze lepsze niż NOT IN? Wcale nie.
Zawsze sprawdzaj odczyty logiczne i plan wykonania swoich zapytań!
Ale zanim zakończymy, musimy dokończyć zadanie. Następnie wstawimy pozostałe rekordy i sprawdzimy wyniki.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Przeglądanie listy 179 dań makaronowych od Azji do Europy sprawia, że odczuwam głód. Sprawdź poniżej część listy z Włoch, Rosji i nie tylko:

Wniosek
Unikanie duplikatów w SQL INSERT INTO SELECT nie jest przecież takie trudne. Masz pod ręką operatorów i funkcje, które przeniosą Cię na ten poziom. Dobrym nawykiem jest również sprawdzanie planu wykonania i odczytów logicznych w celu porównania, który jest lepszy.
Jeśli uważasz, że ktoś inny skorzysta na tym wpisie, udostępnij go na swoich ulubionych platformach społecznościowych. A jeśli masz coś do dodania, o czym zapomnieliśmy, daj nam znać w sekcji Komentarze poniżej.



